Awesome
github上排版可能有些问题,也可以访问我的博客https://blog.csdn.net/weixin_42907473/article/details/103470208
一、简述
队名:学学没完
队伍成绩:
初赛榜 0.85245 排名第一 (a榜第二,b榜重回第一)
决赛榜 0.9307 排名第二 (第一老哥很猛,搞得我们很慌,硬是肝了一晚上才拉近了和他们的差距)
受益于官方对大家前三个月工作的肯定,初赛的权重是复赛的两倍,因此最后加权总榜第一。
二、比赛方案
1.初赛回顾
初赛赛题是对一组唇语图片序列进行中文单词的预测,给定的数据集是封闭集(类别数量是一定的,测试集中的类别均在训练集中出现过),如下图所示:<div align=center>

上图一共有5组唇语序列,代表着不同的中文词语。<div align=left>
2.数据分析
拿到数据,我们先简单的对数据进行了分析:
- 训练数据数量一共9996个样本,测试数据一共2504个样本,总的类别是313类。
- 词语中只有两字词和四字词,样本比例为6816:3180,在313个类中的类别比例为213:100
- 313类中有311个类别有32个样本,只有“落地生根”和“卓有成效”两个样本有22个样本,可以说样本非常均衡。
- 样本的图片数量,除了异常数据外,基本分布在2张到24张之间,且两字词和四字词的图片数量有大量重叠,这意味着这一维信息很难利用,在测试集中的图片数量也基本和训练集一致。<div align=center>

两字词和四字词图片数量对比<div align=center>

训练集和测试集样本图片数量对比<div align=left>
数据分析让我们对数据有了一个整体的把握。除此以外,我们还观察了一些样本数据,发现了他们采集的样本中,包含说话的有用信息图片大都集中在前半序列中,而最后几张往往都是闭嘴状态,没有提供任何有用的信息。
3.数据清洗以及数据切割问题
- 通过对数据的分析,我们对低于两张的异常样本数据进行了清除。
- 考虑到很多样本中的嘴唇并不是一直在一个位置,因此考虑是否要定位和切割一下嘴唇部位。
因此我们手动标注了七八百张图片图片送进了CornerNet_Lite网络中去训练一个检测嘴唇的网络。
Why CornerNet_Lite?
其实其他的也可以,如Yolov3,毕竟任务简单,但是这篇论文号称吊打Yolov3,且我前一段时间也跑过这个网络,所以就拿来用了,下图即为文章中的性能对比图,由于没有速度的要求,我们最终采用的是Cornernet-Saccade版本。<div align=center>
 <div align=left>
<div align=left>
切割效果基本完美,我们切割原则是:1.保证嘴巴在图片正中央;2、保持一组图片切割大小一样,且嘴唇不能占满全图。 在切割的时候我们也发现一些图片没有检测到嘴唇,结果发现样本序列中夹杂了一些噪声数据,我们将这些进行了去除,大致如下图所示:<div align=center><img src="https://img-blog.csdnimg.cn/20191210153204766.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MjkwNzQ3Mw==,size_16,color_FFFFFF,t_70" width =50% height = 50%><div align=left>
我们当时的切割程序写了一些BUG,导致没有贯彻思想,最终直接测试的结果并没有不切割的好。当时也没发现这个问题,所以初赛并没有用到切割图片,但是我也对标注的图片中嘴唇边界离图片边界的信息进行了统计,最后大致对图片做了一个统一的切割或者说限制区域的操作。
4.模型选择
通过对数据的分析,且考虑到任务是多分类问题,无需考虑词与词之间的关系,所以我们将这个问题简单的看作动作视频多分类的问题,因此我们尝试了多种类别的 SOTA 模型。
1)基于3D 卷积模型
3D 卷积模型是我们首先想到和尝试的,3D 模型的代表之一是《ECO: Efficient convolutional Network For online video understanding》,这篇文章是去年 ECCV 的文章,模型结构如下:<div align=center> <div align=left>
S1 到 SN 是从视频中采样的 N 个帧图像。
<div align=left>
S1 到 SN 是从视频中采样的 N 个帧图像。
- 对于每个帧图像,采用共享的 2D 卷积子网络 来得到 96 个 28*28 大小的 feature map,堆叠后得到一个 N*28*28*96 大小的特征 volume。此处使用的是 BN-Inception 网络中的第一部分(到 inception-3c 层前)。
- 对于得到的特征 volume,采用一个 3D 子网络进行处理,直接输出对应动作类别数目的一维向量。此处采用了 3D-Resnet18 中的部分层。 如上的两部分,就构建了这篇文章中构建的第一种网络结果 ECO-Lite。除了用 3D 卷积进行融合,还可以同时使用 2D 卷积,如下图所示,即为 ECO-Full 网 络 结 构 。 此 处 多 的 一 个 2D 网 络 分支 采 用 的 是 BN-Inception 网 络 中 inception-4a 到最后一个 pooling 层间的部分,最后再采用 average-pooling 得到 video-level 的表示,与 3D net 的结果 concat 后再得到最后的 action 分类结果。 <div align=center>
 <div align=left>
<div align=left>
这个模型的效果也不错,我们队伍前期霸榜就是依靠这个模型,ECO-lite 最高 0.74 多,ECO-Full 最高 0.76 多,之后我们又尝试了其他一些模型,如今年的CVPR 何凯明实验室的文章《SlowFast Networks for Video Recognition》,但是该网络需要高低帧率间配合才能有更好的效果,而我们这个数据毕竟不是视频,帧数实在有限,最终跑出来效果不尽如人意,但如果有高帧率的视频,我想应该会有不错的效果。
篇外探讨: 关于《SlowFast Networks for Video Recognition》这篇文章中提出的一个观点我觉的值得我们去思考,大致意思: 我们对于一张图片,我们可以简单的将其分为两个维度来看待,I(x,y) 。似乎很合理,x与 y方向的重要性似乎是相等的。然而对于一个视频,引入了时间维度t ,I(x,y,t) 。但这个t与 x,y可以同等看待吗,显然不是的啊,现实这个世界中,大多数的物体都是静止的。而我们传统的卷积如 3D卷积却是同等对待的,按照作者的理解,这是不合理的。既然不合理,就需要将时间t与空间(x,y)单独的处理。
值得一提的是,今年这个领域几篇顶会如SlowFast、STM、TSM都是基于2D卷积模型来做的,只是提取时序的结构不一样,且达到了超越3D卷积的效果,所以是否可以推想:对于时序特征的提取,最好还是不要将时序信息与图片的长宽维度等同看待,而是加以区别来提取,设计更好的时序提取结构来获得一个更好的效果才是上上策呢?
2)基于2D 卷积模型 2D 卷积模型由于其轻量的结构和多元的 backbone 选择,使得其在云端计算和边缘部署上相对 3D 卷积模型具有巨大的优势,但 2D 卷积模型因为时序上的关系很难利用好,各种加如 lstm 等结构的网络还是被 3D 卷积实力碾压,通常情况下如果只考虑精度则不考虑 2D 卷积模型 。 但是如果一个模型只使用 2D 卷积,且在分类精度上仍然能达到 SOTA,那么其带来的实用价值是巨大的,是碾压一切 3D 模型的存在。 而今年 ICCV 上的这篇文章《TSM: Temporal Shift Module for Efficient Video Understanding》提出的 Temporal Shift Module 这个模块很好的利用了帧间的时序关系,实现了 3D 卷积的性能且保持了 2D 卷积的相对较小的计算量。并且截至它的发行日,它在注重动作的数据集 Something-Something 排行榜上排名第一,这也更加符合我们的需求。 我们最终采用的模型也正是2D卷积网络+TSM模块的结构,期间我们也尝试了加Non_Local,但是效果并没有提升,反而是模型变得沉重,推断变慢。
TSM原理:
TSM在时间维度上移动了部分通道,从而促进相邻帧在信息之间的交流。而这一操作插入到2D卷积中又基本算是实现了在零计算量的情况下对时间轴的信息建模。 <div align=center> <div align=left>
<div align=left>
如上图所示TSM模块通过沿时间维度移动特征图来执行有效的时间建模,图a是原始的tensor,图b是离线模式所适用的双向TSM将过去和未来的帧和当前帧混合,而图c是在线模式,实时识别,由于不能获取到未来的帧信息,所以仅用过去的帧和当前的帧混合在一起。我们最终采用的是图b的方式。 可以看到,仅仅是对部分通道进行了移位,几乎没有额外的其他操作(也意味着没有额外的计算消耗,且没有多余的参数)。 更多关于TSM的内容,有兴趣的可以去看一下原论文,我也写了一篇大致翻译的博客,不想看英文原文的可以简单看一下这个。
5.数据预处理、数据增广
视频分类网络通常输入的数据并不是整个视频,而是从视频中截取的一些帧图像,按照其时序关系送入模型。而截取的原则一般是按照一定的帧率均匀采样,亦或者先均匀将视频分成几个片段,然后从每个片段中随机选一帧图像,以此来增强模型的泛化能力,同时减小计算量。
而我们的唇语数据集是已经截取好的图片,数量从2张(0或1张视为噪声数据去除)到24张不等,模型输入的图片数量是一定的,所以模型输入采用多少帧和缺少的帧图像如何填充都是一个问题。
本着不丢失信息和尽可能小的模型输入原则,我们选择了24帧作为模型的统一输入。至于模型的插帧,内容上我们是复制前一帧的图像来填充,而插帧方法上我们采用了尽可能在前几张图像多插帧的原则,这样就等效为放慢了前几张图像带来的信息,这样做的原因是通过观察数据,我们发现最后几张图像采集者往往是闭嘴状态并不提供任何信息,所以预测时的插帧公式如下: <div align=center>
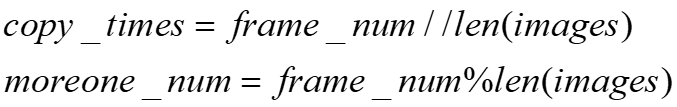 <div align=left>
<div align=left>
copy_times代表所有图片至少复制的次数,frame_num代表模型输入的帧数,这里我们设定的是24帧,len(images)代表的是样本中原始图片的数量,moreone_num代表的是需要多复制一遍的图片数量。预测时,我们直接将前moreone_num张图片多复制一次,以达到24帧的输入。
而对于训练过程,我们考虑到采集者说话可能在每个字上的时间并不相同,为了提高模型的鲁棒性,我们并没有采用固定位置多复制一次的方法,而是随机选择一个起始点进行多复制一次操作。
除此之外,我们还加入了随机丢帧的处理,具体做法是对样本图像数量大于一定值(如12)的样本进行随机丢帧,当然帧数小于2且不能为连续帧。另外还加入了图片随机移动,让一组嘴巴并不在一个位置,来增强模型的泛化能力。
对于数据增广,我们还采用了一些常规的增广方式:随机加入高斯噪声,随机对图像做双边滤波,随机调图像的明暗度、对比度、饱和度、色度,随机对图像加入小旋转(5°以内),随机对图像做上下左右小平移,随机水平反转操作。这些数据增广操作都是在不损失模型的关键信息的原则上,去告诉模型它应该关注的信息是什么,以此来增强模型的泛化能力。
初赛最终方案:
 <div align=left>
<div align=left>
决赛篇简述:
决赛由于数据由中文单词变成了数字组合,且数据量极少,所以我们也尝试过将1000类问题转化为10类去做,由于策略不佳最终的准确率却只有八十多,所以还是用的初赛方案,将其视作1000类分类问题,也取得了不错的效果。
决赛最终方案:
 <div align=left>
<div align=left>
题外话: 比赛的时候我们对预测出来的答案就做了分析,发现1,4,7包含这些数字的样本相对于其他就很少,我们猜测可能官方为了让准确率变得更好看,所以刻意将难分的数据去掉了一些。事后我们问了出题的小哥,事实确实如此。 记得当时决赛那天第一支上传成绩的队伍,直接八十多,而我们线下验证集才六十多,心态都炸了,还以为成都旅游来了。结果最后发现是测试集变简单了。
附一张比赛成绩实时榜,不得不说,官方做的很用心
 <div align=left>
<div align=left>
总结
很开心也很荣幸能够获得这次比赛的冠军,但是说起来也有些惭愧,只是跨领域的做了一下做了一些尝试,没有理论性的创新,可能我们是属于运气比较好的那一支队伍吧,答辩中看到其他队伍的一些工作也很棒,非常希望其他队伍的大佬能开源方便我们学习一波。最后感谢一下主办方和协办单位的工作人员,他们非常辛苦,同时也感谢我的两个队友,没有他们也没有这个冠军奖杯。欢迎交流!