Awesome
Hadoop implementation of the Pooled Time Series (PoT) algorithm
PoT java implementation using Apache Hadoop.
Dependencies
- Maven (Version shouldn't matter much. Tested with 2.x and 3.x.)
- OpenCV 2.4.x (Tested with 2.4.9 and 2.4.11)
Pre-requisites
If you get any errors running brew install opencv related to numpy, please run:
pip install numpy
Now move on to OpenCV (More detailed instructions in wiki/Installing-opencv)
brew install opencv --with-java
The above should leave you with a:
/usr/local/Cellar/opencv/<VERSION>/share/OpenCV/java
Directory which contains the associated dylib OpenCV dynamic library along with the OpenCV jar file.
Getting started
cd hadoop-pot-assemblymvn install assembly:assembly- Set OPENCV_JAVA_HOME, e.g., to
export OPENCV_JAVA_HOME=/usr/local/Cellar/opencv/2.4.9/share/OpenCV/java - Set POOLED_TIME_SERIES_HOME, e.g., to
export POOLED_TIME_SERIES_HOME=$HOME/hadoop-pot/src/main - Run
pooled-time-series, e.g., by creating an alias,alias pooled-time-series="$POOLED_TIME_SERIES_HOME/bin/pooled-time-series"
The above should produce:
usage: pooled_time_series
-d,--dir <directory> A directory with image files in it
-f,--file <file> Path to a single file
-h,--help Print this message.
-j,--json Set similarity output format to JSON.
Defaults to .txt
-o,--outputfile <output file> File containing similarity results.
Defaults to ./similarity.txt
-p,--pathfile <path file> A file containing full absolute paths to
videos. Previous default was
memex-index_temp.txt
So, to call the code e.g., on a directory of files called data, you would run (e.g., with OpenCV 2.4.9):
pooled-times-series -d data
Alternatively you can create (independently of this tool) a file with absolute file paths to video files, 1 per line, and then pass it with the -p file to the above program.
Running Hadoop Jobs
Config and Getting Started
Add the following to your .bashrc
export HADOOP_OPTS="-Djava.library.path=<path to OpenCV jar> -Dmapred.map.child.java.opts=-Djava.library.path=<path to OpenCV jar>"
alias pooled-time-series-hadoop="$POOLED_TIME_SERIES_HOME/bin/pooled-time-series-hadoop"
Build and clean up the jar for running
# Compile everything
mvn install assembly:assembly
# Drop the LICENSE file from our jar that will give us headaches otherwise
zip -d target/pooled-time-series-1.0-SNAPSHOT-jar-with-dependencies.jar META-INF/LICENSE
Documentation moving to the wiki
We are moving our documentation to the wiki. Please bear with us and report issues as you find them.
Research Background and Detail
This is a source code used in the following conference paper [1]. It includes the pooled time series (PoT) representation framework as well as basic per-frame descriptor extractions including histogram of optical flows (HOF) and histogram of oriented gradients (HOG). For more detailed information on the approach, please check the paper.
If you take advantage of this code for any academic purpose, please do cite:
[1] Mattmann, Chris A., and Madhav Sharan. "Scalable Hadoop-Based Pooled Time Series of Big Video Data from the Deep Web." Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval. ACM, 2017.
[2] M. S. Ryoo, B. Rothrock, and L. Matthies, "Pooled Motion Features for First-Person Videos", IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015.
https://arxiv.org/abs/1610.06669
http://arxiv.org/pdf/1412.6505v2.pdf
@inproceedings{mattmann2017scalable,
title={Scalable Hadoop-Based Pooled Time Series of Big Video Data from the Deep Web},
author={Mattmann, Chris A and Sharan, Madhav},
booktitle={Proceedings of the 2017 ACM on International Conference on Multimedia Retrieval},
pages={117--120},
year={2017},
organization={ACM}
}
@inproceedings{ryoo2015pot,
title={Pooled Motion Features for First-Person Videos},
author={M. S. Ryoo and B. Rothrock and L. Matthies},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2015},
month={June},
address={Boston, MA},
}
Evaluation
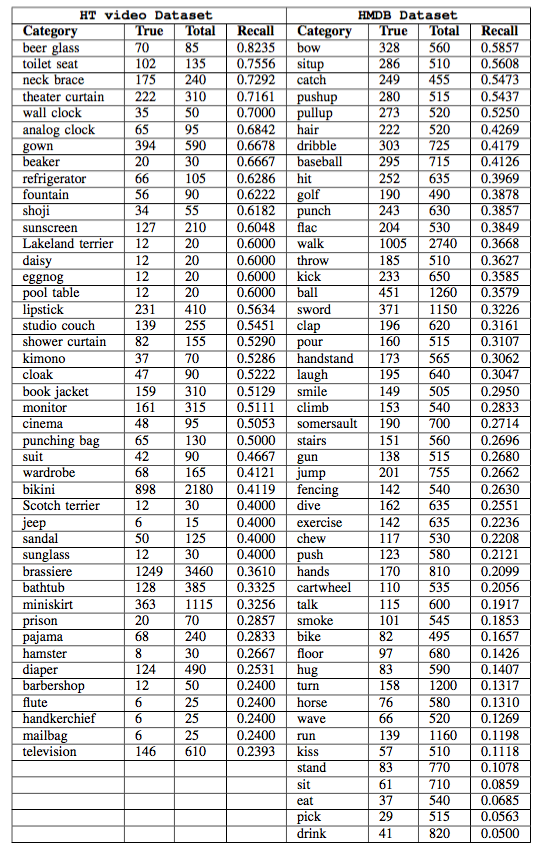
HMDB Dataset - http://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/