Awesome
M*LIB: Generic type-safe Container Library for C language
- Overview
- Components
- Build & Installation
- How to use
- Performance
- OPLIST
- Memory Allocation
- Emplace construction
- Errors & compilers
- External Reference
- API Documentation
- Generic methods
- List
- Array
- Deque
- Dictionary
- Tuple
- Variant
- Red/Black Tree
- B+ Tree
- Generic Tree
- Priority queue
- Fixed buffer queue
- Atomic Shared Register
- Shared pointers
- Intrusive Shared Pointers
- Intrusive list
- Concurrent adapter
- Bitset
- String
- Core preprocessing
- Thread
- Worker threads
- Atomic
- Generic algorithms
- Function objects
- Exception handling
- Memory pool
- JSON Serialization
- Binary Serialization
- Generic interface
- Byte String
- Global User Customization
- License
Overview
M*LIB (M star lib) is a C library enabling to define and to use generic and
type safe container in C, aka handling generic
containers in pure C language.
The encapsulated objects can have their own constructor, destructor, operators
or can be basic C type like the C type 'int': both are fully supported.
This makes it possible to construct fully
recursive container objects (container-of[...]-container-of-type-T)
while keeping compile time type checking.
This is an equivalent of the C++ Standard Library, providing vector, deque, forward_list, set, map, multiset, multimap, unordered_set, unordered_map, stack, queue, shared_ptr, string, variant, option to standard ISO C99 / C11. There is not a strict mapping as both the STL and M*LIB have their exclusive containers:
See here for details. M*LIB provides also additional concurrent containers to design properly multi-threaded programs: shared register, communication queue, ...
M*LIB is portable to any systems that support ISO C99. Some optional features need at least ISO C11.
M*LIB is only composed of a set of headers. There is no C file, and as such, the installation is quite simple: you just have to put the header in the search path of your compiler, and it will work. There is no dependency (except some other headers of M*LIB and the LIBC).
One of M*LIB design key is to ensure safety. This is done by multiple means:
- in debug mode, defensive programming is extensively used: the contracts of the function are checked, ensuring that the data are not corrupted. For example, strict Buffer overflow are checked in this mode through bound checking or the intrinsic properties of a Red-Black tree (for example) are verified. Buffer overflow checks can still be kept in release mode if needed.
- as few cast as possible are used within the library (casts are the evil of safety). Still the library can be used with the greatest level of warnings by a C compiler without any aliasing warning.
- the genericity is not done directly by macro (which usually prevent type safety), but indirectly by making them define inline functions with the proper prototypes: this enables the user calls to have proper error and warning checks.
- extensive testing: the library is tested on the main targets using Continuous Integration with a coverage of the test suite of more than 99%. The test suite itself is run through the multiple sanitizers defined by GCC/CLANG (Address, undefined, leak, thread). The test suite also includes a comparison of equivalent behaviors of M*LIB with the C++ STL using random testing or fuzzer testing.
- static analysis: multiple static analyzer (like scan-build or GCC fanalyzer or CodeQL) are run on the generated code, and the results analyzed.
Other key designs are:
- do not rewrite the C library and just wrap around it (for example don't rewrite sort but stable sort),
- do not make users pay the cost of what they don't need.
Due to the unfortunate weak nature of the C language for pointers, type safe means that at least a warning is generated by the compiler in case of wrong type passed as container arguments to the functions.
M*LIB is still quite-efficient: there is no overhead in using this library rather than using direct C low-level access as the compiler is able to fully optimize the library usage and the library is carefully designed. In fact, M*LIB is one of the fastest generic C/C++ library you can find.
M*LIB uses internally the malloc, realloc and free functions to handle
the memory pool. This behavior can be overridden at different level.
Its default policy is to abort the program if there is a memory error.
However, this behavior can also be customized globally.
M*LIB supports also the exception error model by providing its own implementation of the try / catch mechanism.
This mechanism is compatible with RAII programming:
when an exception is thrown, the destructors of the constructed objects are called (See m-try for more details).
M*LIB may use a lot of assertions in its implementation to ensure safety:
it is highly recommended to properly define NDEBUG for released programs.
M*LIB provides automatically several serialization methods for each containers. You can read or write your full and complex data structure into JSON format in a few lines.
M*LIB is distributed under BSD-2 simplified license.
It is strongly advised not to read the source to know how to use the library as the code is quite complex and uses a lot of tricks but rather read the examples.
In this documentation,
- shall will be used to indicate a user constraint that is mandatory to follow under penalty of undefined behavior.
- should will be used to indicate a recommendation to the user.
All pointers expected by the functions of the library shall expect non-null argument except if indicated.
Components
The following headers define containers that don't require the user structure to be modified:
- m-array.h: header for creating dynamic array of generic type,
- m-list.h: header for creating singly-linked list of generic type,
- m-deque.h: header for creating dynamic double-ended queue of generic type,
- m-dict.h: header for creating unordered associative array (through hashmap) or unordered set of generic type,
- m-rbtree.h: header for creating ordered set (through Red/Black binary sorted tree) of generic type,
- m-bptree.h: header for creating ordered map/set/multimap/multiset (through sorted B+TREE) of generic type,
- m-tree.h: header for creating arbitrary tree of generic type,
- m-tuple.h: header for creating arbitrary tuple of generic types,
- m-variant.h: header for creating arbitrary variant of generic type,
- m-prioqueue.h: header for creating dynamic priority queue of generic type.
The available containers of M*LIB for thread synchronization are in the following headers:
- m-buffer.h: header for creating fixed-size queue (or stack) of generic type (multiple producer / multiple consumer),
- m-snapshot: header for creating 'atomic buffer' (through triple buffer) for sharing synchronously big data (thread safe),
- m-shared.h: header for creating shared pointer of generic type,
- m-concurrent.h: header for transforming a container into a concurrent container (thread safe),
- m-c-mempool.h: WIP header for creating fast concurrent memory allocation.
The following containers are intrusive (You need to modify your structure to add fields needed by the container) and are defined in:
- m-i-list.h: header for creating doubly-linked intrusive list of generic type,
- m-i-shared.h: header for creating intrusive shared pointer of generic type (Thread Safe).
Other headers offering other functionality are:
- m-string.h: header for creating dynamic string of characters (UTF-8 support),
- m-bstring.h: header for creating dynamic string of BYTE,
- m-bitset.h: header for creating dynamic bitset (or "packed array of bool"),
- m-algo.h: header for providing various generic algorithms to the previous containers,
- m-funcobj.h: header for creating function object (used by algorithm generation),
- m-try.h: header for handling errors by throwing exceptions,
- m-mempool.h: header for creating specialized & fast memory allocator,
- m-worker.h: header for providing an easy pool of workers on separated threads to handle work orders (used for parallel tasks),
- m-serial-json.h: header for importing / exporting the containers in JSON format,
- m-serial-bin.h: header for importing / exporting the containers in an adhoc fast binary format,
- m-generic.h: header for using a common interface for all registered types,
- m-genint.h: internal header for generating unique integers in a concurrent context,
- m-core.h: header for meta-programming with the C preprocessor (used by all other headers).
Finally, headers for compatibility with non C11 compilers:
- m-atomic.h: header for ensuring compatibility between C's
stdatomic.hand C++'s atomic header (provide also its own implementation if nothing is available), - m-thread.h: header for providing a very thin layer across multiple implementation of mutex/threads (C11/PTHREAD/WIN32).
Each containers define their iterators (if it is meaningful).
All containers try to expose the same common interface: if the method name is the same, then it does the same thing and is used in the same way. In some rare case, the method is adapted to the container needs.
Each header can be used separately from others: dependency between headers have been kept to the minimum.

Build & Installation
M*LIB is only composed of a set of headers, as such there is no build for the library. The library doesn't depend on any other library than the LIBC.
To run the test suite, run:
make check
You can also override the compiler CC or its flags CFLAGS if needed:
make check CC="gcc" CFLAGS="-O3"
To generate the documentation, run:
make doc
To install the headers, run:
make install PREFIX=/my/directory/where/to/install [DESTDIR=...]
Other targets exist. Mainly for development purpose.
How to use
To use these data structures, you first include the desired header,
instantiate the definition of the structure and its associated methods
by using a macro _DEF for the needed container.
Then you use the defined types and functions. Let's see a first simple example
that creates a list of unsigned int:
#include <stdio.h>
#include "m-list.h"
LIST_DEF(list_uint, unsigned int) /* Define struct list_uint_t and its methods */
int main(void) {
list_uint_t list ; /* list_uint_t has been define above */
list_uint_init(list); /* All type needs to be initialized */
list_uint_push_back(list, 42); /* Push 42 in the list */
list_uint_push_back(list, 17); /* Push 17 in the list */
list_uint_it_t it; /* Define an iterator to scan each one */
for(list_uint_it(it, list) /* Start iterator on first element */
; !list_uint_end_p(it) /* Until the end is not reached */
; list_uint_next(it)) { /* Set the iterator to the next element*/
printf("%d\n", /* Get a reference to the underlying */
*list_uint_cref(it)); /* data and print it */
}
list_uint_clear(list); /* Clear all the list (destroying the object list)*/
}
[!NOTE] Do not forget to add
-std=c99(or c11) to your compile command to request a C99 compatible build
This looks like a typical C program except the line with LIST_DEF
that doesn't have any semi-colon at the end. And in fact, except
this line, everything is typical C program and even macro free!
The only macro is in fact LIST_DEF: this macro expands to the
good type for the list of the defined type and to all the necessary
functions needed to handle such type. It is heavily context dependent
and can generate different code depending on it.
You can use it as many times as needed to defined as many lists as you want.
The first argument of the macro is the name to use, e.g. the prefix that
is added to all generated functions and types.
The second argument of the macro is the type to embed within the container.
It can be any C type.
The third argument of the macro is optional and is the oplist to use.
See below for more information.
You could replace LIST_DEF by ARRAY_DEF to change
the kind of container (an array instead of a linked list)
without changing the code below: the generated interface
of a list or of an array is very similar.
Yet the performance remains the same as hand-written code
for both the list variant and the array variant.
This is equivalent to this C++ program using the STL:
#include <iostream>
#include <list>
typedef std::list<unsigned int> list_uint_t;
typedef std::list<unsigned int>::iterator list_uint_it_t;
int main(void) {
list_uint_t list ; /* list_uint_t has been define above */
list.push_back(42); /* Push 42 in the list */
list.push_back(17); /* Push 17 in the list */
for(list_uint_it_t it = list.begin() /* Iterator is first element*/
; it != list.end() /* Until the end is not reached */
; ++it) { /* Set the iterator to the next element*/
std::cout << *it << '\n'; /* Print the underlying data */
}
}
As you can see, this is rather equivalent with the following remarks:
- M*LIB requires an explicit definition of the instance of the list,
- M*LIB code is more verbose in the method name,
- M*LIB needs explicit construction and destruction (as plain old C requests),
- M*LIB doesn't return a value to the underlying data but a pointer to this value:
- this was done for performance (it avoids copying all the data within the stack)
- and for generality reasons (some structure may not allow copying data).
Note: M*LIB defines its own container as an array of a structure of size 1. This has the following advantages:
- you effectively reserve the data whenever you declare a variable,
- you pass automatically the variable per reference for a function call,
- you can not copy the variable by an affectation (you have to use the API instead).
M*LIB offers also the possibility to condense further your code, so that it is more high level:
by using the M_EACH & M_LET macros (if you are not afraid of using syntactic macros):
#include <stdio.h>
#include "m-list.h"
LIST_DEF(list_uint, unsigned int) /* Define struct list_uint_t and its methods */
int main(void) {
M_LET(list, LIST_OPLIST(uint)) { /* Define & init list as list_uint_t */
list_uint_push_back(list, 42); /* Push 42 in the list */
list_uint_push_back(list, 17); /* Push 17 in the list */
for M_EACH(item, list, LIST_OPLIST(uint)) {
printf("%d\n", *item); /* Print the item */
}
} /* Clear of list will be done now */
}
Here is another example with a complete type (with proper initialization & clear function) by using the GMP library:
#include <stdio.h>
#include <gmp.h>
#include "m-array.h"
ARRAY_DEF(array_mpz, mpz_t, (INIT(mpz_init), INIT_SET(mpz_init_set), SET(mpz_set), CLEAR(mpz_clear)) )
int main(void) {
array_mpz_t array ; /* array_mpz_t has been define above */
array_mpz_init(array); /* All type needs to be initialized */
mpz_t z; /* Define a mpz_t type */
mpz_init(z); /* Initialize the z variable */
mpz_set_ui (z, 42);
array_mpz_push_back(array, z); /* Push 42 in the array */
mpz_set_ui (z, 17);
array_mpz_push_back(array, z); /* Push 17 in the array */
array_it_mpz_t it; /* Define an iterator to scan each one */
for(array_mpz_it(it, array) /* Start iterator on first element */
; !array_mpz_end_p(it) /* Until the end is not reached */
; array_mpz_next(it)) { /* Set the iterator to the next element*/
gmp_printf("%Zd\n", /* Get a reference to the underlying */
*array_mpz_cref(it)); /* data and print it */
}
mpz_clear(z); /* Clear the z variable */
array_mpz_clear(array); /* Clear all the array */
}
As the mpz_t type needs proper initialization, copy and destroy functions
we need to tell to the container how to handle such a type.
This is done by giving it the oplist associated to the type.
An oplist is an associative array where the operators are associated to methods.
In the example, we tell to the container to use
the mpz_init function for the INIT operator of the type (aka constructor),
the mpz_clear function for the CLEAR operator of the type (aka destructor),
the mpz_set function for the SET operator of the type (aka copy),
the mpz_init_set function for the INIT_SET operator of the type (aka copy constructor).
See OPLIST chapter for more detailed information.
We can also write the same example shorter:
#include <stdio.h>
#include <gmp.h>
#include "m-array.h"
// Register the oplist of a mpz_t.
#define M_OPL_mpz_t() (INIT(mpz_init), INIT_SET(mpz_init_set), \
SET(mpz_set), CLEAR(mpz_clear))
// Define an instance of an array of mpz_t (both type and function)
ARRAY_DEF(array_mpz, mpz_t)
// Register the oplist of the created instance of array of mpz_t
#define M_OPL_array_mpz_t() ARRAY_OPLIST(array_mpz, M_OPL_mpz_t())
int main(void) {
// Let's define `array` as an 'array_mpz_t' & initialize it.
M_LET(array, array_mpz_t)
// Let's define 'z1' and 'z2' to be 'mpz_t' & initialize it
M_LET (z1, z2, mpz_t) {
mpz_set_ui (z1, 42);
array_mpz_push_back(array, z1); /* Push 42 in the array */
mpz_set_ui (z2, 17);
array_mpz_push_back(array, z2); /* Push 17 in the array */
// Let's iterate over all items of the container
for M_EACH(item, array, array_mpz_t) {
gmp_printf("%Zd\n", *item);
}
} // All variables are cleared with the proper method beyond this point.
return 0;
}
Or even shorter when you're comfortable enough with the library:
#include <stdio.h>
#include <gmp.h>
#include "m-array.h"
// Register the oplist of a mpz_t. It is a classic oplist.
#define M_OPL_mpz_t() M_OPEXTEND(M_CLASSIC_OPLIST(mpz), \
INIT_WITH(mpz_init_set_ui), EMPLACE_TYPE(unsigned int))
// Define an instance of an array of mpz_t (both type and function)
ARRAY_DEF(array_mpz, mpz_t)
// Register the oplist of the created instance of array of mpz_t
#define M_OPL_array_mpz_t() ARRAY_OPLIST(array_mpz, M_OPL_mpz_t())
int main(void) {
// Let's define `array` as an 'array_mpz_t' with mpz_t(17) and mpz_t(42)
M_LET((array,(17),(42)), array_mpz_t) {
// Let's iterate over all items of the container
for M_EACH(item, array, array_mpz_t) {
gmp_printf("%Zd\n", *item);
}
} // All variables are cleared with the proper method beyond this point.
return 0;
}
There are two ways a container can known what is the oplist of a type:
- either the oplist is passed explicitly for each definition of container and for the
M_LETandM_EACHmacros, - or the oplist is registered globally by defining a new macro starting with the prefix
M_OPL_and finishing with the name of type (don't forget the parenthesis and the suffix _t if needed). The macros performing the definition of container and theM_LETandM_EACHwill test if such macro is defined. If it is defined, it will be used. Otherwise, default methods are used.
Here we can see that we register the mpz_t type into the container with
the minimum information of its interface needed, and another one to initialize a mpz_t from an unsigned integer.
We can also see in this example so the container ARRAY provides also a macro to define the oplist of the array itself. This is true for all containers and this enables to define proper recursive container like in this example which reads from a text file a definition of sections:
#include <stdio.h>
#include "m-array.h"
#include "m-tuple.h"
#include "m-dict.h"
#include "m-string.h"
TUPLE_DEF2(symbol, (offset, long), (value, long))
#define M_OPL_symbol_t() TUPLE_OPLIST(symbol, M_BASIC_OPLIST, M_BASIC_OPLIST)
ARRAY_DEF(array_symbol, symbol_t)
#define M_OPL_array_symbol_t() ARRAY_OPLIST(array_symbol, M_OPL_symbol_t())
DICT_DEF2(sections, string_t, array_symbol_t)
#define M_OPL_sections_t() DICT_OPLIST(sections, STRING_OPLIST, M_OPL_array_symbol_t())
int main(int argc, const char *argv[])
{
if (argc < 2) abort();
FILE *f = fopen(argv[1], "rt");
if (!f) abort();
M_LET(sc, sections_t) {
sections_in_str(sc, f);
array_symbol_t *a = sections_get(sc, STRING_CTE(".text"));
if (a == NULL) {
printf("There is no .text section.");
} else {
printf("Section .text is :");
array_symbol_out_str(stdout, *a);
printf("\n");
}
}
return 0;
}
This example reads the data from a file and outputs the .text section if it finds it on the terminal.
Other examples are available in the example folder.
Internal fields of the structure are subject to change even for small revision of the library.
The final goal of the library is to be able to write code like this in pure C while keeping type safety and compile time name resolution:
M_LET(list, list_uint_t) {
push(list, 42);
push(list, 17);
for each (item, list) {
M_PRINT(*item, "\n");
}
}
See the example and M-GENERIC header for details.
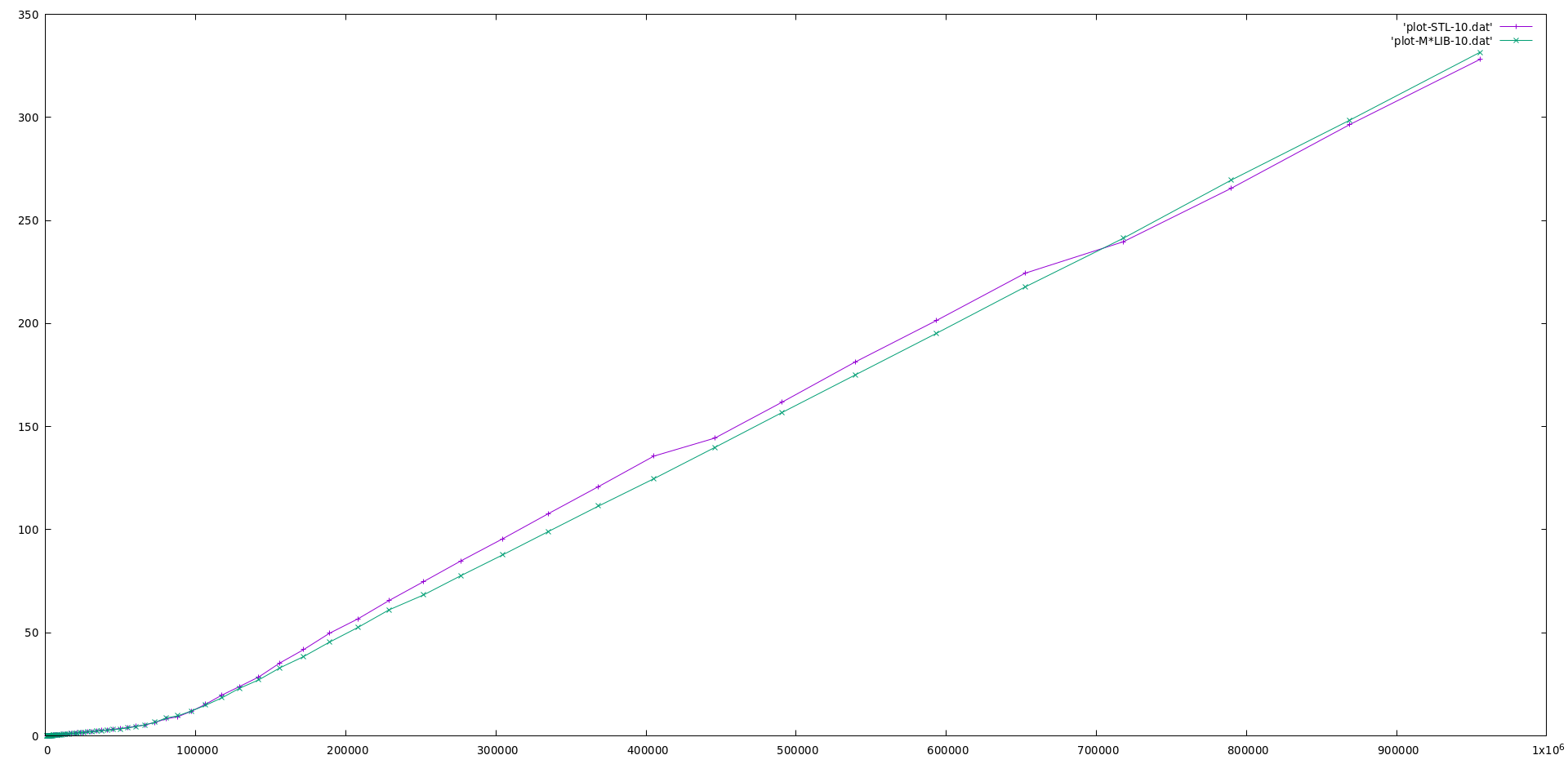
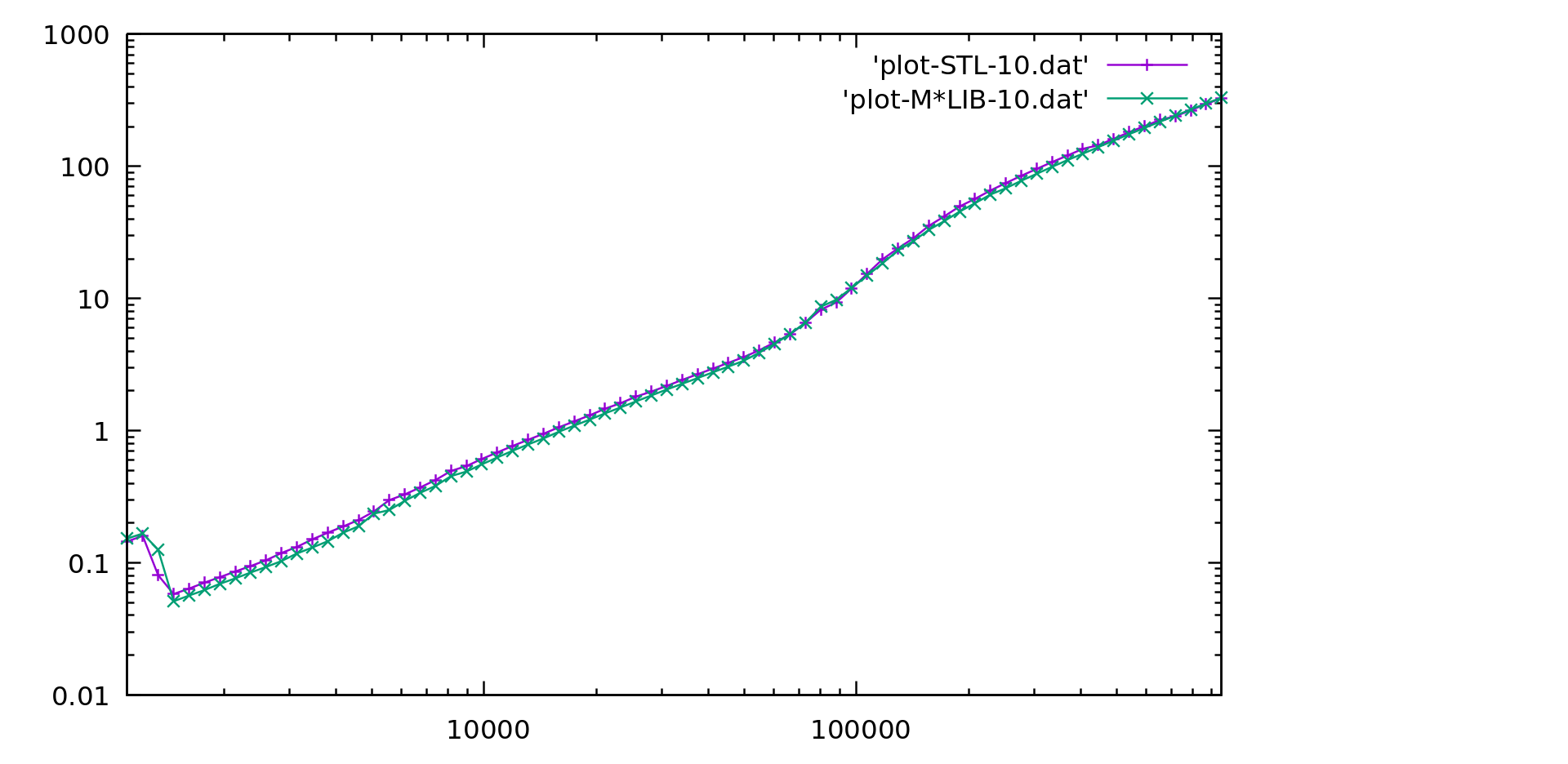
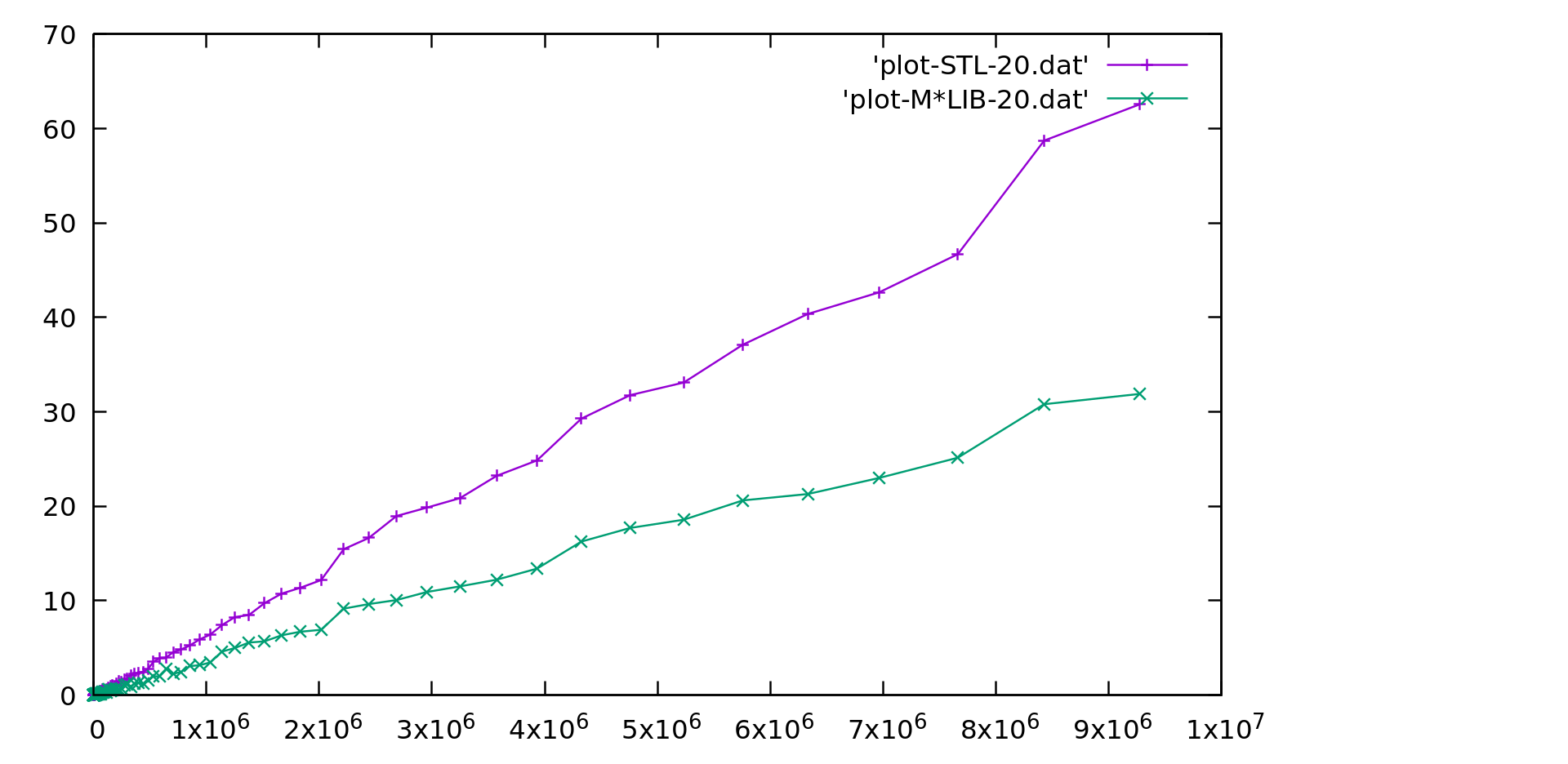
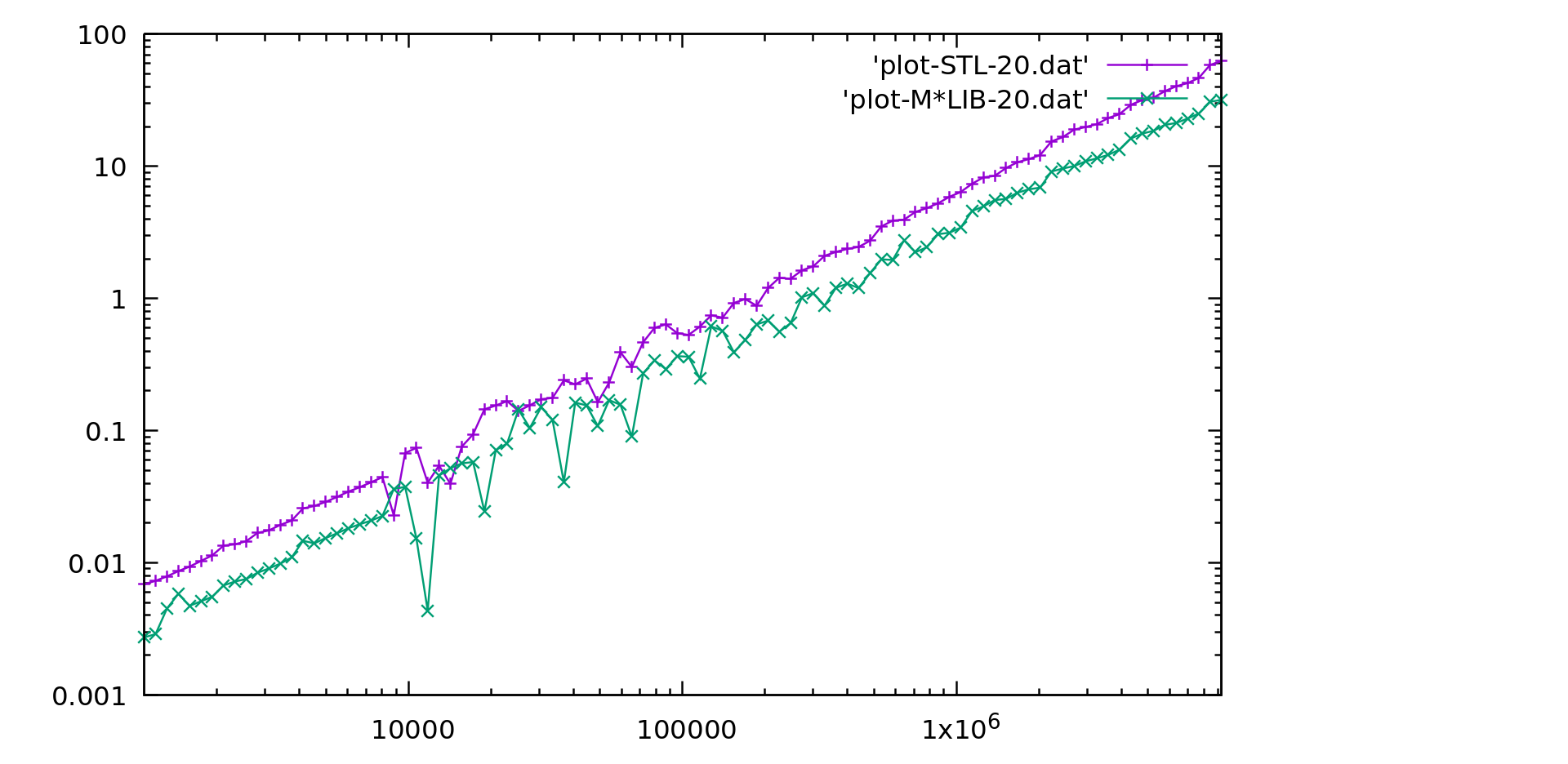
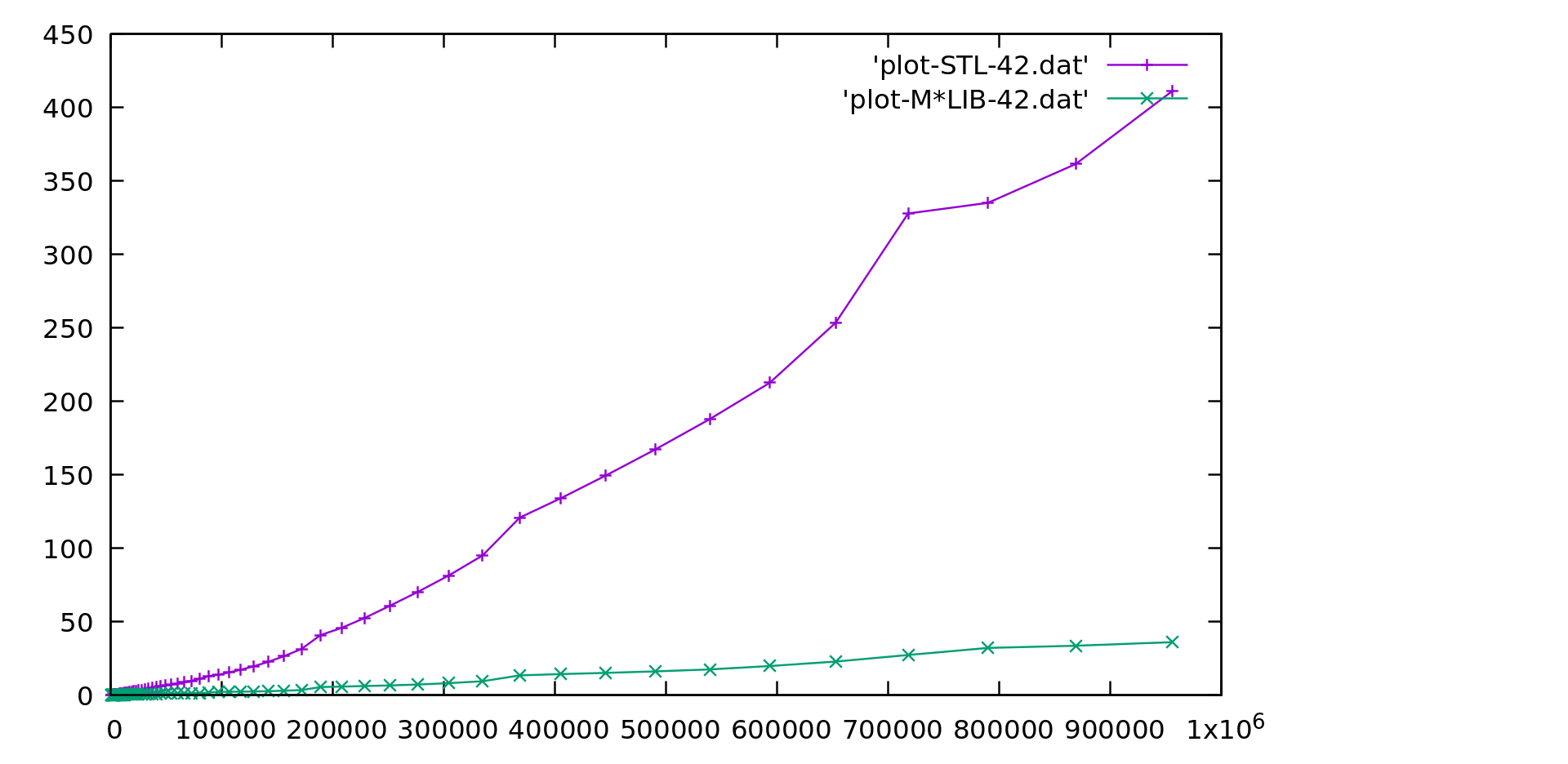
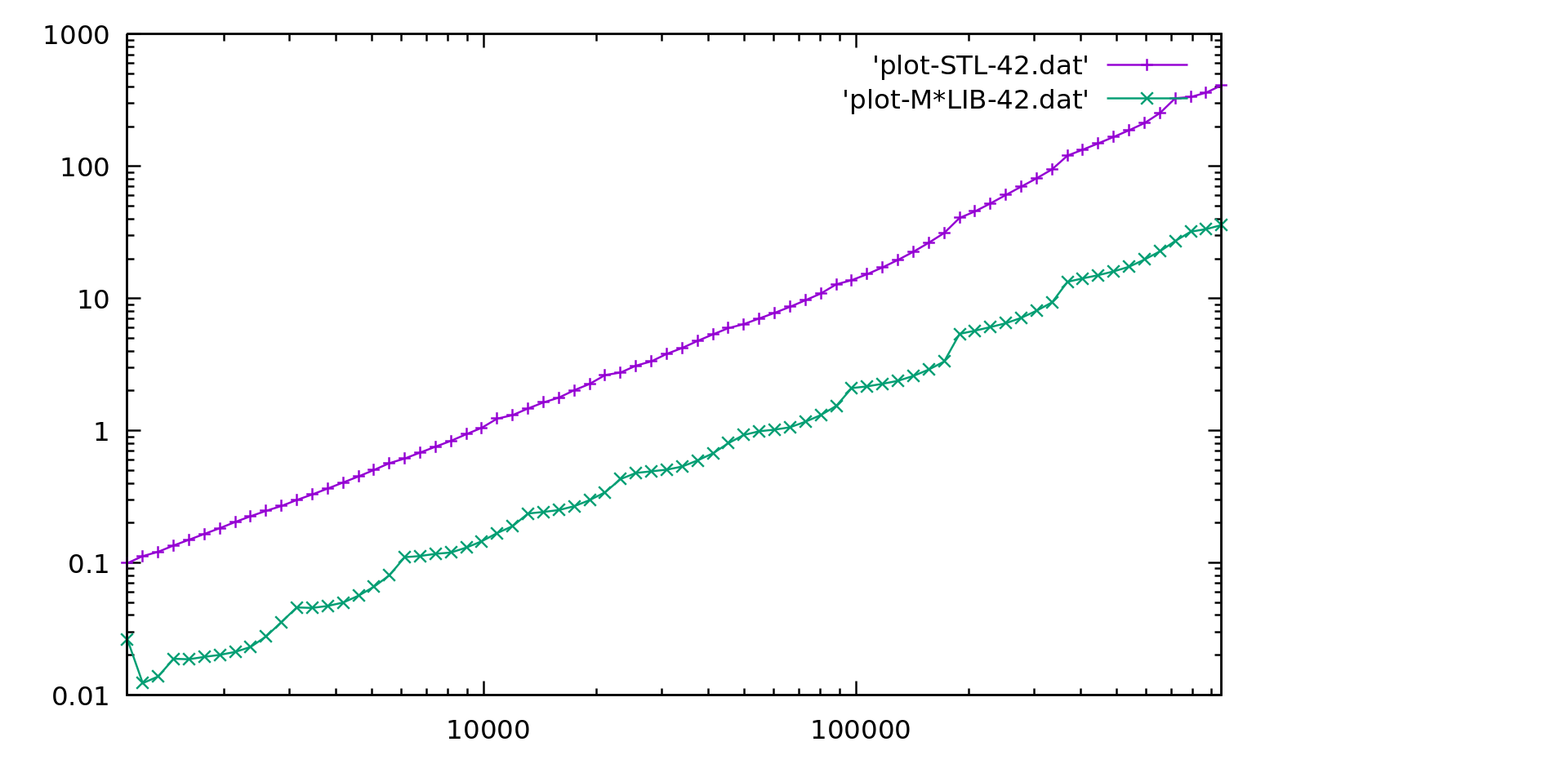
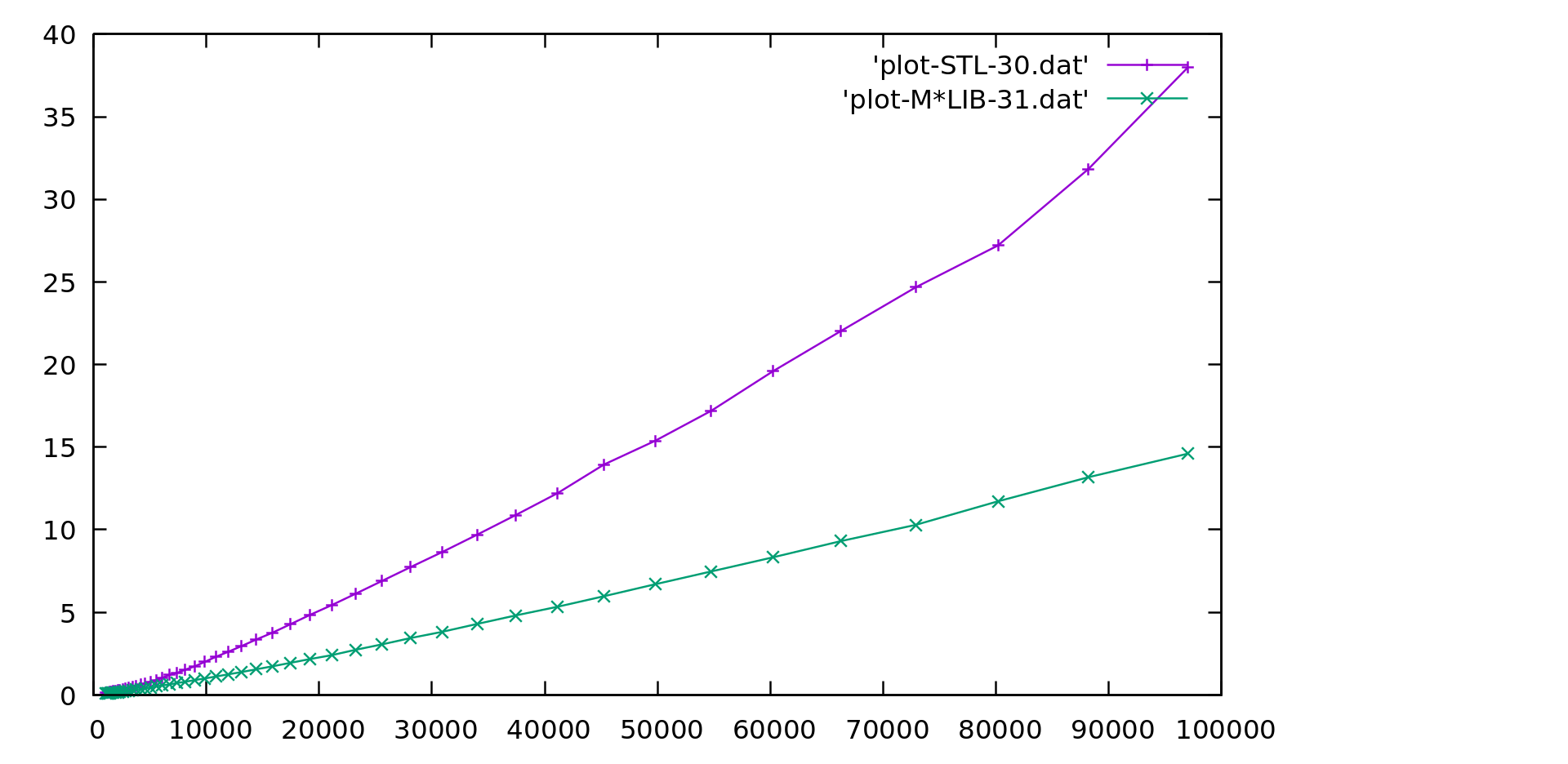
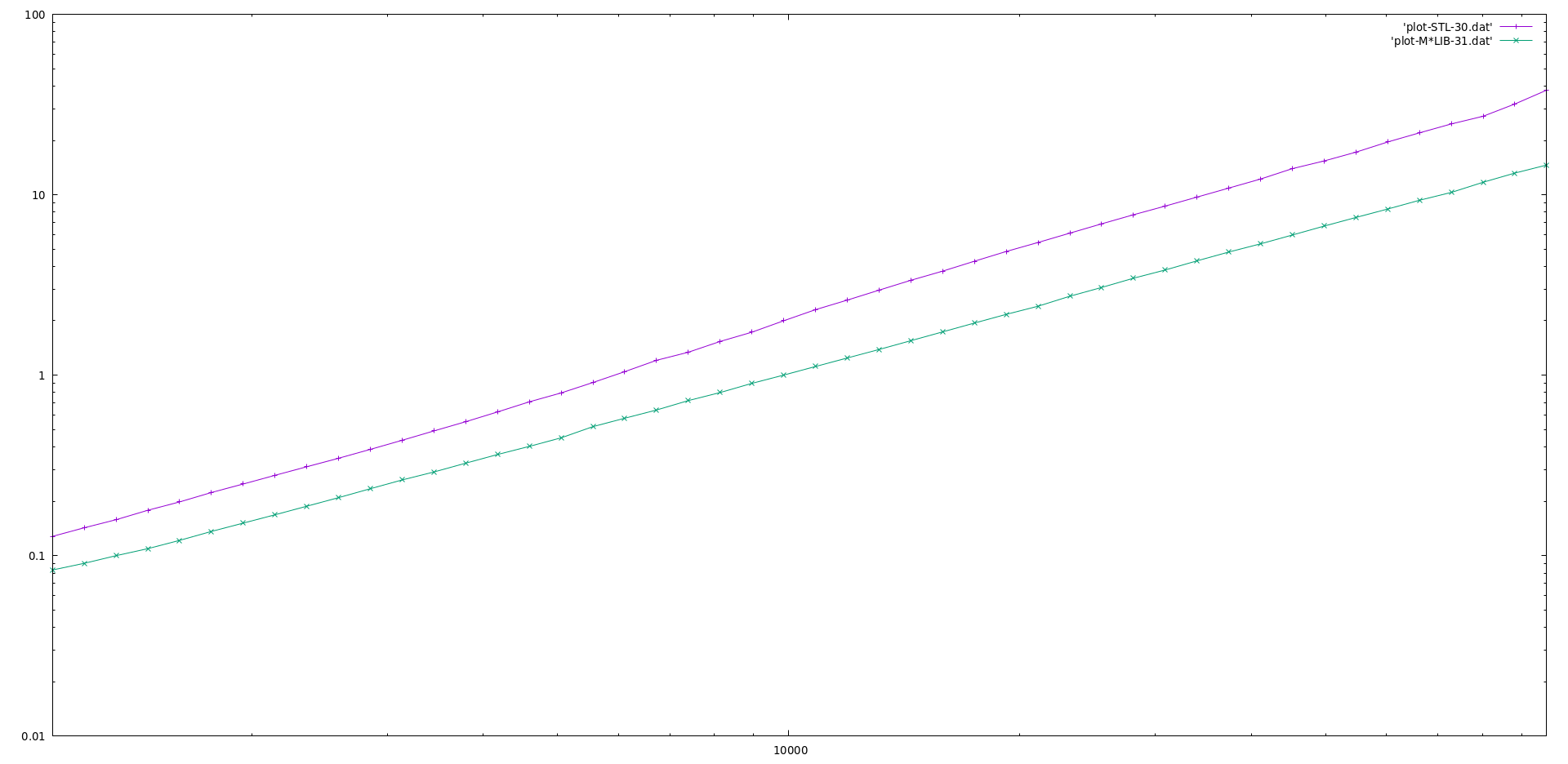
Performance
M*LIB performance is compared to the one of GNU C++ STL (v10.2) in the following graphs. Each graph is presented first in linear scale and then in logarithmic scale to better realize the differences. M*LIB is on par with the STL or even faster.
All used bench codes are available in this repository The results for several different libraries are also available in a separate page.
Singly List
Array
Unordered Map
Ordered Set
OPLIST
Definition
An OPLIST is a fundamental notion of M*LIB that hasn't be seen in any other library.
In order to know how to operate on a type, M*LIB needs additional information
as the compiler doesn't know how to handle properly any type (contrary to C++).
This is done by giving an operator list (or oplist in short) to any macro that
needs to handle the type. As such, an oplist has only meaning within a macro.
Fundamentally, this is the exposed interface of a type:
that is to say the association of the operators defined by the library to the
effective methods provided by the type, including their call interface.
This association is done only with the C preprocessor.
Therefore, an oplist is an associative array of operators to methods in the following format:
(OPERATOR1(method1), OPERATOR2(method2), ...)
It starts with a parenthesis and ends with a parenthesis. Each association is separated by a comma. Each association is composed of a predefined operator (as defined below) a method (in parentheses), and an optional API interface (see below).
In the given example,
the function method1 is used to handle OPERATOR1.
The function method2 is used to handle OPERATOR2, etc.
In case the same operator appears multiple times in the list, the first apparition of the operator has priority, and its associated method will be used. This enables overloading of operators in oplist in case you want to inherit oplists.
The associated method in the oplist is a preprocessor expression that shall not contain a comma as first level.
An oplist has no real form from the C language point of view. It is just an abstraction that disappears after the macro expansion step of the preprocessing. If an oplist remains unprocessed after the C preprocessing, a compiler error will be generated.
Usage
When you define an instance of a new container for a given type, you give the type OPLIST
alongside the type for building the container.
Some functions of the container may not be available in function of the provided interface of the OPLIST
(for optional operators).
Of if some mandatory operators are missing, a compiler error is generated.
The generated container will also provide its own oplist, which will depends on all the oplists used to generate it. This oplist can also be used to generate new containers.
You can therefore use the oplist of the container to chain this new interface
with another container, creating container-of-container.
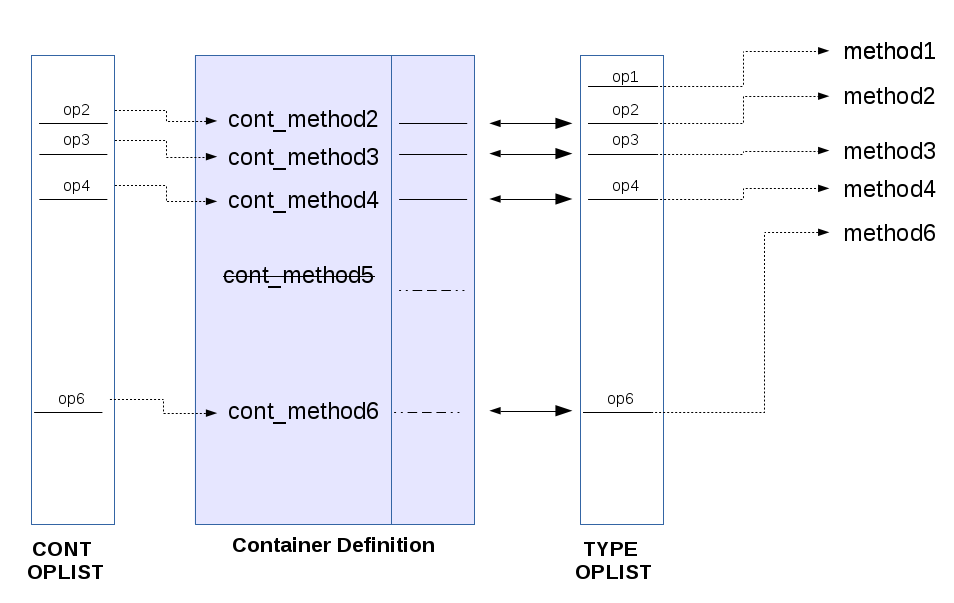
Operators
[!NOTE] An operator shall fail only on abnormal error and if it is marked as potentially raising asynchronous errors. In this case it shall throw exceptions only if exceptions are configured. Otherwise, the program shall be terminated.
In this case, the objects remain initialized and valid but in an unspecified state. In case of in constructors, the object is not constructed and the destructor of the object has not to be called.
[!NOTE] If an operator is not marked as raising asynchronous errors, it shall not fail or throw any exceptions in any cases.
Not all operators are needed for an oplist to handle a container. If some operator is missing, the associated default method of the operator is used if it exists.
The following classic operators are usually expected for an object:
INIT(obj): initialize the objectobjinto a valid state (constructor). It may raise asynchronous error.INIT_SET(obj, org): initialize the objectobjinto the same state as the objectorg(copy constructor). It may raise asynchronous error.SET(obj, org): set the initialized objectobjinto the same state as the initialized object org (copy operator). It may raise asynchronous error.CLEAR(obj): destroy the initialized objectobj, releasing any attached memory (destructor).
Other documented operators are:
NAME()-->prefix: Return the base nameprefixused to construct the container.FIELD()-->field name: Return the name of the field used when constructing the container.TYPE()-->type: Return the base type associated to this oplist.SUBTYPE()-->type: Return the type of the element stored in the container (used to iterate over the container).GENTYPE()-->type: Return the type representing TYPE suitable for a _Generic statement.OPLIST()-->oplist: Return the oplist of the type of the elements stored in the container.KEY_TYPE()-->key_t: Return the key type for associative containers.VALUE_TYPE()-->value_t: Return the value type for associative containers.KEY_OPLIST()-->oplist: Return the oplist of the key type for associative containers.VALUE_OPLIST()-->oplist: Return the oplist of the value type for associative containers.NEW(type)-->type pointer: allocate a new object (with suitable alignment and size) and return a pointer to it. The returned object is not initialized (a constructor operator shall be called afterward). The default method isM_MEMORY_ALLOC(that allocates from the heap). It returns NULL in case of failure.DEL(&obj): free the allocated uninitialized objectobj. The destructor of the pointed object shall be called before freeing the memory by calling this method. The object shall have been allocated by the associated NEW method. The default method isM_MEMORY_DEL(that frees to the heap).objshall not be NULL and shall be of the proper type.REALLOC(type, type pointer, number)-->type pointer: reallocate the given array referenced by type pointer (either a NULL pointer or a pointer returned by the associatedREALLOCmethod itself) to an array of the number of objects of this type and return a pointer to this new array. Previously objects pointed by the pointer are kept up to the minimum of the new size and old one but may have moved from their original positions (if the array is reallocated otherwhere). New objects are not initialized (a constructor operator shall be called afterward). Freed objects are not cleared (A destructor operator shall be called before). The default isM_MEMORY_REALLOC(that allocates from the heap). It returns NULL in case of failure in which case the original array is not modified.FREE(&obj): free the allocated uninitialized array objectobj. The destructor of the pointed objects shall be called before freeing the memory by calling this method. The objects shall have been allocated by the associated REALLOC method. The default isM_MEMORY_FREE(that frees to the heap).INC_ALLOC(size_t s)-->size_t: Define the growing policy of an array (or equivalent structure). It returns a new allocation size based on the old allocation size (s). Default policy is to get the maximum between2*sand 16.
[!NOTE] It doesn't check for overflow: if the returned value is lower than the old one, the user shall raise an overflow error (memory error).
INIT_MOVE(objd, objc): Initializeobjdto the same state thanobjcby stealing as many resources as possible fromobjc, and then clearobjc(constructor ofobjd+ destructor ofobjc). It is semantically equivalent to callingINIT_SET(objd,objc)thenCLEAR(objc)but is usually way faster. Contrary to the C++ choice of using "conservative move" semantic (you still need to call the destructor of a moved object in C++) M*LIB implements a "destructive move" semantic (this enables better optimization). By default, all objects are assumed to be trivially movable (i.e. using memcpy to move an object is safe). Most C objects (even complex structure) are trivially movable and it is a very nice property to have (enabling better optimization). A notable exception are intrusive objects. If an object is not trivially movable, it shall provide anINIT_MOVEmethod or disable theINIT_MOVEmethod entirely
[!NOTE] Some containers may assume that the objects are always trivially movable (like array). Moved objects shall use the same memory allocator.
MOVE(objd, objc): Setobjdto the same state thanobjcby stealing as resources as possible fromobjcand then clearobjc(destructor ofobjc). It is equivalent to callingSET(objd,objc)thenCLEAR(objc)orCLEAR(objd)and thenINIT_MOVE(objd, objc). SeeINIT_MOVEfor details and constraints. TBC if this operator is really needed as callingCLEARthenINIT_MOVEis what do all known implementation, and is efficient.INIT_WITH(obj, ...): Initialize the objectobjwith the given variable set of arguments (constructor). The arguments are variable and can be of different types. It is up to the method of the object to decide how to initialize the object based on this initialization array. This operator is used by theM_LETmacro to initialize objects with their given values and this operator defines what theM_LETmacro supports. It may raise asynchronous error.
[!NOTE] In C11, you can use
API_1(M_INIT_WITH_THROUGH_EMPLACE_TYPE)as method to automatically use the different emplace functions defined inEMPLACE_TYPEthrough a _Generic switch case. TheEMPLACE_TYPEshall use the LIST format. See emplace chapter.
SWAP(objd, objc): Swap the states of the objectobjcand the objectobjd.
[!NOTE] The swapped objects shall use the same allocator.
RESET(obj): Reset the object to its initialized state (Emptying the object if it is a container object).EMPTY_P(obj)-->bool: Test if the container object is empty (true) or not.FULL_P(obj)-->bool: Test if the container object is full (true) or not. Default if not defined is to be not full.GET_SIZE (container)-->size_t: Return the number of elements in the container object.HASH (obj)-->size_t: return a hash of the object (not a secure hash but one that is usable for a hash table). Default is performing a hash of the memory representation of the object. This default implementation is invalid if the object holds pointer to other objects or has spare fields.EQUAL(obj1, obj2)-->bool: Compare the two objects for equality. Return true if both objects are equal, false otherwise. Default is using the C comparison operator. 'obj1' may be an OOR object (Out of Representation) for the Open Addressing dictionary (seeOOR_*operators): in such cases, it shall return false.CMP(obj1, obj2)-->int: Provide a complete order the objects. return a negative integer ifobj1 < obj2, 0 ifobj1 = obj2, a positive integer otherwise. Default is C comparison operator.
[!NOTE] The equivalence between
EQUAL(a, b)andCMP(a, b) == 0is not required, but is usually welcome.
ADD(obj1, obj2, obj3): Set obj1 to the sum of obj2 and obj3. Default is+C operator. It may raise asynchronous error.SUB(obj1, obj2, obj3): Set obj1 to the difference of obj2 and obj3. Default is-C operator. It may raise asynchronous error.MUL(obj1, obj2, obj3): Set obj1 to the product of obj2 and obj3. Default is*C operator. It may raise asynchronous error.DIV(obj1, obj2, obj3): Set obj1 to the division of obj2 and obj3. Default is/C operator. It may raise asynchronous error.GET_KEY (container, key)-->&value: Return a pointer to the value object within the container associated to the keykeyif an object is associated to this key. Otherwise it may return NULL or terminate the program with a logic error (depending on the container). The pointer to the value object remains valid until any modification of the container.SET_KEY (container, key, value): Associate the key objectkeyto the value objectvaluein the given container. It may raise asynchronous error.SAFE_GET_KEY (container, key)-->&value: return a pointer to the value object within the container associated to the keykeyif it exists, or create a new entry in the container and associate it to the keykeywith the default initialization before returning its pointer. The pointer to the object remains valid until any modification of the container. The returned pointer is therefore never NULL. It may raise asynchronous error.ERASE_KEY (container, key)-->bool: Erase the object associated to the keykeywithin the container. Return true if successful, false if the key is not found (nothing is done).PUSH(container, obj): Pushobj(of typeSUBTYPE()) into the containercontainer. How and where it is pushed is container dependent. It may raise asynchronous error.POP(&obj, container): Pop an object from the containercontainerand set it in the initialized object*obj(of typeSUBTYPE()) if the pointerobjis not NULL. Which object is popped is container dependent. It may raise asynchronous error.PUSH_MOVE(container, &obj): Push and move the object*obj(of typeSUBTYPE()) into the containercontainer(*objdestructor). How it is pushed is container dependent.*objis cleared afterward and shall not be used anymore. SeeINIT_MOVEfor more details and constraints. It may raise asynchronous error.POP_MOVE(&obj, container): Pop an object from the containercontainerand init & move it in the uninitialized object*obj(aka constructor). Which object is popped is container dependent.*objshall be uninitialized. SeeINIT_MOVEfor more details and constraints.
[!NOTE] When using a
POPoperator (or any derived operator) on a container, this container shall have at least one object.
The iterator operators are:
IT_TYPE()-->type: Return the type of the iterator object of this container.IT_FIRST(it_obj, obj): Set the iterator it_obj to the first sub-element of the containerobj. What is the first element is container dependent (it may be front or back, or something else). However, iterating from FIRST to LAST (included) or END (excluded) throughIT_NEXTensures going through all elements of the container. If there is no sub-element in the container, it references an end of the container.IT_LAST(it_obj, obj): Set the iterator it_obj to the last sub-element of the containerobj. What is the last element is container dependent (it may be front or back, or something else). However, iterating from LAST to FIRST (included) or END (excluded) throughIT_PREVIOUSensures going through all elements of the container. If there is no sub-element in the container, it references an end of the container.IT_END(it_obj, obj): Set the iterator it_obj to an end of the containerobj. Once an iterator has reached an end, it can't use PREVIOUS or NEXT operators. If an iterator has reached an END, it means that there is no object referenced by the iterator (kind of NULL pointer). There can be multiple representation of the end of a container, but all of then share the same properties.IT_SET(it_obj, it_obj2): Set the iterator it_obj to reference the same sub-element as it_obj2.IT_END_P(it_obj)-->bool: Return true if the iterator it_obj references an end of the container, false otherwise.IT_LAST_P(it_obj)-->bool: Return true if the iterator it_obj references the last element of the container (just before reaching an end) or has reached an end of the container, false otherwise.IT_EQUAL_P(it_obj, it_obj2)-->bool: Return true if both iterators reference the same element, false otherwise.IT_NEXT(it_obj): Move the iterator to the next sub-element or an end of the container if there is no more sub-element. The direction ofIT_NEXTis container dependent. it_obj shall not be an end of the container.IT_PREVIOUS(it_obj): Move the iterator to the previous sub-element or an end of the container if there is no more sub-element. The direction of PREVIOUS is container dependent, but it is the reverse of theIT_NEXToperator. it_obj shall not be an end of the container.IT_CREF(it_obj)-->&subobj: Return a constant pointer to the object referenced by the iterator (of typeconst SUBTYPE()). This pointer remains valid until any modifying operation on the container, or until another reference is taken from this container through an iterator (some containers may reduce theses constraints, for example a list). The iterator shall not be an end of the container.IT_REF(it_obj)-->&subobj: Same asIT_CREF, but return a modifiable pointer to the object referenced by the iterator.IT_INSERT(obj, it_obj, subobj): Insertsubobjafter 'it_obj' in the containerobjand update it_obj to point to the inserted object (as perIT_NEXTsemantics). All other iterators of the same container become invalidated. If 'it_obj' is an end of the container, it inserts the object as the first one.IT_REMOVE(obj, it_obj): Remove it_obj from the containerobj(clearing the associated object) and update it_obj to point to the next object (as perIT_NEXTsemantics). As it modifies the container, all other iterators of the same container become invalidated. it_obj shall not be an end of the container.SPLICE_BACK(objd, objs, it_obj): Move the object of the containerobjsreferenced by the iterator 'it_obj' to the containerobjd. Where it is moved is container dependent (it is recommended however to be like thePUSHmethod). Afterward 'it_obj' references the next item in 'containerSrc' (as perIT_NEXTsemantics). 'it_obj' shall not be an end of the container. Both objects shall use the same allocator. It may raise asynchronous error.SPLICE_AT(objd, id_objd, objs, it_objs): Move the object referenced by the iteratorit_objsfrom the containerobjsjust after the object referenced by the iteratorit_objdin the containerobjd. Ifit_objdreferences an end of the container, it is inserted as the first item of the container (See operatorIT_INSERT). Afterwardit_objsreferences the next item in the containerobjs, andit_objdreferences the moved item in the containerobjd.it_objsshall not be an end of the container. Both objects shall use the same allocator. It may raise asynchronous error.
[!NOTE] An iterator doesn't have a constructor nor destructor methods. Therefore, it cannot not allocate any memory.
[!NOTE] A reference to an object through the pointer get from the iterator is only valid until another reference is taken from the same container (potentially through another iterator), or the iterator is modified or the container itself is modified. This reference is therefore extremely local and should not be stored anywhere else. Some containers may lessen this constraint (for example list or RB-Tree).
[!NOTE] If the container is modified, all iterators of this container become invalid and shall not be used anymore except if the modifying operator provided itself an updated iterator. Some containers may lessen this constraint.
The I/O operators are:
OUT_STR(FILE* f, obj): Outputobjas a custom formatted string into theFILE*streamf. Format is container dependent, but is human readable.IN_STR(obj, FILE* f)-->bool: Setobjto the value associated to the formatted string representation of the object in theFILE*streamf. Return true in case of success (in that case the streamfhas been advanced to the end of the parsing of the object), false otherwise (in that case, the streamfis in an undetermined position but is likely where the parsing fails). It ensures that an object which is output in a FILE throughOUT_STR, and an object which is read from this FILE throughIN_STRare considered as equal. It may raise asynchronous error.GET_STR(string_t str, obj, bool append): Setstrto a formatted string representation of the objectobj. Append to the string ifappendis true, set it otherwise. This operator requires the module m-string. It may raise asynchronous error.PARSE_STR(obj, const char *str, const char **endp)-->bool: Setobjto the value associated to the formatted string representation of the object in the char streamstr. Return true in case of success (in that case if endp is not NULL, it points to the end of the parsing of the object), false otherwise (in that case, if endp is not NULL, it points to an undetermined position but likely to be where the parsing fails). It ensures that an object which is written in a string through GET_STR, and an object which is read from this string throughPARSE_STRare considered as equal. It may raise asynchronous error.OUT_SERIAL(m_serial_write_t *serial, obj)-->m_serial_return_code_t: Outputobjinto the configurable serialization streamserial(See m-serial-json.h for details and example) as per the serial object semantics. ReturnM_SERIAL_OK_DONEin case of success, orM_SERIAL_FAILotherwise. It may raise asynchronous error.IN_SERIAL(obj, m_serial_read_t *serial)-->m_serial_return_code_t: Setobjto its representation from the configurable serialization streamserial(See m-serial-json.h for details and example) as per the serial object semantics.M_SERIAL_OK_DONEin case of success (in that case the streamserialhas been advanced up to the complete parsing of the object), orM_SERIAL_FAILotherwise (in that case, the streamserialis in an undetermined position but usually around the next characters after the first failure). It may raise asynchronous error.
The final operators are:
OOR_SET(obj, int_value): Some containers want to store some information within the uninitialized objects (for example Open Addressing Hash Table). This method stores the integer value 'int_value' into an uninitialized objectobj. It shall be able to differentiate between uninitialized object and initialized object (How is type dependent). The way to store this information is fully object dependent. In general, you use out-of-range value for detecting such values. The object remains uninitialized but sets to of out-of-range value (OOR). int_value can be 0 or 1.OOR_EQUAL(obj, int_value): This method compares the objectobj(initialized or uninitialized) to the out-of-range value (OOR) representation associated to 'int_value' and returns true if both objects are equal, false otherwise. SeeOOR_SET.REVERSE(obj): Reverse the order of the items in the containerobj. It may raise asynchronous error.SEPARATOR()-->character: Return the character used to separate items for I/O methods (default is ',') (for internal use only).EXT_ALGO(name, container oplist, object oplist): Define additional algorithms functions specialized for the containers (for internal use only).PROPERTIES()-->( properties): Return internal properties of a container in a recursive oplist format. Use M_GET_PROPERTY to get the property.EMPLACE_TYPE( ... ): Specify the types usable for "emplacing" the object (initializing the object in-place, constructor). See chapter Emplace construction. THe referenced initializing functions may raise asynchronous error.
[!NOTE] The operator names listed above shall not be defined as macro.
More operators are expected.
Properties
Properties can be stored in a sub-oplist format in the PROPERTIES operator.
The following properties are defined:
LET_AS_INIT_WITH(1)— Defined if the macroM_LETshall always initialize the object withINIT_WITHregardless of the given input. The value of the property is 1 (enabled) or 0 (disabled/default).NOCLEAR(1)— Defined if the objectCLEARoperator can be omitted (like for basic types or POD data). The value of the property is 1 (enabled) or 0 (disabled/default).
[!NOTE] The properties names listed above shall not be defined as macro.
More properties are expected.
Example:
Let's take the interface of the MPZ library:
void mpz_init(mpz_t z); // Constructor of the object z
void mpz_init_set(mpz_t z, const mpz_t s); // Copy Constructor of the object z
void mpz_set(mpz_t z, const mpz_t s); // Copy operator of the object z
void mpz_clear(mpz_t z); // Destructor of the object z
A basic oplist will be:
(INIT(mpz_init),SET(mpz_set),INIT_SET(mpz_init_set),CLEAR(mpz_clear),TYPE(mpz_t))
Much more complete oplist can be built for this type however, enabling much more powerful generation: See in the example
Global namespace
Oplist can be registered globally by defining, for the type type, a macro named
M_OPL_ ## type () that expands to the oplist of the type.
Only type without any space in their name can be registered. A typedef of the type
can be used instead, but this typedef shall be used everywhere.
Example:
#define M_OPL_mpz_t() (INIT(mpz_init),SET(mpz_set), \
INIT_SET(mpz_init_set),CLEAR(mpz_clear),TYPE(mpz_t))
This can simplify a lot OPLIST usage and it is recommended.
Then each times a macro expects an oplist, you can give instead its type. This make the code much easier to read and understand.
There is one exception however: the macros that are used to build oplist
(like ARRAY_OPLIST) don't perform this simplification and the oplist of
the basic type shall be given instead
(This is due to limitation in the C preprocessing).
API Interface Adaptation
Within an OPLIST, you can also specify the needed low-level transformation to perform for calling your method.
This is called API Interface Adaptation: it enables to transform the API requirements of the selected operator
(which is very basic in general) to the API provided by the given method.
Assuming that the method to call is called 'method' and the first argument of the operator is 'output',
which interface is OPERATOR(output, ...)
then the following predefined adaptation are available:
| API | Method | Description |
|---|---|---|
| API_0 | method(output, ...) | No adaptation |
| API_1 | method(oplist, output, ...) | No adaptation but gives the oplist to the method |
| API_2 | method(&output, ...) | Pass by address the first argument (like with M_IPTR) |
| API_3 | method(oplist, &output, ...) | Pass by address the first argument (like with M_IPTR) and give the oplist of the type |
| API_4 | output = method(...) | Pass by return value the first argument |
| API_5 | output = method(oplist, ...) | Pass by return value the first argument and give the oplist of the type |
| API_6 | method(&output, &...) | Pass by address the two first arguments |
| API_7 | method(oplist, &output, &...) | Pass by address the two first argument and give the oplist of the type |
The API Adaptation to use shall be embedded in the OPLIST definition.
For example:
(INIT(API_0(mpz_init)), SET(API_0(mpz_set)), INIT_SET(API_0(mpz_init_set)), CLEAR(API_0(mpz_clear)))
The default adaptation is API_0 (i.e. no adaptation between operator interface and method interface). If an adaptation gives an oplist to the method, the method shall be implemented as macro.
Let's take the interface of a pseudo library:
typedef struct { ... } obj_t;
obj_t *obj_init(void); // Constructor of the object z
obj_t *obj_init_str(const char *str); // Constructor of the object z
obj_t *obj_clone(const obj_t *s); // Copy Constructor of the object z
void obj_clear(obj_t *z); // Destructor of the object z
The library returns a pointer to the object, so we need API_4 for these methods.
There is no method for the SET operator available. However, we can use the macro M_SET_THROUGH_INIT_SET
to emulate a SET semantics by using a combination of CLEAR + INIT_SET. This enables to support
the type for array containers in particular. Or we can avoid this definition if we don't need it.
A basic oplist will be:
(INIT(API_4(obj_init)),SET(API_1(M_SET_THROUGH_INIT_SET)),INIT_SET(API_4(obj_clone)),CLEAR(obj_clear),TYPE(obj_t *))
Generic API Interface Adaptation
You can also describe the exact transformation to perform for calling the method: this is called Generic API Interface Adaptation (or GAIA). With this, you can add constant values to parameter of the method, reorder the parameters as you wish, pass then by pointers, or even change the return value.
The API adaptation is also described in the operator mapping with the method name by using the API keyword. Usage in oplist:
, OPERATOR( API( method, returncode, args...) ) ,
Within the API keyword,
- method is the pure method name (as like any other oplist)
returncodeis the transformation to perform of the return code.- args are the list of the arguments of the function. It can be:
returncode can be
NONE— no transformation,VOID— cast to void,NEG— inverse the result,EQ(val)/NEQ(val)/LT(val)/GT(val)/LE(val)/GE(val)— compare the return code to the given valueARG[1-9]— set the associated argument number of the operator to the return code
An argument can be:
- a constant,
- a variable name — probably global,
ID( constant or variable)— if the constant or variable is not a valid token,ARG[1-9]— the associated argument number of the operator,ARGPTR[1-9]— the pointer of the associated argument number of the operator,OPLIST— the oplist
Therefore, it supports at most 9 arguments.
Example:
, EQUAL( API(mpz_cmp, EQ(0), ARG1, ARG2) ) ,
This will transform a return value of 0 by the mpz_cmp method into a boolean for the EQUAL operator.
Another Example:
, OUT_STR( API(mpz_out_str, VOID, ARG1, 10, ARG2) ) ,
This will serialize the mpz_t value in base 10 using the mpz_out_str method, and discarding the return value.
Disable an operator
An operator OP can be defined, omitted or disabled:
( OP(f) ): the function f is the method of the operator OP( OP(API_N(f)) ): the function f is the method of the operator OP with the API transformation number N,( ): the operator OP is omitted, and the default global operation for OP is used (if it exists).( OP(0) ): the operator OP is disabled, and it can never be used.
This can be useful to disable an operator in an inherited oplist.
Which OPLIST to use?
My type is:
- a C Boolean:
M_BOOL_OPLIST(M_BASIC_OPLISTalso works partially), - a C integer or a C float:
M_BASIC_OPLIST(it can also be omitted), - a C enumerate:
M_ENUM_OPLIST, - a pointer to something (the container do nothing on the pointed object):
M_PTR_OPLIST, - a plain structure that can be init/copy/compare with memset/memcpy/memcmp:
M_POD_OPLIST, - a plain structure that is passed by reference using [1] and can be init,copy,compare with
memset,memcpy,memcmp:M_A1_OPLIST, - a type that offers
name_init,name_init_set,name_set,name_clearmethods:M_CLASSIC_OPLIST, - a const string (
const char *) that is neither freed nor moved:M_CSTR_OPLIST, - a M*LIB string_t:
STRING_OPLIST, - a M*LIB container: the
OPLISTof the used container, - other things: you need to provide a custom
OPLISTto your type.
[!NOTE] The precise exported methods of the OPLIST depend on the version of the used C language. Typically, in C11 mode, the
M_BASIC_OPLISTexports all needed methods to handle generic input/output of int/floats (using_Generickeyword) whereas it is not possible in C99 mode.
This explains why JSON import/export is only available in C11 mode (See below chapter).
Basic usage of oplist is available in the example
Oplist inheritance
Oplist can inherit from another one.
This is useful when you want to customize some specific operators while keeping other ones by default.
For example, internally M_BOOL_OPLIST inherits from M_BASIC_OPLIST.
A typical example is if you want to provide the OOR_SET and OOR_EQUAL operators to a type
so that it can be used in an OA dict.
To do it, you use the M_OPEXTEND macro. It takes as first argument the oplist you want to inherit with,
and then you provide the additional associations between operators to methods you want to add
or override in the inherited oplist. For example:
int my_int_oor_set(char c) { return INT_MIN + c; }
bool my_int_oor_equal(int i1, int i2) { return i1 == i2; }
#define MY_INT_OPLIST \
M_OPEXTEND(M_BASIC_OPLIST, OOR_SET(API_4(my_int_oor_set)), \
OOR_EQUAL(my_int_oor_equal))
You can even inherit from another oplist to disable some operators in your new oplist. For example:
#define MY_INT_OPLIST \
M_OPEXTEND(M_BASIC_OPLIST, HASH(0), CMP(0), EQUAL(0))
MY_INT_OPLIST is a new oplist that handles integers but has disabled the operators HASH, CMP and EQUAL.
The main interest is to disable the generation of optional methods of a container (since they are only
expanded if the oplist provides some methods).
Usage of inheritance and oplist is available in the int example and the cstr example
Advanced example
Let's take a look at the interface of the FILE* interface:
FILE *fopen(const char *filename, const char *mode);
fclose(FILE *f);
There is no INIT operator (an argument is mandatory), no INIT_SET operator.
It is only possible to open a file from a filename.
FILE* contains some space, so an alias is needed.
There is an optional mode argument, which is a constant string, and isn't a valid preprocessing token.
An oplist can therefore be:
typedef FILE *m_file_t;
#define M_OPL_m_file_t() (INIT_WITH(API(fopen, ARG1, ARG2, ID("wt"))), \
SET(0),INIT_SET(0),CLEAR(fclose),TYPE(m_file_t))
Since there is no INIT_SET operator available, pretty much no container can work.
However, you'll be able to use a writing text FILE* using a M_LET:
M_LET( (f, ("tmp.txt")), m_file_t) {
fprintf(f, "This is a tmp file.");
}
This is pretty useless, except if you enable exceptions... In which case, this enables you to close the file even if an exception is thrown.
Memory Allocation
Customization
Memory Allocation functions can be globally set by overriding the following macros before using the definition _DEF macros:
M_MEMORY_ALLOC (type)-->ptr: return a pointer to a new object of typetype.M_MEMORY_DEL (ptr): free the single object pointed byptr.M_MEMORY_REALLOC (type, ptr, number)-->ptr: return a pointer to an array of 'number' objects of typetype, reusing the old array pointed byptr.ptrcan be NULL, in which case the array will be created.M_MEMORY_FREE (ptr): free the array of objects pointed byptr.
ALLOC and DEL operators are supposed to allocate fixed size single element object (no array).
These objects are not expected to grow.
REALLOC and FREE operators deal with allocated memory for growing objects.
Do not mix pointers between both: a pointer allocated by ALLOC (resp. REALLOC) is supposed
to be only freed by DEL (resp. FREE). There are separated 'free' operators to enable
specialization in the allocator (a good allocator can take this hint into account).
M_MEMORY_ALLOC and M_MEMORY_REALLOC are supposed to return NULL in case of memory allocation failure.
The defaults are malloc, free, realloc and free.
You can also override the methods NEW, DEL, REALLOC and DEL in the oplist given to a container
so that only the container will use these memory allocation functions instead of the global ones.
Out-of-memory error
When a memory exhaustion is reached, the global macro M_MEMORY_FULL is called
and the function returns immediately after.
The object remains in a valid (if previously valid) and unchanged state in this case.
By default, the macro prints an error message and aborts the program: handling non-trivial memory errors can be hard, testing them is even harder but still mandatory to avoid security holes. So the default behavior is rather conservative.
It can however be overloaded to handle other policy for error handling like:
- throwing an error (which is automatically done by including header m-try ),
- set a global error and handle it when the function returns [planned, not possible yet],
- other policy.
This function takes the size in bytes of the memory that has been tried to be allocated.
If needed, this macro shall be defined prior to instantiate the structure.
[!NOTE] A good design should handle a process entire failure (using for examples multiple processes for doing the job) so that even if a process stops, it should be recovered. See here for more information about why abandonment is good software practice.
In M*LIB, we classify the kind of errors according to this classification:
- logical error: the expectations of the function are not met (null pointer passed as argument, negative argument, invalid object state, ...). In which case, the sanction is abnormal halt of the program, if it is detected, regardless of the configuration of M*LIB. Normally, debug build will detect such errors.
- abnormal error: errors that are unlikely to be expected during the execution of the program (like no more memory). In which case, the sanction is either abnormal halt of the program or throwing an exception.
- normal error: errors that can be expected in the execution of the program (all I/O errors like file not found or invalid file format, parsing of invalid user input, no solution found, etc). In which case, the error is reported by the return code of the function or by polling for error (See
ferror) in the data structure.
Emplace construction
For M*LIB, 'emplace' means pushing a new object in the container,
while not giving it a copy of the new object, but the parameters needed
to construct this object.
This is a shortcut to the pattern of creating the object with the arguments,
pushing it in the container, and deleting the created object
(even if using PUSH_MOVE could simplify the design).
The containers defining an emplace like method generate the emplace functions
based on the provided EMPLACE_TYPE of the oplist. If EMPLACE_TYPE doesn't exist or is disabled, no emplace function is generated. Otherwise EMPLACE_TYPE identifies
which types can be used to construct the object and which methods to use to construct then:
EMPLACE_TYPE( typeA ), means that the object can be constructed fromtypeAusing the method of theINIT_WITHoperator. An emplace function without suffix will be generated.EMPLACE_TYPE( (typeA, typeB, ...) ), means that the object can be constructed from the lists of typestypeA,typeB,...using the method of theINIT_WITHoperator. An emplace function without suffix will be generated.EMPLACE_TYPE( LIST( (suffix, function, typeA, typeB, ...), (suffix,function,typeA,typeB,...) means that the object can be constructed from all the provided lists of typestypeA,typeB,...using the provided methodfunction. Thefunctionis the method to call to construct the object from the list of types. It supports API transformation if needed. As many emplace function will be generated as there are constructor function. Each generated function will be generated by suffixing it with the providedsuffix(if suffix is empty, no suffix will be added).
For example, for an ARRAY definition named vec, if there is such a definition of EMPLACE_TYPE(const char *), it will generate a function vec_emplace_back(const char *). This function will take a const char* parameter, construct the object from it (for example a string_t) then push the result back on the array.
Another example, for an ARRAY definition named vec, if there is such a definition of EMPLACE_TYPE( LIST( (_ui, mpz_init_set_ui, unsigned int), (_si, mpz_init_set_si, int) ) ), it will generate two functions vec_emplace_back_ui(unsigned int) and vec_emplace_back_si(int). These functions will take the (unsigned) int parameter, construct the object from it then push the result back on the array.
If the container is an associative array, the name will be constructed as follows:
name_emplace[_key_keysuffix][_val_valsuffix]
where keysuffix (resp. valsuffix) is the emplace suffix of the key (resp. value) oplist.
If you take once again the example of the FILE*, a more complete oplist can be:
typedef FILE *m_file_t;
#define M_OPL_m_file_t() (INIT_WITH(API_1(M_INIT_WITH_THROUGH_EMPLACE_TYPE)), \
SET(0),INIT_SET(0),CLEAR(fclose),TYPE(m_file_t), \
EMPLACE_TYPE(LIST((_str, API(fopen, ARG1, ARG2, ID("wb")), char *))))
The INIT_WITH operator will use the provided init methods in the EMPLACE_TYPE.
EMPLACE_TYPE defines a _str suffix method with a GAIA for fopen, and accepts a char* as argument.
The GAIA specifies that the output (ARG1) is set as return value,
ARG2 is given as the first argument, and a third constant argument is used.
ERRORS & COMPILERS
M*LIB implements internally some controls to reduce the list of errors/warnings generated by a compiler when it detects some violation in the use of oplist by use of static assertion. It can also transform some type warnings into proper errors. In C99 mode, it will produce illegal code with the name of the error as attribute. In C11 mode, it will use static assert and produce a detailed error message.
The list of errors it can generate:
M_LIB_NOT_AN_OPLIST: something has been given (directly or indirectly) and it doesn't reduce as a proper oplist. You need to give an oplist for this definition.M_LIB_ERROR(ARGUMENT_OF_*_OPLIST_IS_NOT_AN_OPLIST, name, oplist): sub error of the previous error one, identifying the root cause. The error is in the oplist construction of the given macro. You need to give an oplist for this oplist construction.M_LIB_MISSING_METHOD: a required operator doesn't define any method in the given oplist. You need to complete the oplist with the missing method.M_LIB_TYPE_MISMATCH: the given oplist and the type do not match each other. You need to give the right oplist for this type.M_LIB_NOT_A_BASIC_TYPE: The oplistM_BASIC_OPLIST(directly or indirectly) has been used with the given type, but the given type is not a basic C type (int/float). You need to give the right oplist for this type.
You should focus mainly on the first reported error/warning even if the link between what the compiler report and what the error is is not immediate. The error is always in one of the oplist definition.
Examples of typical errors:
- lack of inclusion of an header,
- overriding locally operator names by macros (like
NEW,DEL,INIT,OPLIST,...), - lack of
( )or double level of( )around the oplist, - an unknown variable (example using
BASIC_OPLISTinstead ofM_BASIC_OPLIST), - the name given to the oplist is not the same as the one used to define the methods,
- use of a type instead of an oplist in the
OPLISTdefinition, - a missing sub oplist in the
OPLISTdefinition.
A good way to avoid these errors is to register the oplist globally as soon as you define the container.
In case of difficulties, debugging can be done by generating the preprocessed file
(by usually calling the compiler with the -E option instead of -c)
and check what's wrong in the preprocessed file:
cc -std=c99 -E test-file.c |grep -v '^#' > test-file.i
perl -i -e 's/;/;\n/g' test-file.i
cc -std=c99 -c -Wall test-file.i
If there is a warning reported by the compiler in the generated code, then there is definitely an error you should fix (except if it reports shadowed variables), in particular cast evolving pointers.
You should also turn off the macro expansion of the errors reported by your compiler. There are often completely useless and misleading:
- For GCC, uses
-ftrack-macro-expansion=0 - For CLANG, uses
-fmacro-backtrace-limit=1
Due to the unfortunate weak nature of the C language for pointers,
you should turn incompatible pointer type warning into an error in your compiler.
For GCC / CLANG, uses -Werror=incompatible-pointer-types
For MS Visual C++ compiler , you need the following options:
/Zc:__cplusplus /Zc:preprocessor /D__STDC_WANT_LIB_EXT1__ /EHsc
External Reference
Many other implementation of generic container libraries in C exist. For example, a non exhaustive list is:
- BKTHOMPS/CONTAINERS
- BSD tree.h
- CC
- CDSA
- CELLO
- C-Macro-Collections
- COLLECTIONS-C
- CONCURRENCY KIT
- CTL by glouw or by rurban
- GDB internal library
- GLIB
- KLIB
- LIBCHASTE
- LIBCOLLECTION
- LIBDICT
- LIBDYNAMIC
- LIBLFDS
- LIBSRT: Safe Real-Time library for the C programming language
- NEDTRIES
- POTTERY
- QLIBC
- SC
- SGLIB
- Smart pointer for GNUC
- STB stretchy_buffer
- STC - Smart Template Container for C
- TommyDS
- UTHASH
Each can be classified into one of the following concept:
- Each object is handled through a pointer to void (with potential registered callbacks to handle the contained objects for the specialized methods). From a user point of view, this makes the code harder to use (as you don't have any help from the compiler) and type unsafe with a lot of cast (so no formal proof of the code is possible). This also generally generate slower code (even if using link time optimization, this penalty can be reduced). Properly used, it can yet be the most space efficient for the code, but can consume a lot more for the data due to the obligation of using pointers. This is however the easiest to design & code.
- Macros are used to access structures in a generic way (using known fields of a structure — typically size, number, etc.). From a user point of view, this can create subtitle bug in the use of the library (as everything is done through macro expansion in the user defined code) or hard to understand warnings. This can generates fully efficient code. From a library developer point of view, this can be quite limiting in what you can offer.
- Macros detect the type of the argument passed as parameter using _Generics, and calls the associated methods of the switch. The difficulty is how to add pure user types in this generic switch.
- A known structure is put in an intrusive way in the type of all the objects you wan to handle. From a user point of view, he needs to modify its structure and has to perform all the allocation & deallocation code itself (which is good or bad depending on the context). This can generate efficient code (both in speed and size). From a library developer point of view, this is easy to design & code. You need internally a cast to go from a pointer to the known structure to the pointed object (a reverse of offsetof) that is generally type unsafe (except if mixed with the macro generating concept). This is quite limitation in what you can do: you can't move your objects so any container that has to move some objects is out-of-question (which means that you cannot use the most efficient container).
- Header files are included multiple times with different contexts (some different values given to defined macros) in order to generate different code for each type. From a user point of view, this creates a new step before using the container: an instantiating stage that has to be done once per type and per compilation unit (The user is responsible to create only one instance of the container, which can be troublesome if the library doesn't handle proper prefix for its naming convention). The debug of the library is generally easy and can generate fully specialized & efficient code. Incorrectly used, this can generate a lot of code bloat. Properly used, this can even create smaller code than the void pointer variant. The interface used to configure the library can be quite tiresome in case of a lot of specialized methods to configure: it doesn't enable to chain the configuration from a container to another one easily. It also cannot have heavy customization of the code.
- Macros are used to generate context-dependent C code enabling to generate code for different type. This is pretty much like the headers solution but with added flexibility. From a user point of view, this creates a new step before using the container: an instantiating stage that has to be done once per type and per compilation unit (The user is responsible to create only one instance of the container, which can be troublesome if the library doesn't handle proper prefix for its naming convention). This can generate fully specialized & efficient code. Incorrectly used, this can generate a lot of code bloat. Properly used, this can even create smaller code than the void pointer variant. From a library developer point of view, the library is harder to design and to debug: everything being expanded in one line, you can't step in the library (there is however a solution to overcome this limitation by adding another stage to the compilation process). You can however see the generated code by looking at the preprocessed file. You can perform heavy context-dependent customization of the code (transforming the macro preprocessing step into its own language). Properly done, you can also chain the methods from a container to another one easily, enabling expansion of the library. Errors within the macro expansion are generally hard to decipher, but errors in code using containers are easy to read and natural.
M*LIB category is mainly the last one. Some macros are also defined to access structure in a generic way, but they are optional. There are also intrusive containers.
M*LIB main added value compared to other libraries is its oplist feature enabling it to chain the containers and/or use complex types in containers: list of array of dictionary of C++ objects are perfectly supported by M*LIB.
For the macro-preprocessing part, other libraries and reference also exist. For example:
- Boost preprocessor
- C99 Lambda
- C Preprocessor Tricks, Tips and Idioms
- CPP MAGIC
- MAP MACRO
- metalang99
- OrderPP
- P99
- Zlang
You can also consult awesome-c-preprocessor for a more comprehensive list of libraries.
For the string part, there is the following libraries for example:
- POTTERY STRING
- SDS
- STC - C99 Standard Container library
- STR -yet another string library for C language
- The Better String Library with a page that lists a lot of other string libraries.
- VSTR with a page that lists a lot of other string libraries.
API Documentation
The M*LIB reference card is available here.
Generic methods
The generated containers tries to generate and provide a consistent interface: their methods would behave the same for all generated containers. This chapter will explain the generic interface. In case of difference, it will be explained in the specific container.
In the following description:
nameis the prefix used for the container generation,name_trefers to the type of the container,name_it_trefers to the iterator type of the container,type_trefers to the type of the object stored in the container,key_type_trefers to the type of the key object used to associate an element to,value_type_trefers to the type of the value object used to associate an element to.name_itref_trefers to a pair of key and value for associative arrays.
An object shall be initialized (aka constructor) before being used by other methods. It shall be cleared (aka destructor) after being used and before program termination. An iterator has not destructor but shall be set before being used.
A container takes as input the
name— it is a mandatory argument that is the prefix used to generate all functions and types,type— it is a mandatory argument that the basic element of the container,oplist— it is an optional argument that defines the methods associated to the type. The provided oplist (if provided) shall be the one that is associated to the type, otherwise it won't generate compilable code. If there is no oplist parameter provided, a globally registered oplist associated to the type is used if possible, or the basic oplist for basic C types is used. This oplist will be used to handle internally the objects of the container.
The type given to any templating macro can be either
an integer, a float, a boolean, an enum, a named structure, a named union, a pointer to such types,
or a typedef alias of any C type:
in fact, the only constraint is that the preprocessing concatenation between type and variable into
'type variable' shall be a valid C expression.
Therefore the type cannot be a C array or a function pointer
and you shall use a typedef as an intermediary named type for such types.
The output parameters are listed fist, then the input/output parameters and finally the input parameters.
This generic interface is specified as follow:
void name_init(name_t container)
Initialize the container container (aka constructor) to an empty container.
Also called the default constructor of the container.
void name_init_set(name_t container, const name_t ref)
Initialize the container container (aka constructor) and set it to a copy of ref.
This method is only created if the INIT_SET & SET methods are provided.
Also called the copy constructor of the container.
void name_set(name_t container, const name_t ref)
Set the container container to the copy of ref.
This method is only created if the INIT_SET and SET methods are provided.
void name_init_move(name_t container, name_t ref)
Initialize the container container (aka constructor)
by stealing as many resources from ref as possible.
After-wise ref is cleared and can no longer be used (aka destructor).
void name_move(name_t container, name_t ref)
Set the container container (aka constructor)
by stealing as many resources from ref as possible.
After-wise ref is cleared and can no longer be used (aka destructor).
void name_clear(name_t container)
Clear the container container (aka destructor),
calling the CLEAR method of all the objects of the container and freeing memory.
The object can't be used anymore, except to be reinitialized with a constructor.
void name_reset(name_t container)
Reset the container clearing and freeing all objects stored in it. The container becomes empty but remains initialized.
type_t *name_back(const name_t container)
Return a pointer to the data stored in the back of the container. This pointer should not be stored in a global variable.
type_t *name_front(const name_t container)
Return a pointer to the data stored in the front of the container. This pointer should not be stored in a global variable.
void name_push(name_t container, const type_t value)
void name_push_back(name_t container, const type_t value)
void name_push_front(name_t container, const type_t value)
Push a new element in the container container as a copy of the object value.
This method is created only if the INIT_SET operator is provided.
The _back suffixed method will push it in the back of the container.
The _front suffixed method will push it in the front of the container.
type_t *name_push_raw(name_t container)
type_t *name_push_back_raw(name_t container)
type_t *name_push_front_raw(name_t container)
Push a new element in the container container
without initializing it and returns a pointer to the non-initialized data.
The first thing to do after calling this function shall be to initialize the data
using the proper constructor of the object of type type_t.
This enables using more specialized constructor than the generic copy one.
The user should use other _push function if possible rather than this one
as it is low level and error prone.
This pointer should not be stored in a global variable.
The _back suffixed method will push it in the back of the container.
The _front suffixed method will push it in the front of the container.
type_t *name_push_new(name_t container)
type_t *name_push_back_new(name_t container)
type_t *name_push_front_new(name_t container)
Push a new element in the container container
and initialize it with the default constructor associated to the type type_t.
Return a pointer to the initialized object.
This pointer should not be stored in a global variable.
This method is only created if the INIT method is provided.
The _back suffixed method will push it in the back of the container.
The _front suffixed method will push it in the front of the container.
void name_push_move(name_t container, type_t *value)
void name_push_back_move(name_t container, type_t *value)
void name_push_front_move(name_t container, type_t *value)
Push a new element in the container container
as a move from the object *value:
it will therefore steal as much resources from *value as possible.
Afterward *value is cleared and cannot longer be used (aka. destructor).
The _back suffixed method will push it in the back of the container.
The _front suffixed method will push it in the front of the container.
void name_emplace[suffix](name_t container, args...)
void name_emplace_back[suffix](name_t container, args...)
void name_emplace_front[suffix](name_t container, args...)
Push a new element in the container container
by initializing it with the provided arguments.
The provided arguments shall therefore match one of the constructor provided
by the EMPLACE_TYPE operator.
There is one generated method per suffix defined in the EMPLACE_TYPE operator,
and the suffix in the generated method name corresponds to the suffix defined
in the EMPLACE_TYPE operator (it can be empty).
This method is created only if the EMPLACE_TYPE operator is provided.
See emplace chapter for more details.
The _back suffixed method will push it in the back of the container.
The _front suffixed method will push it in the front of the container.
void name_pop(type_t *data, name_t container)
void name_pop_back(type_t *data, name_t container)
void name_pop_front(type_t *data, name_t container)
Pop a element from the container container;
and set *data to this value if data is not the NULL pointer,
otherwise it only pops the data.
This method is created if the SET or INIT_MOVE operator is provided.
The _back suffixed method will pop it from the back of the container.
The _front suffixed method will pop it from the front of the container.
void name_pop_move(type_t *data, name_t container)
void name_pop_move_back(type_t *data, name_t container)
void name_pop_move_front(type_t *data, name_t container)
Pop a element from the container container
and initialize and set *data to this value (aka. constructor)
by stealing as much resources from the container as possible.
data shall not be a NULL pointer.
The _back suffixed method will pop it from the back of the container.
The _front suffixed method will pop it from the front of the container.
bool name_empty_p(const name_t container)
Return true if the container is empty, false otherwise.
void name_swap(name_t container1, name_t container2)
Swap the container container1 and container2.
void name_set_at(name_t container, size_t key, type_t value)
void name_set_at(name_t container, key_type_t key, value_type_t value) [for associative array]
Set the element associated to key of the container container to value.
If the container is sequence-like (like array), the key is an integer.
The selected element is the key-th element of the container,
The index key shall be within the size of the container.
This method is created if the INIT_SET operator is provided.
If the container is associative-array like,
the selected element is the value object associated to the key object in the container.
It is created if it doesn't exist, overwritten otherwise.
void name_emplace_key[keysuffix](name_t container, keyargs..., value_type_t value) [for associative array]
void name_emplace_val[valsuffix](name_t container, key_type_t key, valargs...) [for associative array]
void name_emplace_key[keysuffix]_val[valsuffix](name_t container, keyargs..., valargs...) [for associative array]
Set the element associated to key of the container container to value.
key (resp. value) is constructed from the provided args keyargs (resp. valargs) if not provided.
keyargs (resp. valargs) shall therefore match one of the constructor provided
by the EMPLACE_TYPE operator of the key (resp. the value).
There is:
- one generated method per suffix defined in the
EMPLACE_TYPEoperator of the key, - one generated method per suffix defined in the
EMPLACE_TYPEoperator of the value, - one generated method per pair of suffix defined in the
EMPLACE_TYPEoperators of the key and value,
The suffix in the generated method name corresponds to the suffix defined in
in the EMPLACE_TYPE operator (it can be empty).
This method is created only if one EMPLACE_TYPE operator is provided.
See emplace chapter for more details.
type_t *name_get(const name_t container, size_t key) [for sequence-like]
const type_t *name_cget(const name_t container, size_t key) [for sequence-like]
type_t *name_get(const name_t container, const type_t key) [for set-like]
const type_t *name_cget(const name_t container, const type_t key) [for set-like]
value_type_t *name_get(const name_t container, const key_type_t key) [for associative array]
const value_type_t *name_cget(const name_t container, const key_type_t key) [for associative array]
Return a modifiable (resp. constant) pointer to
the element associated to key in the container.
If the container is sequence-like, the key is an integer.
The selected element is the key-th element of the container,
the front being at the index 0, the last at the index (size-1).
The index key shall be within the size of the container.
Therefore, it will never return NULL in this case.
If the container is associative array like,
the selected element is the value object associated to the key object in the container.
If the key is not found, it returns NULL.
If the container is set-like,
the selected element is the value object which is equal to the key object in the container.
If the key is not found, it returns NULL.
This pointer remains valid until the container is modified by another method. This pointer should not be stored in a global variable.
type_t *name_get_emplace[suffix](const name_t container, args...) [for set-like]
value_type_t * name_get_emplace[suffix](name_t container, args...) [for associative array]
Return a modifiable (resp. constant) pointer to
the element associated to the key constructed from args in the container.
The selected element is the value object associated to the key object in the container
for an associative array, or the element itself for a set.
If the key is not found, it returns NULL.
This pointer remains valid until the container is modified by another method. This pointer should not be stored in a global variable.
type_t *name_safe_get(name_t container, size_t key) [for sequence]
type_t *name_safe_get(name_t container, const type_t key) [for set]
value_type_t *name_safe_get(name_t container, const key_type_t key) [for associative array]
Return a modifiable pointer to
the element associated to key in the container,
creating a new element if it doesn't exist (ensuring therefore a safe get operation).
If the container is sequence-like, key_type_t is an alias for size_t and key an integer,
the selected element is the key-th element of the container.
If the element doesn't exist, the container size will be increased
if needed (creating new elements with the INIT operator),
which might increase the container to much in some cases.
The returned pointer cannot be NULL.
This method is only created if the INIT method is provided.
This pointer remains valid until the array is modified by another method.
This pointer should not be stored in a global variable.
bool name_erase(name_t container, const size_t key)
bool name_erase(name_t container, const type_t key) [for set]
bool name_erase(name_t container, const key_type_t key) [for associative array]
Remove the element referenced by the key key in the container container.
Do nothing if key is no present in the container.
Return true if the key was present and erased, false otherwise.
size_t name_size(const name_t container)
Return the number elements of the container (its size). Return 0 if there is no element.
size_t name_capacity(const name_t container)
Return the capacity of the container, i.e. the maximum number of elements supported by the container before a reserve operation is needed to accommodate new elements.
void name_resize(name_t container, size_t size)
Resize the container container to the size size,
increasing or decreasing the size of the container
by initializing new elements or clearing existing ones.
This method is only created if the INIT method is provided.
void name_reserve(name_t container, size_t capacity)
Extend or reduce the capacity of the container to a rounded value based on capacity.
If the given capacity is below the current size of the container,
the capacity is set to a rounded value based on the size of the container.
Therefore a capacity of 0 is used to perform a shrink-to-fit operation on the container,
i.e. reducing the container usage to the minimum possible allocation.
void name_it(name_it_t it, const name_t container)
Set the iterator it to the first element of the container container.
There is no destructor associated to this initialization.
void name_it_set(name_it_t it, const name_it_t ref)
Set the iterator it to the iterator ref.
There is no destructor associated to this initialization.
void name_it_end(name_it_t it, const name_t container)
Set the iterator it to a non valid element of the container.
There is no destructor associated to this initialization.
bool name_end_p(const name_it_t it)
Return true if the iterator doesn't reference a valid element anymore.
bool name_last_p(const name_it_t it)
Return true if the iterator references the last element of the container or if the iterator doesn't reference a valid element anymore.
bool name_it_equal_p(const name_it_t it1, const name_it_t it2)
Return true if the iterator it1 references the same element than the iterator it2.
void name_next(name_it_t it)
Move the iterator to the next element of the container.
void name_previous(name_it_t it)
Move the iterator it to the previous element of the container.
type_t *name_ref(name_it_t it)
const type_t *name_cref(const name_it_t it)
name_itref_t *name_ref(name_it_t it) [for associative array]
const name_itref_t *name_cref(name_it_t it) [for associative array]
Return a modifiable (resp. constant) pointer to the element pointed by the iterator.
For associative-array like container, this element is the pair composed of
the key (key field) and the associated value (value field);
otherwise this element is simply the basic type of the container (type_t).
This pointer should not be stored in a global variable. This pointer remains valid until the container is modified by another method.
void name_insert(name_t container, const name_it_t it, const type_t x)
Insert the object x after the position referenced by the iterator it in the container container
or if the iterator it doesn't reference anymore to a valid element of the container,
it is added as the first element of the container.
it shall be an iterator of the container container.
void name_remove(name_t container, name_it_t it)
Remove the element referenced by the iterator it from the container container.
it shall be an iterator of the container container.
Afterwards, it references the next element of the container if it exists,
or not a valid element otherwise.
bool name_equal_p(const name_t container1, const name_t container2)
Return true if both containers container1 and container2 are considered equal.
This method is only created if the EQUAL method is provided.
size_t name_hash(const name_t container)
Return a fast hash value of the container container,
suitable to be used by a dictionary.
This method is only created if the HASH method is provided.
void name_get_str(string_t str, const name_t container, bool append)
Set str to the formatted string representation of the container container if append is false
or append str with this representation if append is true.
This method is only created if the GET_STR method is provided.
bool name_parse_str(name_t container, const char str[], const char **endp)
Parse the formatted string str,
that is assumed to be a string representation of a container,
and set container to this representation.
It returns true if success, false otherwise.
If endp is not NULL, it sets *endp to the pointer of the first character not
decoded by the function (or where the parsing fails).
This method is only created if the PARSE_STR & INIT methods are provided.
It is ensured that the container gets from parsing a formatted string representation
gets from name_get_str and the original container are equal.
void name_out_str(FILE *file, const name_t container)
Generate a formatted string representation of the container container
and outputs it into the file FILE*.
The file FILE* shall be opened in write text mode and without error.
This method is only created if the OUT_STR methods is provided.
bool name_in_str(name_t container, FILE *file)
Read from the file FILE* a formatted string representation of a container
and set container to this representation.
It returns true if success, false otherwise.
This method is only created if the IN_STR & INIT methods are provided.
It is ensured that the container gets from parsing a formatted string representation gets from name_out_str and the original container are equal.
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
Output the container container into the serializing object serial.
How and where it is output depends on the serializing object.
It returns M_SERIAL_OK_DONE in case of success,
or M_SERIAL_FAILURE in case of failure.
In case of failure, the serializing object is in an unspecified but valid state.
This method is only created if the OUT_SERIAL methods is provided.
m_serial_return_code_t name_in_serial(name_t container, m_serial_read_t serial)
Read from the serializing object serial a representation of a container
and set container to this representation.
It returns M_SERIAL_OK_DONE in case of success,
or M_SERIAL_FAILURE in case of failure.
In case of failure, the serializing object is in an unspecified but valid state.
This method is only created if the IN_SERIAL & INIT methods are provided.
It is ensured that the container gets from parsing a representation gets from name_out_serial and the original container are equal (using the same type of serialization object).
M-LIST
This header is for creating singly linked list.
A linked list is a linear collection of elements, in which each element points to the next, all of then representing a sequence.
A fundamental property of a list is that the objects created within the list will remain at their initialized address, and won't moved due to operations done on the list (except if it is removed). Therefore a returned pointer to an element of the container remains valid until this element is destroyed in the container.
LIST_DEF(name, type [, oplist])
LIST_DEF_AS(name, name_t, name_it_t, type [, oplist])
LIST_DEF defines the singly linked list named name_t
that contains objects of type type and their associated methods as static inline functions.
name shall be a C identifier that will be used to identify the list.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The oplist shall have at least the following operators (INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
For this container, the back is always the first element, and the front is the last element: the list grows from the back. Therefore, the iteration of this container using iterator objects will go from the back element to the front element (contrary to an array).
Even if it provides random access functions, theses access are slow and should be avoided: it iterates linearly over all the elements of the container until it reaches the requested element. The size method has the same drawback.
The push/pop methods of the container always operate on the back of the container.
LIST_DEF_AS is the same as LIST_DEF
except the name of the types name_t, name_it_t are provided by the user,
and not computed from the name prefix.
Example:
#include <stdio.h>
#include <gmp.h>
#include "m-list.h"
#define MPZ_OUT_STR(stream, x) mpz_out_str(stream, 0, x)
LIST_DEF(list_mpz, mpz_t, \
(INIT(mpz_init), INIT_SET(mpz_init_set), SET(mpz_set), \
CLEAR(mpz_clear), OUT_STR(MPZ_OUT_STR)))
int main(void) {
list_mpz_t a;
list_mpz_init(a);
mpz_t x;
mpz_init_set_ui(x, 16);
list_mpz_push_back (a, x);
mpz_set_ui(x, 45);
list_mpz_push_back (a, x);
mpz_clear(x);
printf ("LIST is: ");
list_mpz_out_str(stdout, a);
printf ("\n");
printf ("First element is: ");
mpz_out_str(stdout, 0, *list_mpz_back(a));
printf ("\n");
list_mpz_clear(a);
}
If the given oplist contain the method MEMPOOL, then LIST_DEF macro will create
a dedicated mempool that is named with the given value of the method MEMPOOL.
This mempool (see mempool chapter) is optimized for this kind of list:
- it creates a mempool named by the concatenation of
nameand_mempool, - it creates a variable named by the value of the method
MEMPOOLwith the linkage defined by the value of the methodMEMPOOL_LINKAGE(can be extern, static or none). This variable is shared by all lists of the same type. - it links the memory allocation of the list to use this mempool with this variable.
mempool create heavily efficient list. However, it is only worth the
effort in some heavy performance context.
Using mempool should be therefore avoided except in performance critical code.
The created mempool has to be explicitly initialized before using any
methods of the created list by calling mempool_list_name_init(variable)
and cleared by calling mempool_list_name_clear(variable).
Example:
LIST_DEF(list_uint, unsigned int, (MEMPOOL(list_mpool), MEMPOOL_LINKAGE(static)))
static void test_list (size_t n)
{
list_uint_mempool_init(list_mpool);
M_LET(a1, LIST_OPLIST(uint)) {
for(size_t i = 0; i < n; i++)
list_uint_push_back(a1, rand_get() );
}
list_uint_mempool_clear(list_mpool);
}
LIST_OPLIST(name [, oplist])
Return the oplist of the list defined by calling LIST_DEF
and LIST_DUAL_PUSH_DEF with name & oplist.
If there is no given oplist, the basic oplist for basic C types is used.
There is no globally registered oplist support.
LIST_INIT_VALUE()
Define an initial value that is suitable to initialize global variable(s)
of type list as created by LIST_DEF or LIST_DEF_AS.
It enables to create a list as a global variable and to initialize it.
The list shall still be cleared manually to avoid leaking memory.
Example:
LIST_DEF(list_int, int)
list_int_t my_list = LIST_INIT_VALUE();
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the list of type objects.
name_it_t
Type of an iterator over this list.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t list)
void name_init_set(name_t list, const name_t ref)
void name_set(name_t list, const name_t ref)
void name_init_move(name_t list, name_t ref)
void name_move(name_t list, name_t ref)
void name_clear(name_t list)
void name_reset(name_t list)
type *name_back(const name_t list)
void name_push_back(name_t list, const type value)
type *name_push_raw(name_t list)
type *name_push_new(name_t list)
void name_push_move(name_t list, type *value)
void name_emplace_back[suffix](name_t list, args...)
void name_pop_back(type *data, name_t list)
void name_pop_move(type *data, name_t list)
bool name_empty_p(const name_t list)
void name_swap(name_t list1, name_t list2)
void name_it(name_it_t it, const name_t list)
void name_it_set(name_it_t it, const name_it_t ref)
void name_it_end(name_it_t it, const name_t list)
bool name_end_p(const name_it_t it)
bool name_last_p(const name_it_t it)
bool name_it_equal_p(const name_it_t it1, const name_it_t it2)
void name_next(name_it_t it)
type *name_ref(name_it_t it)
const type *name_cref(const name_it_t it)
type *name_get(const name_t list, size_t i)
const type *name_cget(const name_t list, size_t i)
size_t name_size(const name_t list)
void name_insert(name_t list, const name_it_t it, const type x)
void name_remove(name_t list, name_it_t it)
void name_get_str(string_t str, const name_t list, bool append)
bool name_parse_str(name_t list, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t list)
bool name_in_str(name_t list, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
bool name_equal_p(const name_t list1, const name_t list2)
size_t name_hash(const name_t list)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_splice_back(name_t list1, name_t list2, name_it_t it)
Move the element referenced by the iterator it
from the list list2 to the back position of the list list1.
it shall be an iterator of list2.
Afterwards, it references the next element of the list if it exists,
or not a valid element otherwise.
void name_splice_at(name_t list1, name_it_t it1, name_t list2, name_it_t it2)
Move the element referenced by the iterator it2 from the list list2
to the position just after it1 in the list list1.
(If it1 is not a valid position, it inserts it at the back just like name_insert).
it1 shall be an iterator of list1.
it2 shall be an iterator of list2.
Afterwards, it2 references the next element of the list if it exists,
or not a valid element otherwise,
and it1 references the inserted element in list1.
void name_splice(name_t list1, name_t list2)
Move all the element of the list list2 into the list list1,
moving the last element of list2 after the first element of list1.
Afterwards, list2 remains initialized but is emptied.
void name_reverse(name_t list)
Reverse the order of the list.
LIST_DUAL_PUSH_DEF(name, type[, oplist])
LIST_DUAL_PUSH_DEF_AS(name, name_t, name_it_t, type [, oplist])
LIST_DUAL_PUSH_DEF defines the singly linked list named name_t
that contains the objects of type type and their associated methods as static inline functions.
The only difference with the list defined by LIST_DEF is
the support of the method for PUSH_FRONT in addition to the one for PUSH_BACK
(so the DUAL_PUSH name).
However, there is still only POP method (associated to POP_BACK).
The list is a bit bigger to be able to handle such method to work, but not the nodes.
This list is therefore able to represent:
- either a stack (
PUSH_BACK+POP_BACK) - or a queue (
PUSH_FRONT+POP_BACK).
LIST_DUAL_PUSH_DEF_AS is the same as LIST_DUAL_PUSH_DEF
except the name of the types name_t, name_it_t are provided by the user.
See LIST_DEF for more details and constraints.
Example:
#include <stdio.h>
#include <gmp.h>
#include "m-list.h"
#define MPZ_OUT_STR(stream, x) mpz_out_str(stream, 0, x)
LIST_DUAL_PUSH_DEF(list_mpz, mpz_t, \
(INIT(mpz_init), INIT_SET(mpz_init_set), SET(mpz_set), \
CLEAR(mpz_clear), OUT_STR(MPZ_OUT_STR)))
int main(void) {
list_mpz_t a;
list_mpz_init(a);
mpz_t x;
mpz_init_set_ui(x, 16);
list_mpz_push_back (a, x);
mpz_set_ui(x, 45);
list_mpz_push_back (a, x);
mpz_clear(x);
printf ("LIST is: ");
list_mpz_out_str(stdout, a);
printf ("\n");
printf ("First element is: ");
mpz_out_str(stdout, 0, *list_mpz_back(a));
printf ("\n");
list_mpz_clear(a);
}
The methods follow closely the methods defined by LIST_DEF.
LIST_DUAL_PUSH_INIT_VALUE()
Define an initial value that is suitable to initialize global variable(s)
of type list as created by LIST_DUAL_PUSH_DEF or LIST_DUAL_PUSH_DEF_AS.
It enables to create a list as a global variable and to initialize it.
The list should still be cleared manually to avoid leaking memory.
Example:
LIST_DUAL_PUSH_DEF(list_int, int)
list_int_t my_list = LIST_DUAL_PUSH_INIT_VALUE();
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the list of type.
name_it_t
Type of an iterator over this list.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t list)
void name_init_set(name_t list, const name_t ref)
void name_set(name_t list, const name_t ref)
void name_init_move(name_t list, name_t ref)
void name_move(name_t list, name_t ref)
void name_clear(name_t list)
void name_reset(name_t list)
type *name_back(const name_t list)
void name_push_back(name_t list, type value)
type *name_push_back_raw(name_t list)
type *name_push_back_new(name_t list)
void name_push_back_move(name_t list, type *value)
void name_emplace_back[suffix](name_t list, args...)
const type *name_front(const name_t list)
void name_push_front(name_t list, type value)
type *name_push_front_raw(name_t list)
type *name_push_front_new(name_t list)
void name_push_front_move(name_t list, type *value)
void name_emplace_front[suffix](name_t list, args...)
void name_pop_back(type *data, name_t list)
void name_pop_move(type *data, name_t list)
bool name_empty_p(const name_t list)
void name_swap(name_t list1, name_t list2)
void name_it(name_it_t it, name_t list)
void name_it_set(name_it_t it, const name_it_t ref)
void name_it_end(name_it_t it, const name_t list)
bool name_end_p(const name_it_t it)
bool name_last_p(const name_it_t it)
bool name_it_equal_p(const name_it_t it1, const name_it_t it2)
void name_next(name_it_t it)
type *name_ref(name_it_t it)
const type *name_cref(const name_it_t it)
size_t name_size(const name_t list)
void name_insert(name_t list, const name_it_t it, const type x)
void name_remove(name_t list, name_it_t it)
void name_get_str(string_t str, const name_t list, bool append)
bool name_parse_str(name_t list, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t list)
bool name_in_str(name_t list, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
bool name_equal_p(const name_t list1, const name_t list2)
size_t name_hash(const name_t list)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_splice_back(name_t list1, name_t list2, name_it_t it)
Move the element pointed by it
from the list list2 to the back position of the list list1.
it shall be an iterator of list2.
Afterwards, it points to the next element of list2.
void name_splice(name_t list1, name_t list2)
Move all the element of the list list2 into the list list1,
moving the last element of list2 after the first element of list1.
Afterwards, list2 is emptied.
void name_reverse(name_t list)
Reverse the order of the list.
M-ARRAY
An array is a growable collection of element that are individually indexable.
ARRAY_DEF(name, type [, oplist])
ARRAY_DEF_AS(name, name_t, name_it_t, type [, oplist])
ARRAY_DEF defines the array name_t that contains the objects of type type
in a sequence
and its associated methods as static inline functions.
Compared to C arrays, the created methods handle automatically the size (aka growable array).
name shall be a C identifier that will be used to identify the container.
It will be used to create all the types (including the iterator)
and functions to handle the container.
The provided oplist shall have at least the following operators (CLEAR).
It should also provide the following operators (INIT, INIT_SET, SET),
so that at least some methods are defined for the array!
The push / pop methods of the container always operate on the back of the container, acting like a stack-like container.
ARRAY_DEF_AS is the same as ARRAY_DEF except the name of the types name_t, name_it_t
are provided by the user.
Example:
#include <stdio.h>
#include <gmp.h>
#include "m-array.h"
#define MPZ_OUT_STR(stream, x) mpz_out_str(stream, 0, x)
ARRAY_DEF(array_mpz, mpz_t, \
(INIT(mpz_init), INIT_SET(mpz_init_set), SET(mpz_set), \
CLEAR(mpz_clear), OUT_STR(MPZ_OUT_STR)))
int main(void) {
array_mpz_t a;
array_mpz_init(a);
mpz_t x;
mpz_init_set_ui(x, 16);
array_mpz_push_back (a, x);
mpz_set_ui(x, 45);
array_mpz_push_back (a, x);
mpz_clear(x);
printf ("ARRAY is: ");
array_mpz_out_str(stdout, a);
printf ("\n");
printf ("First element is: ");
mpz_out_str(stdout, 0, *array_mpz_get(a, 0));
printf ("\n");
array_mpz_clear(a);
}
ARRAY_OPLIST(name [, oplist])
Return the oplist of the array defined by calling ARRAY_DEF with name & oplist.
If there is no given oplist, the basic oplist for basic C types is used.
ARRAY_INIT_VALUE()
Define an initial value that is suitable to initialize global variable(s)
of type array as created by ARRAY_DEF or ARRAY_DEF_AS.
It enables to create an array as a global variable and to initialize it.
The array should still be cleared manually to avoid leaking memory.
Example:
ARRAY_DEF(array_int_t, int)
array_int_t my_array = ARRAY_INIT_VALUE();
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the array of type.
name_it_t
Type of an iterator over this array.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t array)
void name_init_set(name_t array, const name_t ref)
void name_set(name_t array, const name_t ref)
void name_init_move(name_t array, name_t ref)
void name_move(name_t array, name_t ref)
void name_clear(name_t array)
void name_reset(name_t array)
type *name_push_raw(name_t array)
void name_push_back(name_t array, const type value)
type *name_push_new(name_t array)
void name_push_move(name_t array, type *val)
void name_emplace_back[suffix](name_t array, args...)
void name_pop_back(type *data, name_t array)
void name_pop_move(type *data, name_t array)
type *name_front(const name_t array)
type *name_back(const name_t array)
void name_set_at(name_t array, size_t i, type value)
type *name_get(name_t array, size_t i)
const type *name_cget(const name_t it, size_t i)
type *name_safe_get(name_t array, size_t i)
bool name_empty_p(const name_t array)
size_t name_size(const name_t array)
size_t name_capacity(const name_t array)
void name_resize(name_t array, size_t size)
void name_reserve(name_t array, size_t capacity)
void name_swap(name_t array1, name_t array2)
void name_it(name_it_t it, name_t array)
void name_it_last(name_it_t it, name_t array)
void name_it_end(name_it_t it, name_t array)
void name_it_set(name_it_t it1, name_it_t it2)
bool name_end_p(name_it_t it)
bool name_last_p(name_it_t it)
bool name_it_equal_p(const name_it_t it1, const name_it_t it2)
void name_next(name_it_t it)
void name_previous(name_it_t it)
type *name_ref(name_it_t it)
const type *name_cref(const name_it_t it)
void name_remove(name_t array, name_it_t it)
void name_insert(name_t array, name_it_t it, const type x)
void name_get_str(string_t str, const name_t array, bool append)
bool name_parse_str(name_t array, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t array)
bool name_in_str(name_t array, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
bool name_equal_p(const name_t array1, const name_t array2)
size_t name_hash(const name_t array)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_push_at(name_t array, size_t key, const type x)
Push a new element into the position key of the array array
with the value value.
All elements after the position key (included) will be moved in the array towards the back,
and the array will have one more element.
key shall be a valid position of the array: from 0 to the size of array (included).
This method is created only if the INIT_SET operator is provided.
void name_pop_until(name_t array, array_it_t position)
Pop all elements of the array array from 'position' to the back of the array,
while clearing them.
This method is created only if the INIT operator is provided.
void name_pop_at(type *dest, name_t array, size_t key)
Set *dest to the value the element key if dest is not NULL,
then remove the element key from the array (decreasing the array size).
key shall be within the size of the array.
This method is created only if the SET or INIT_MOVE operator is provided.
void name_remove_v(name_t array, size_t i, size_t j)
Remove the element i (included) to the element j (excluded)
from the array.
i and j shall be within the size of the array, and i < j.
void name_insert_v(name_t array, size_t i, size_t j)
Insert from the element i (included) to the element j (excluded)
new empty elements to the array.
i and j shall be within the size of the array, and i < j.
This method is only defined if the type of the element defines an INIT method.
void name_swap_at(name_t array, size_t i, size_t j)
Swap the elements i and j of the array array.
i and j shall reference valid elements of the array.
This method is created if the INIT_SET or INIT_MOVE operator is provided.
void name_special_sort(name_t array)
Sort the array array.
This method is defined if the type of the element defines CMP method.
This method uses the qsort function of the C library.
void name_special_stable_sort(name_t array)
Sort the array array using a stable sort.
This method is defined if the type of the element defines CMP and SWAP and SET methods.
This method provides an ad-hoc implementation of the stable sort.
In practice, it is faster than the _sort method for small types and fast
comparisons.
void name_splice(name_t array1, name_t array2)
Move all the elements of the array array2 to the end of the array array1.
Afterwards, array2 is empty.
M-DEQUE
This header is for creating double-ended queue (or deque). A deque is an abstract data type that generalizes a queue, for that elements can be added to or removed from either the front (head) or back (tail)
DEQUE_DEF(name, type [, oplist])
DEQUE_DEF_AS(name, name_t, name_it_t, type [, oplist])
DEQUE_DEF defines the deque name_t that contains the objects of type type and its associated methods as static inline functions.
name shall be a C identifier that will be used to identify the deque.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The oplist shall have at least the following operators (INIT, INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
The algorithm complexity to access random elements is in O(ln(n)). Removing an element may unbalance the deque, which breaks the promise of algorithm complexity for the _get method.
DEQUE_DEF_AS is the same as DEQUE_DEF
except the name of the types name_t, name_it_t are provided.
Example:
#include <stdio.h>
#include <gmp.h>
#include "m-deque.h"
DEQUE_DEF(deque_mpz, mpz_t, \
(INIT(mpz_init), INIT_SET(mpz_init_set), SET(mpz_set), CLEAR(mpz_clear)))
int main(void) {
deque_mpz_t a;
deque_mpz_init(a);
mpz_t x;
mpz_init_set_ui(x, 16);
deque_mpz_push_back (a, x);
mpz_set_ui(x, 45);
deque_mpz_push_front (a, x);
deque_mpz_pop_back(&x, a);
mpz_set_ui(x, 5);
deque_mpz_push_back (a, x);
mpz_clear(x);
printf ("First element is: ");
mpz_out_str(stdout, 0, *deque_mpz_front(a));
printf ("\n");
printf ("Last element is: ");
mpz_out_str(stdout, 0, *deque_mpz_back(a));
printf ("\n");
deque_mpz_clear(a);
}
DEQUE_OPLIST(name [, oplist])
Return the oplist of the deque defined by calling DEQUE_DEF with name oplist.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the deque of type.
name_it_t
Type of an iterator over this deque.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t deque)
void name_init_set(name_t deque, const name_t ref)
void name_set(name_t deque, const name_t ref)
void name_init_move(name_t deque, name_t ref)
void name_move(name_t deque, name_t ref)
void name_clear(name_t deque)
void name_reset(name_t deque)
type *name_back(const name_t deque)
void name_push_back(name_t deque, type value)
type *name_push_back_raw(name_t deque)
type *name_push_back_new(name_t deque)
void name_emplace_back[suffix](name_t list, args...)
void name_pop_back(type *data, name_t deque)
type *name_front(const name_t deque)
void name_push_front(name_t deque, type value)
type *name_push_front_raw(name_t deque)
type *name_push_front_new(name_t deque)
void name_emplace_front[suffix](name_t list, args...)
void name_pop_front(type *data, name_t deque)
bool name_empty_p(const name_t deque)
void name_swap(name_t deque1, name_t deque2)
void name_it(name_it_t it, name_t deque)
void name_it_set(name_it_t it, const name_it_t ref)
bool name_end_p(const name_it_t it)
bool name_last_p(const name_it_t it)
bool name_it_equal_p(const name_it_t it1, const name_it_t it2)
void name_next(name_it_t it)
void name_previous(name_it_t it)
type *name_ref(name_it_t it)
const type *name_cref(const name_it_t it)
void name_remove(name_t deque, name_it_t it)
type *name_get(const name_t deque, size_t i)
const type *name_cget(const name_t deque, size_t i)
size_t name_size(const name_t deque)
void name_get_str(string_t str, const name_t deque, bool append)
bool name_parse_str(name_t deque, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t deque)
bool name_in_str(name_t deque, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
bool name_equal_p(const name_t deque1, const name_t deque2)
size_t name_hash(const name_t deque)
void name_swap_at(name_t deque, size_t i, size_t j)
M-DICT
A dictionary (or associative array, map, symbol table) is an abstract data type composed of a collection of (key, value) pairs, such that each possible key appears at most once in the collection, and is associated to only one value. It is possible to search for a key in the dictionary and get back its value.
Several dictionaries are proposed. The "best" to use depends on the data type
and in particular the size of the data.
For very small, fast types (integer, or floats, or pair of such types),
DICT_OA_DEF2 may be the best to use (but slightly more complex to instantiate).
However DICT_DEF2 should be good enough for all scenarios.
DICT_DEF2(name, key_type[, key_oplist], value_type[, value_oplist])
DICT_DEF2_AS(name, name_t, name_it_t, name_itref_t, key_type[, key_oplist], value_type[, value_oplist])
DICT_DEF2 defines the dictionary name_t and its associated methods as static inline functions as an associative array of key_type to value_type.
name shall be a C identifier that will be used to identify the dictionary.
It will be used to create all the types (including the iterator and the iterated object type)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
Both oplist shall have at least the following operators (INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
The key_oplist shall also define the additional operators (HASH and EQUAL).
Elements in the dictionary are unordered. On insertion of a new element, contained objects may moved. Maximum number of elements of this dictionary is 3'006'477'107 elements.
The _set_at method overwrites the already existing value if key is already present in the dictionary
(contrary to C++).
The iterated object type name##_itref_t is a pair of key_type and value_type.
What is exactly the "first" element for the iteration is not specified. It is only ensured that all elements of the dictionary are explored by going from "first" to "end".
DICT_DEF2_AS is the same as DICT_DEF2
except the name of the types name_t, name_it_t, name_itref_t are provided.
Example:
#include <stdio.h>
#include "m-string.h"
#include "m-dict.h"
DICT_DEF2(dict_string, string_t, unsigned)
int main(void) {
dict_string_t a;
dict_string_init(a);
string_t x;
string_init_set_str(x, "This is an example");
dict_string_set_at (a, x, 1);
string_set_str(x, "This is an another example");
dict_string_set_at (a, x, 2);
string_set_str(x, "This is an example");
unsigned *val = dict_string_get(a, x);
printf ("Value of %s is %u\n", string_get_cstr(x), *val);
string_clear(x);
printf ("Dictionary is: ");
dict_string_out_str(stdout, a);
printf ("\n");
dict_string_clear(a);
}
DICT_OA_DEF2(name, key_type[, key_oplist], value_type[, value_oplist])
DICT_OA_DEF2_AS(name, name_t, name_it_t, name_itref_t, key_type[, key_oplist], value_type[, value_oplist])
DICT_OA_DEF2 defines the dictionary name_t and its associated methods
as static inline functions much like DICT_DEF2.
The difference is that it uses an Open Addressing Hash-Table as container
that stores the data with the table.
The key_oplist shall also define the additional operators:
OOR_EQUAL and OOR_SET
The Out-Of-Range operators (OOR_EQUAL and OOR_SET) are used to store uninitialized keys
in the dictionary and be able to detect it. This enables avoiding a separate bit-field
to know the state of the entry in the dictionary (which increases memory
usage and is cache unfriendly).
The elements may move when inserting / deleting other elements (and not just the iterators).
This implementation is in general faster for small types of keys (like integer or float) but are slower for larger types.
DICT_OA_DEF2_AS is the same as DICT_OA_DEF2
except the name of the types name_t, name_it_t, name_itref_t are provided.
Example:
#include <stdio.h>
#include "m-string.h"
#include "m-dict.h"
// Define an Out Of Range equal function
static inline bool oor_equal_p(unsigned k, unsigned char n) {
return k == (unsigned)(-n-1);
}
// Define an Out Of Range function
static inline void oor_set(unsigned *k, unsigned char n) {
*k = (unsigned)(-n-1);
}
DICT_OA_DEF2(dict_unsigned, unsigned, M_OPEXTEND(M_BASIC_OPLIST,
OOR_EQUAL(oor_equal_p), OOR_SET(API_2(oor_set))), long long, M_BASIC_OPLIST)
unsigned main(void) {
dict_unsigned_t a;
dict_unsigned_init(a);
dict_unsigned_set_at (a, 13566, 14890943049);
dict_unsigned_set_at (a, 656, -2);
long long *val = dict_unsigned_get(a, 458);
printf ("Value of %d is %p\n", 458, val); // Not found value
val = dict_unsigned_get(a, 656);
printf ("Value of %d is %lld\n", 656, *val);
dict_unsigned_clear(a);
}
DICT_OPLIST(name[, key_oplist, value_oplist])
Return the oplist of the dictionary defined by calling any DICT_*_DEF2 with name, key_oplist, value_oplist.
DICT_SET_DEF(name, key_type[, key_oplist])
DICT_SET_DEF_AS(name, name_t, name_it_t, key_type[, key_oplist])
DICT_SET_DEF defines the dictionary set name_t and its associated methods as static inline functions.
A dictionary set is a specialized version of a dictionary with no value (only keys).
name shall be a C identifier that will be used to identify the dictionary.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The oplist shall have at least the following operators (INIT_SET, SET, CLEAR, HASH and EQUAL),
otherwise it won't generate compilable code.
The _push method will overwrite the already existing value if key is already present in the dictionary (contrary to C++).
What is exactly the "first" element for the iteration is not specified. It is only ensured that all elements of the dictionary are explored by going from "first" to "end".
DICT_SET_DEF_AS is the same as DICT_SET_DEF
except the name of the types name_t, name_it_t are provided.
Example:
#include <stdio.h>
#include "m-string.h"
#include "m-dict.h"
DICT_SET_DEF(set_string, double)
unsigned main(void) {
set_string_t a;
set_string_init(a);
set_string_push (a, 13566);
set_string_push (a, 656);
double *val = set_string_get(a, 458);
printf ("Value of %d is %p\n", 458, val); // Not found value
val = set_string_get(a, 656);
printf ("Value of %d is %f\n", 656, *val);
printf("Set is ");
set_string_out_str(stdout, a);
printf("\n");
set_string_clear(a);
}
DICT_OASET_DEF(name, key_type[, key_oplist])
DICT_OASET_DEF_AS(name, name_t, name_it_t, key_type[, key_oplist])
DICT_OASET_DEF defines the dictionary set name_t and its associated methods as static inline functions just like DICT_SET_DEF.
The difference is that it uses an Open Addressing Hash-Table as container.
The key_oplist shall also define the additional operators:
OOR_EQUAL and OOR_SET
The elements may move when inserting / deleting other elements (and not just the iterators).
This implementation is in general faster for small types of keys (like integer) but slower for larger types.
DICT_OASET_DEF_AS is the same as DICT_OASET_DEF
except the name of the types name_t, name_it_t are provided.
DICT_SET_OPLIST(name[, key_oplist])
Return the oplist of the set defined by calling DICT_SET_DEF (or DICT_OASET_DEF) with name and key_oplist.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the dictionary which
- either associate
key_typetovalue_type, - or store unique element
key_type.
name_it_t
Type of an iterator over this dictionary.
name_itref_t [only for associative array]
Type of one item referenced in the dictionary for associative array.
It is a structure composed of the key (field key) and the value (field value).
This type is created only for associative arrays (_DEF2 suffix) and not for sets.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t dict)
void name_clear(name_t dict)
void name_init_set(name_t dict, const name_t ref)
void name_set(name_t dict, const name_t ref)
void name_init_move(name_t dict, name_t ref)
void name_move(name_t dict, name_t ref)
void name_reset(name_t dict)
size_t name_size(const name_t dict)
bool name_empty_p(const name_t dict)
value_type *name_get(const name_t dict, const key_type key)
value_type_t * name_get_emplace[suffix](name_t container, args...)
value_type *name_safe_get(name_t dict, const key_type key)
void name_set_at(name_t dict, const key_type key, const value_type value) /* for associative array */
void name_push(name_t dict, const key_type key) /* for dictionary set */
bool name_erase(name_t dict, const key_type key)
void name_it(name_it_t it, name_t dict)
void name_it_set(name_it_t it, const name_it_t ref)
bool name_end_p(const name_it_t it)
bool name_last_p(const name_it_t it)
void name_next(name_it_t it)
name_itref_t *name_ref(name_it_t it) /* for associative array */
key_type *name_ref(name_it_t it) /* for dictionary set */
const name_itref_t *name_cref(name_it_t it) /* for associative array */
const key_type *name_cref(name_it_t it) /* for dictionary set */
void name_get_str(string_t str, const name_t dict, bool append)
bool name_parse_str(name_t dict, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t dict)
bool name_in_str(name_t dict, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
bool name_equal_p(const name_t dict1, const name_t dict2)
void name_emplace[suffix](name_t container, keyargs...) [for dictionary set */
void name_emplace_key[keysuffix]_val[valsuffix](name_t container, keyargs..., valargs...) /* for associative array */
void name_reserve(name_t dict, size_t capacity)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_splice(name_t dict1, name_t dict2)
Move all items from dict2 into dict1.
If there is the same key between dict2 into dict1,
then their values are added (as per the ADD method of the value type).
Afterward dict2 is reset (i.e. empty).
This method is only defined if the value type defines an ADD method.
M-TUPLE
A tuple is a finite ordered list of elements of different types.
TUPLE_DEF2(name, (element1, type1[, oplist1]) [, ...])
TUPLE_DEF2_AS(name, name_t, (element1, type1[, oplist1]) [, ...])
TUPLE_DEF2 defines the tuple name_t and its associated methods as static inline functions.
Each parameter of the macro is expected to be an element of the tuple.
Each element is defined by three parameters within parenthesis:
- the element name (the field name of the structure)
- the element type (the associated type)
- and the optional element oplist associated to this type (see generic interface for the behavior if it is absent)
name and element shall be C identifiers that will be used to identify the container and the fields.
It will be used to create all the types (including the iterator) and functions to handle the container. This definition shall be done once per name and per compilation unit.
This is more or less a C structure. The main added value compared to using a C struct is that it generates also all the basic methods to handle it which is quite handy.
The oplist shall have at least the following operators (INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
In general, an optional method of the tuple will only be created if all oplists define the needed optional methods for the underlying type.
The _hash (resp. _equal_p and _cmp) method is an exception.
This method is created only if at least one oplist of the tuple defines the HASH (resp. EQUAL) method.
You can disable the use of a specific field for the hash computation of the tuple
by disabling the HASH operator of such field (with HASH(0) in its oplist),
in which case it is coherent to also disable the EQUAL operator too.
Resp., you can disable the use of a field for the equality of the tuple
by disabling the EQUAL operator of such field (with EQUAL(0) in its oplist)
The comparison of two tuples uses lexicographic order of the fields defining the CMP method.
It is created only if at least one oplist of the tuple define CMP method.
You can disable the use of a field for the comparison of the tuple
by disabling the CMP operator of such field (with CMP(0) in its oplist)
TUPLE_DEF2_AS is the same as TUPLE_DEF2 except the name of the type name_t is provided.
Example:
#include <stdio.h>
#include <gmp.h>
#include "m-string.h"
#include "m-tuple.h"
#define MPZ_OUT_STR(stream, x) mpz_out_str(stream, 0, x)
TUPLE_DEF2(pair, (key_field, string_t, STRING_OPLIST), \
(value_field, mpz_t, M_OPEXTEND(M_CLASSIC_OPLIST(mpz), \
OUT_STR(MPZ_OUT_STR))))
int main(void) {
pair_t p1;
pair_init (p1);
string_set_str(p1->key_field, "HELLO");
mpz_set_str(p1->value_field, "1742", 10);
printf("The pair is ");
pair_out_str(stdout, p1);
printf("\n");
pair_clear(p1);
}
TUPLE_OPLIST(name, oplist1[, ...] )
Return the oplist of the tuple defined by calling TUPLE_DEF2 with the given name and the oplist.
Created types
The following type is automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the defined tuple.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t tuple)
void name_init_set(name_t tuple, const name_t ref)
void name_set(name_t tuple, const name_t ref)
void name_init_move(name_t tuple, name_t ref)
void name_move(name_t tuple, name_t ref)
void name_clear(name_t tuple)
void name_reset(name_t tuple)
void name_get_str(string_t str, const name_t tuple, bool append)
bool name_parse_str(name_t tuple, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t tuple)
bool name_in_str(name_t tuple, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
size_t name_hash(const name_t tuple)
int name_equal_p(const name_t tuple1, const name_t tuple2)
int name_cmp(const name_t tuple1, const name_t tuple2)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_init_emplace(name_t tuple, const type1 element1[, ...])
Initialize the tuple tuple (aka constructor) and set it to the value of the constructed tuple (element1[, ...]).
void name_emplace(name_t tuple, const type1 element1[, ...])
Set the tuple tuple to the value of the tuple constructed with (element1[, ...]).
const type1 *name_cget_at_element1(const name_t tuple)
Return a constant pointer to the element element1 of the tuple.
There is as many methods as there are elements.
type1 *name_get_at_element1(const name_t tuple)
Return a pointer to the element element1 of the tuple.
There is as many methods as there are elements.
void name_set_element1(name_t tuple, type1 element1)
Set the element of the tuple to element1
There is as many methods as there are elements.
int name_cmp_order(const name_t tuple1, const name_t tuple2, const int order[])
Compare tuple1 to tuple2 using the given order.
order is a NULL terminated array of int that defines the order of comparison:
an order of {1, 4, 2, 0} indicates to compare first the first field,
if it is equal, to compare the fourth and so on. The third field is not
compared. A negative value indicates to revert the comparison.
This method is created only if all oplist of the tuple define CMP method.
int name_cmp_element1(const name_t tuple1, const name_t tuple2)
Compare tuple1 to tuple2 using only the element element1 as reference.
This method is created only if the oplist of element1 defines the CMP method.
M-VARIANT
A variant is a finite exclusive list of elements of different types: the variant can only be equal to one element at a time.
VARIANT_DEF2(name, (element1, type1[, oplist1]) [, ...])
VARIANT_DEF2_AS(name, name_t, (element1, type1[, oplist1]) [, ...])
VARIANT_DEF2 defines the variant name_t and its associated methods as static inline functions.
Each parameter of the macro is expected to be an element of the variant.
Each element is defined by three parameters within parenthesis:
- the mandatory element name,
- the mandatory element type
- and the optional element oplist.
If an OPLIST is given, it shall be the one matching the associated type.
name and element<n> shall be C identifiers that will be used to identify the variant.
name will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
This is like a C union. The main added value compared to using a union
is that it generates all the basic methods to handle and it dynamically
identifies which element is stored within.
It is also able to store an EMPTY state for the variant, contrary to an union
(this is the state when default constructing it).
The oplists shall have at least the following operators (INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
In general, an optional method of the variant will only be created
if all oplists define the needed optional methods for the underlying type.
VARIANT_DEF2_AS is the same as VARIANT_DEF2 except the name of the type name_t
is provided.
name_parse_str and name_in_str depend also on the INIT operator.
Example:
#include <stdio.h>
#include "m-string.h"
#include "m-variant.h"
VARIANT_DEF2(item,
(name, string_t),
(age, long))
int main(void) {
item_t p1;
item_init (p1);
item_set_name(p1, STRING_CTE("HELLO"));
printf("The variant is ");
item_out_str(stdout, p1);
printf("\n");
item_set_age(p1, 43);
printf("The variant is now ");
item_out_str(stdout, p1);
printf("\n");
item_clear(p1);
}
VARIANT_OPLIST(name, oplist1[, ...] )
Return the oplist of the variant defined by calling VARIANT_DEF2 with the given name and the oplists used to generate it.
Created types
The following type is automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the defined variant.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t variant)
void name_init_set(name_t variant, const name_t ref)
void name_set(name_t variant, const name_t ref)
void name_init_move(name_t variant, name_t ref)
void name_move(name_t variant, name_t ref)
void name_clear(name_t variant)
void name_reset(name_t variant)
bool name_empty_p(const name_t variant)
size_t name_hash(const name_t variant)
bool name_equal_p(const name_t variant1, const name_t variant2)
void name_swap(name_t variant1, name_t variant2)
void name_get_str(string_t str, name_t variant, bool append)
bool name_parse_str(name_t variant, const char str[], const char **endp)
void name_out_str(FILE *file, name_t variant)
bool name_in_str(name_t variant, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_init_elementN(name_t variant)
Initialize the variant variant to the type of element1 [constructor]
using the default constructor of this element.
This method is defined if all methods define an INIT method.
void name_init_set_elementN(name_t variant, const typeN elementN)
Initialize the variant variant and set it to the type and value of elementN [constructor]
void name_move_elementN(name_t variant, typeN ref)
Set the variant variant by stealing as many resources from ref as possible.
Afterwards ref is cleared (destructor)
This method is created only if all oplist of the variant define MOVE method.
void name_set_elementN(name_t variant, const typeN elementN)
Set the variant variant to the type and value of elementN.
const typeN *name_cget_at_elementN(name_t variant)
Return a pointer to the variant viewed as of type typeN.
If the variant isn't an object of such type, it returns NULL.
typeN *name_get_at_elementN(name_t variant)
Return a pointer to the variant viewed as of type typeN.
If the variant isn't an object of such type, it returns NULL.
bool name_elementN_p(const name_t variant)
Return true if the variant is of the type of elementN.
M-RBTREE
A binary tree is a tree data structure in which each node has at most two children, which are referred to as the left child and the right child. A node without any child is called a leaf. It can be seen as an ordered set.
A R-B Tree is a tree where all elements are also totally ordered, and the worst-case of any operation is in logarithm of the number of elements in the tree. The current implementation is RED-BLACK TREE which provides performance guarantee for both insertion and lockup operations. It has not to be confused with a B-TREE.
RBTREE_DEF(name, type[, oplist])
RBTREE_DEF_AS(name, name_t, name_it_t, type[, oplist])
RBTREE_DEF defines the binary ordered tree name_t and its associated methods as static inline functions.
name shall be a C identifier that will be used to identify the R-B Tree.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The CMP operator is used to perform the total ordering of the elements.
The oplist shall have at least the following operators (INIT, INIT_SET, SET, CLEAR & CMP),
otherwise it won't generate compilable code.
Some methods may return a modifiable pointer to the found element
(for example, _get). In this case, the user shall not modify the
key order of the element, as there is no reordering of the tree
in this case.
A push method on the tree will put the given key in its right place in the tree
by keeping the tree ordered.
It overwrites the already existing value if the key is already present in the dictionary (contrary to C++).
RBTREE_DEF_AS is the same as RBTREE_DEF2 except the name of the types name_t, name_it_t are provided by the user.
Example:
RBTREE_DEF(rbtree_uint, unsigned int)
void f(unsigned int num) {
rbtree_uint_t tree;
rbtree_uint_init(tree);
for(unsigned int i = 0; i < num; i++)
rbtree_uint_push(tree, i);
rbtree_uint_clear(tree);
}
RBTREE_OPLIST(name [, oplist])
Return the oplist of the Red-Black tree defined by calling RBTREE_DEF with name and oplist.
If there is no given oplist, the basic oplist for basic C types is used.
Created types
The following types are automatically defined by the previous definition macro with name if not provided by the user:
name_t
Type of the Red Black Tree.
name_it_t
Type of an iterator over this Red Black Tree.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t rbtree)
void name_clear(name_t rbtree)
void name_init_set(name_t rbtree, const name_t ref)
void name_set(name_t rbtree, const name_t ref)
void name_init_move(name_t rbtree, name_t ref)
void name_move(name_t rbtree, name_t ref)
void name_reset(name_t rbtree)
size_t name_size(const name_t rbtree)
void name_push(name_t rbtree, const type data)
void name_emplace[suffix](name_t rbtree, args...)
type *name_get(const name_t rbtree, const type data)
const type *name_cget(const name_t rbtree, const type data)
void name_swap(name_t rbtree1, name_t rbtree2)
bool name_empty_p(const name_t rbtree)
void name_it(name_it_t it, name_t rbtree)
void name_it_set(name_it_t it, const name_it_t ref)
void name_it_last(name_it_t it, name_t rbtree)
void name_it_end(name_it_t it, name_t rbtree)
bool name_end_p(const name_it_t it)
bool name_last_p(const name_it_t it)
void name_it_remove(name_t rbtree, name_it_t it)
void name_next(name_it_t it)
void name_previous(name_it_t it)
type *name_ref(name_it_t it)
const type *name_ref(name_it_t it)
void name_get_str(string_t str, const name_t rbtree, bool append)
bool name_parse_str(name_t tree, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t rbtree)
bool name_in_str(name_t rbtree, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
bool name_equal_p(const name_t rbtree1, const name_t rbtree2)
size_t name_hash(const name_t rbtree)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_pop(type *dest, name_t rbtree, const type data)
Pop data from the Red Black Tree rbtree
and save the popped value into dest if the pointer is not null
while keeping the tree balanced.
Do nothing if data is no present in the Red Black Tree.
type * name_min(const name_t rbtree)
const type * name_cmin(const name_t rbtree)
Return a pointer to the minimum element of the tree or NULL if there is no element.
type * name_max(const name_t rbtree)
const type * name_cmax(const name_t rbtree)
Return a pointer to the maximum element of the tree or NULL if there is no element.
void name_it_from(name_it_t it, const name_t rbtree, const type data)
Set the iterator it to
the lowest element of the tree rbtree greater or equal than data
or an iterator to no element is there is none.
bool name_it_until_p(const name_it_t it, const type data)
Return true if it references an element that is greater or equal than data
or if it references no longer a valid element, false otherwise.
bool name_it_while_p(const name_it_t it, const type data)
Return true if it references an element that is lower or equal than data.
Otherwise (or if it references no longer a valid element) it returns false.
M-BPTREE
A B+TREE is a variant of BTREE that itself is a generalization of Binary Tree.
A B+TREE is an N-ary tree with a variable but often large number of children per node. It is mostly used for handling slow media by file system and database.
It provides a fully sorted container enabling fast access to individual item or range of items, and as such is concurrent to Red-Black Tree. On modern architecture, a B+TREE is typically faster than a red-black tree due to being more cache friendly (The RAM itself can be considered as a slow media nowadays!)
When defining a B+TREE it is necessary to give the type of the item within, but also
the maximum number of child per node (N). The best maximum number of child per node
depends on the type itself (its size, its compare cost) and the cache of the
processor.
BPTREE_DEF2(name, N, key_type, key_oplist, value_type, value_oplist)
BPTREE_DEF2_AS(name, name_t, name_it_t, name_itref_t, N, key_type, key_oplist, value_type, value_oplist)
Define the B+TREE tree of rank N name_t and its associated methods as
static inline functions. This B+TREE will be created as an associative
array of the key_type to the value_type.
The CMP operator is used to perform the total ordering of the key elements.
N is the number of items per node and shall be greater or equal than 2.
It shall be done once per type and per compilation unit.
It also define the iterator name##_it_t and its associated methods as static inline functions.
The object oplist shall have at least the operators (INIT, INIT_SET, SET, CLEAR and CMP).
BPTREE_DEF2_AS is the same as BPTREE_DEF2 except the name of the
container type name_t, the iterator type name_it_t, and the
iterated object type name_itref_t are provided by the user.
Example:
BPTREE_DEF2(tree_uint, 4, unsigned int, (), float, ())
void f(unsigned int num) {
tree_uint_t tree;
tree_uint_init(tree);
for(unsigned int i = 0; i < num; i++)
tree_uint_set_at(tree, i, (float) i);
tree_uint_clear(tree);
}
BPTREE_OPLIST2(name, key_oplist, value_oplist)
Return the oplist of the BPTREE defined by calling BPTREE_DEF2 with name,
key_oplist and value_oplist.
BPTREE_DEF(name, N, key_type[, key_oplist])
BPTREE_DEF_AS(name, name_t, name_it_t, name_itref_t, N, key_type, key_oplist)
Define the B+TREE tree of rank N name_t and its associated methods as
static inline functions. This B+TREE will be created as an ordered set
of key_type.
The CMP operator is used to perform the total ordering of the key elements.
N is the number of items per node and shall be greater or equal than 2.
It shall be done once per type and per compilation unit.
It also define the iterator name##_it_t and its associated methods as static inline functions.
The object oplist shall have at least the operators (INIT, INIT_SET, SET, CLEAR and CMP).
BPTREE_DEF_AS is the same as BPTREE_DEF except the name of
the container type name_t, the iterator type name_it_t and the iterated object type name_itref_t
are provided by the user.
Example:
BPTREE_DEF(tree_uint, unsigned int)
void f(unsigned int num) {
tree_uint_t tree;
tree_uint_init(tree);
for(unsigned int i = 0; i < num; i++)
tree_uint_push(tree, i);
tree_uint_clear(tree);
}
BPTREE_OPLIST(name[, key_oplist])
Return the oplist of the BPTREE defined by calling BPTREE_DEF with name and key_oplist.
If there is no given oplist, the basic oplist for basic C types is used.
BPTREE_MULTI_DEF2(name, N, key_type, key_oplist, value_type, value_oplist)
BPTREE_MULTI_DEF2_AS(name, name_t, name_it_t, name_itref_t, N, key_type, key_oplist, value_type, value_oplist)
Define the B+TREE tree of rank N name_t and its associated methods as
static inline functions. This B+TREE will be created as an associative
array of the key_type to the value_type and allows multiple instance of
the same key in the tree (aka it is a multi-map: re-adding the same key in
the tree will add a new instance of the key in the tree rather than update
the value associated to the key).
See BPTREE_DEF2 for additional details and example.
BPTREE_MULTI_DEF2_AS is the same as BPTREE_MULTI_DEF2 except the name of the types name_t, name_it_t, name_itref_t are provided by the user.
BPTREE_MULTI_DEF(name, N, key_type[, key_oplist])
BPTREE_MULTI_DEF_AS(name, name_t, name_it_t, name_itref_t, N, key_type, key_oplist)
Define the B+TREE tree of rank N name_t and its associated methods as
static inline functions. This B+TREE will be created as an ordered set
of key_type and allows multiple instance of
the same key in the tree (aka it is a multi set: re-adding the same key in
the tree will add a new instance of the key in the tree rather than update
the key value).
See BPTREE_DEF for additional details and example.
BPTREE_MULTI_DEF_AS is the same as BPTREE_MULTI_DEF except the name of the types name_t, name_it_t, name_itref_t are provided by the user.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the B+Tree of type.
name_it_t
Type of an iterator over this B+Tree.
name_itref_t
Type of one item referenced in the B+Tree. It is either:
- a structure composed of a pointer to the key (field
key_ptr) and a pointer to the value (fieldvalue_ptr) if the B+Tree is an associative array, - or the basic type of the container if the B+Tree is a set.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t tree)
void name_clear(name_t tree)
void name_init_set(name_t tree, const name_t ref)
void name_set(name_t tree, const name_t ref)
void name_init_move(name_t tree, name_t ref)
void name_move(name_t tree, name_t ref)
void name_reset(name_t tree)
size_t name_size(const name_t tree)
void name_push(name_t tree, const key_type data) [for set definition only]
void name_set_at(name_t tree, const key_type data, const value_type val) /* for associative array definition only */
bool name_erase(name_t tree, const key_type data)
value_type *name_get(const name_t tree, const key_type data)
const value_type *name_cget(const name_t tree, const key_type data)
value_type *name_safe_get(name_t tree, const key_type data)
void name_swap(name_t tree1, name_t tree2)
bool name_empty_p(const name_t tree)
void name_it(name_it_t it, name_t tree)
void name_it_set(name_it_t it, const name_it_t ref)
void name_it_end(name_it_t it, name_t tree)
bool name_end_p(const name_it_t it)
bool name_it_equal_p(const name_it_t it1, const name_it_t it1)
void name_next(name_it_t it)
name_itref_t *name_ref(name_it_t it)
const name_itref_t *name_cref(name_it_t it)
void name_get_str(string_t str, const name_t tree, bool append)
bool name_parse_str(name_t tree, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t tree)
bool name_in_str(name_t tree, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
bool name_equal_p(const name_t tree1, const name_t tree2)
size_t name_hash(const name_t tree)
void name_emplace[suffix](name_t container, keyargs...) [for dictionary set]
void name_emplace_key[keysuffix]_val[valsuffix](name_t container, keyargs..., valargs...) /* for associative array */
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
bool name_pop_at(value_type *dest, name_t tree, const key_type data)
Pop data from the B+Tree tree
and save the popped value into dest if the pointer is not NULL
while keeping the tree balanced.
Do nothing if data is no present in the B+Tree.
Return true if data has been erased, false otherwise.
value_type *name_min(const name_t tree)
const value_type *name_cmin(const name_t tree)
Return a pointer to the minimum element of the tree or NULL if there is no element in the B+Tree.
value_type *name_max(const name_t tree)
const value_type *name_cmax(const name_t tree)
Return a pointer to the maximum element of the tree or NULL if there is no element in the B+Tree.
void name_it_from(name_it_t it, const name_t tree, const type data)
Set the iterator it to the lowest element of tree
greater or equal than data or the end iterator is there is none.
bool name_it_until_p(const name_it_t it, const type data)
Return true if it references an element that is greater or equal than data
or if it references no longer a valid element, false otherwise.
bool name_it_while_p(const name_it_t it, const type data)
Return true if it references an element that is lower or equal than data.
Otherwise (or if it references no longer a valid element) it returns false.
M-TREE
A tree is an abstract data type to represent the hierarchic nature of a structure with a set of connected nodes. Each node in the tree can be connected to many children, but must be connected to exactly one parent, except for the root node, which has no parent.
TREE_DEF(name, type [, oplist])
TREE_DEF_AS(name, name_t, name_it_t, type [, oplist])
Define the tree name_t and its associated methods as static inline functions.
The tree will be composed of object of type type, connected each other.
name shall be a C identifier that will be used to identify the tree.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
Any insert (resp. remove) in the tree shall specific the insertion point
(resp. deleting point). To construct a tree, you start by creating the
root node (using the _set_root method) and then insert new nodes from there.
Each insertion of node in the tree will return an iterator of the inserted
node. This can be used to construct quickly a full tree.
The oplist shall have at least the following operators (INIT_SET & CLEAR),
otherwise it won't generate compilable code.
The tree handles its own pool of nodes for the nodes.
It is called the capacity of the tree.
This pool of nodes will increase when needed by default.
However, in case of capacity increased, all the nodes of the tree may move in memory to accommodate the new need.
You may also request to reserve more capacity to avoid moving the items, and disable this auto-expand feature (in which a MEMORY_FAILURE is raised).
There are several way to iterate over this container:
- Scan all nodes: first the parent then the children (pre-order walk).
- Scan all nodes: first the children then the parent (post-order walk).
- Scan the nodes of a sub-tree: first the parent then the children (pre-order walk of a sub-tree).
- Scan the nodes of a sub-tree: first the children then the parent (post-order walk of a sub-tree).
On insertion, all iterators remain valid. Except if it says otherwise, all functions accepting iterators expect a valid iterator (i.e. it references an existing node).
TRREE_DEF_AS is the same as TREE_DEF except the name of the types name_t, name_it_t are provided.
TREE_OPLIST(name, [, oplist])
Define the oplist of the generic tree defined with name and potentially oplist.
If there is no given oplist, the basic oplist for basic C types is used.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the generic tree of type.
name_it_t
Type of an iterator over this generic tree.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t tree)
void name_init_set(name_t tree, const name_t ref)
void name_init_move(name_t tree, name_t ref)
void name_set(name_t tree, const name_t ref)
void name_move(name_t tree, name_t ref)
void name_clear(name_t tree)
void name_reset(name_t tree)
size_t name_size(const name_t tree)
size_t name_capacity(const name_t tree)
void name_reserve(name_t tree, size_t capacity)
bool name_empty_p(const name_t tree)
void name_swap(name_t tree1, name_t tree2)
bool name_equal_p(const name_t tree1, const name_t tree2)
bool name_end_p(const name_it_t it)
bool name_it_equal_p(const name_it_t it1, const name_it_t it2)
const type *name_cref(name_it_t it)
type *name_ref(name_it_t it)
bool name_remove(it_t it)
void name_get_str(string_t str, const name_t tree, bool append)
bool name_parse_str(name_t tree, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t tree)
bool name_in_str(name_t tree, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_lock(name_t tree, bool lock)
Disable the auto-resize feature of the tree (if lock is true), or enable it otherwise. By default, the feature is enabled. Locking a tree shall be done after reserving the maximum number of nodes that can be added by your tree, so that the returned pointers to the internal types won't move on inserting a new node.
name_it_t name_set_root(name_t tree, const type value)
Set the tree to a single root node and set this node to value.
name_it_t name_emplace_root[suffix](name_t tree, args...)
Set the tree to a single root node and set this node to the value
initialized with the given args.
The provided arguments shall therefore match one of the constructor provided
by the EMPLACE_TYPE operator.
See emplace chapter for more details.
it_t name_insert_up_raw(it_t ref)
it_t name_insert_left_raw(it_t ref)
it_t name_insert_right_raw(it_t ref)
it_t name_insert_down_raw(it_t ref)
it_t name_insert_child_raw(it_t ref)
Insert a node up (resp. left, right, down and down) the given referenced iterator without initializing it.
It returns an iterator to the inserted node with non-initialized data.
The first thing to do after calling this function shall be to initialize the data
using the proper constructor of the object of type type (the pointer can be get through name_ref)
This enables using more specialized constructor than the generic copy one.
The user should use other the non _raw function if possible rather than this one
as it is low level and error prone.
name_insert_down_raw will move all children of the referenced node as children of the inserted children,
whereas name_insert_child_raw will insert the node as the new first child of the referenced node.
it_t name_insert_up(it_t ref, const type value)
it_t name_insert_left(it_t ref, const type value)
it_t name_insert_right(it_t ref, const type value)
it_t name_insert_down(it_t ref, const type value)
it_t name_insert_child(it_t ref, const type value)
Insert a node up (resp. left, right, down and down) the given referenced iterator and initialize it with a copy of value.
It returns an iterator to the inserted node.
name_insert_down will move all children of the referenced node as children of the inserted children,
whereas name_insert_child will insert the node as the new first child of the referenced node.
it_t name_move_up(it_t ref, type *value)
it_t name_move_left(it_t ref, type *value)
it_t name_move_right(it_t ref, type *value)
it_t name_move_down(it_t ref, type *value)
it_t name_move_child(it_t ref, type *value)
Insert a node up (resp. left, right, down and down) the given referenced iterator and initialize it with value by stealing as much resource from value as possible (and destroy *value)
It returns an iterator to the inserted node.
name_move_down will move all children of the referenced node as children of the inserted children,
whereas name_move_child will insert the node as the new first child of the referenced node.
it_t name_emplace_up[suffix](it_t ref, args...)
it_t name_emplace_left[suffix](it_t ref, args...)
it_t name_emplace_right[suffix](it_t ref, args...)
it_t name_emplace_down[suffix](it_t ref, args...)
it_t name_emplace_child[suffix](it_t ref, args...)
Insert a node up (resp. left, right, down and down) the given referenced iterator
and initialize this node to the value initialized with the given args.
The provided arguments shall therefore match one of the constructor provided
by the EMPLACE_TYPE operator.
See emplace chapter for more details.
It returns an iterator to the inserted node.
name_emplace_down will move all children of the referenced node as children of the inserted children,
whereas name_emplace_child will insert the node as the new first child of the referenced node.
type *name_up_ref(name_it_t it)
type *name_down_ref(name_it_t it)
type *name_left_ref(name_it_t it)
type *name_right_ref(name_it_t it)
Return a pointer to the type of the node which is
- up the given iterator,
- down the given iterator (i.e. the first child of the node)
- left the given iterator,
- right the given iterator,
respectively. It returns NULL if there is no such node.
bool name_it_up(it_t *it)
bool name_it_down(it_t *it)
bool name_it_left(it_t *it)
bool name_it_right(it_t *it)
Update the iterator to point to the node which is up (resp. down, left and right) the given iterator. Return true in case of success, false otherwise (as such node doesn't exist, the iterator remains unchanged).
bool name_root_p(const it_t it)
Return true if it references the root node, false otherwise.
bool name_node_p(const it_t it)
Return true if it references a non-leaf node, false otherwise.
bool name_leaf_p(const it_t it)
Return true if it references a leaf node, false otherwise.
int32_t name_degree(const it_t it)
Return the degree of the referenced node (aka the number of children). A leaf node has a degree of 0. This function is linear in the number of children of the node.
int32_t name_depth(const it_t it)
Return the depth of the referenced node (aka the number of nodes until reaching the root node). The root node has a depth of 0. This function is linear in the depth of the node.
type *name_unlink(it_t it)
Unlink the referenced node from the tree, so that the node is removed from the tree. All children of the removed node become children of the parent node. If the removed node is the root node, than the root node shall have only one child.
Return a reference to the internal type and give back ownership of the type:
you shall destroy the type (using CLEAR or MOVE methods) before calling any other tree functions
(as the memory area used by the node may be removed on inserting a new node)
You should use the remove service instead as it has the same semantics but it is safer as it perform the clear of the data.
void name_prune(name_it_t it)
Remove the referenced node including all its children.
See name_remove for more details.
name_it_t name_it_end(name_t tree)
Return an iterator that references no valid node.
void name_it_set(name_it_t *it, const name_it_t ref)
Set the iterator *it to ref.
[!NOTE] You can use the
=affectation operator of the C language to copy tree iterators too.
name_it_t name_it(name_t tree)
Return an iterator of the tree that will iterator on the tree in global pre-order walk (the root).
void name_next(name_it_t *it)
Update the iterator of the tree so that it references the next node in a global pre-order walk, or set it to invalid if the walk is finished.
name_it_t name_it_post(name_t tree)
Return an iterator of the tree that will iterator on the tree in global post-order walk
void name_next_post(name_it_t *it)
Update the iterator of the tree so that it references the next node in a global post-order walk, or set it to invalid if the walk is finished.
name_it_t name_it_subpre(name_t tree, const name_it_t ref)
Return an iterator of the tree that will iterator on the tree in pre-order walk of the child nodes of the referenced one.
void name_next_subpre(name_it_t it, const name_it_t ref)
Update the iterator of the tree so that it references the next node in a local pre-order walk of the child nodes of the referenced one, or set it to invalid if the walk is finished (the sub tree is fully scanned).
The referenced iterator shall be the same as the one used to create the updated iterator (with name_it_subpre).
name_it_t name_it_subpost(name_t tree, const name_it_t ref)
Return an iterator of the tree that will iterator on the tree in post-order walk of the child nodes of the referenced one.
void name_next_subpost(name_it_t it, const name_it_t ref)
Update the iterator of the tree so that it references the next node in a local post-order walk of the child nodes of the referenced one, or set it to invalid if the walk is finished (the sub-tree is fully scanned).
The referenced iterator shall be the same as the one used to create the updated iterator (with name_it_subpost).
void name_lca(name_it_t it1, name_it_t it2)
Compute the Lowest Common Ancestor of the two iterators. Both iterators shall belong to the same tree.
void name_swap_at(name_it_t it1, name_it_t it2, bool swapChild)
Swap the node referenced by it1 and the node referenced by it2 in the tree.
If swapChild is true, the children nodes perform the swap with their parent.
Otherwise, only the referenced nodes are swapped.
void name_sort_child(name_it_t it1)
Sort the child of the node referenced by it1 in the order of the type.
This method is constructed if the basic type exports the CMP type.
M-PRIOQUEUE
A priority queue is a queue where each element has a "priority" associated with it: an element with high priority is served before an element with low priority. It is currently implemented as a heap.
PRIOQUEUE_DEF(name, type [, oplist])
PRIOQUEUE_DEF_AS(name, name_t, name_it_t, type [, oplist])
Define the priority queue name_t and its associated methods
as static inline functions.
The queue will be composed of object of type type.
name shall be a C identifier that will be used to identify the queue.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The CMP operator is used to sort the queue so that the highest priority is the minimum.
The EQUAL operator is used to identify an item on update or remove operations.
It is uncorrelated with the CMP operator from the point of view of this container.
(i.e. EQUAL() == TRUE is not equivalent to CMP() == 0 for this container)
This queue will push the object at the right place in the queue in function of their priority. A pop from this queue will always return the minimum of all objects within the queue (contrary to C++ which returns the maximum), and the front method will reference this object.
The oplist shall have at least the following operators (INIT, INIT_SET, SET, CLEAR, CMP),
otherwise it won't generate compilable code.
The equal_p, update & erase methods have a complexity of O(n) due to the linear
search of the data and are only created if the EQUAL method is defined.
Iteration over this container won't iterate from minimum to maximum but in an implementation define way that ensures that all items are accessed.
PRIOQUEUE_DEF_AS is the same as PRIOQUEUE_DEF except the name of the types name_t, name_it_t are provided.
PRIOQUEUE_OPLIST(name, [, oplist])
Define the oplist of the PRIOQUEUE defined with name and potentially oplist.
If there is no given oplist, the basic oplist for basic C types is used.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the priority queue of type.
name_it_t
Type of an iterator over this priority queue.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t queue)
void name_clear(name_t queue)
void name_init_set(name_t queue, const name_t ref)
void name_set(name_t queue, const name_t ref)
void name_init_move(name_t queue, name_t ref)
void name_move(name_t queue, name_t ref)
void name_reset(name_t queue)
size_t name_size(const name_t queue)
bool name_empty_p(const name_t queue)
void name_swap(name_t queue1, name_t queue2)
void name_push(name_t queue, const type x)
const type *name_front(name_t queue)
void name_pop(type *dest, name_t queue)
bool name_equal_p(const name_t queue1, const name_t queue2)
bool name_erase(name_t queue, const type_t val)
void name_it(name_it_t it, name_t queue)
void name_it_last(name_it_t it, name_t queue)
void name_it_set(name_it_t it, const name_it_t ref)
void name_it_end(name_it_t it, name_t queue)
bool name_end_p(const name_it_t it)
bool name_last_p(const name_it_t it)
bool name_it_equal_p(const name_it_t it1, const name_it_t it2)
void name_next(name_it_t it)
void name_previous(name_it_t it)
const type *name_cref(name_it_t it)
void name_get_str(string_t str, const name_t queue, bool append)
bool name_parse_str(name_t queue, const char str[], const char **endp)
void name_out_str(FILE *file, const name_t queue)
bool name_in_str(name_t queue, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
void name_emplace[suffix](name_t queue, args...)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_update(name_t queue, const type_t old_val, const type_t new_val)
Change the priority of the data of the priority equals to old_val (in EQUAL sense)
to new_val (increase or decrease priority).
This method has a complexity of O(n) (due to linear search of the data).
This method is defined only if the EQUAL method is defined.
M-BUFFER
This header implements different kind of fixed circular buffer.
A circular buffer (or ring buffer or circular queue) is a data structure using a single, bounded buffer as if its head was connected to its tail.
BUFFER_DEF(name, type, size, policy[, oplist])
BUFFER_DEF_AS(name, name_t, type, size, policy[, oplist])
Define the buffer name_t and its associated methods as static inline functions.
A buffer is a fixed circular queue implementing a queue (or stack) interface.
It can be used to transfer message from multiple producer threads to multiple consumer threads.
This is done internally using a mutex and conditional waits
(if it is built with the BUFFER_THREAD_SAFE option — default)
name shall be a C identifier that will be used to identify the buffer.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The size parameter defined the fixed size of the queue.
It can be 0. In this case, the fixed size is defined at initialization time only
and the needed objects to handle the buffer are allocated at initialization time too.
Otherwise the needed objects are embedded within the structure, preventing
any other allocations.
The size of the buffer shall be lower or equal than the maximum of the type int.
Multiple additional policy can be applied to the buffer by performing a logical or of the following properties:
BUFFER_QUEUE— define a FIFO queue (default),BUFFER_STACK— define a stack (exclusive withBUFFER_QUEUE),BUFFER_THREAD_SAFE— define thread safe functions (default),BUFFER_THREAD_UNSAFE— define thread unsafe functions (exclusive withBUFFER_THREAD_SAFE),BUFFER_PUSH_INIT_POP_MOVE— change the behavior ofPUSHto push a new initialized object, andPOPas moving this new object into the new emplacement (this is mostly used for performance reasons or to handle properly a shared_ptr semantic). In practice, it works as ifPOPperforms the initialization of the object.BUFFER_PUSH_OVERWRITE—PUSHoverwrites the last entry if the queue is full instead of blocking,BUFFER_DEFERRED_POP— do not consider the object to be fully popped from the buffer by calling the pop method until the call topop_deferred; this enables to handle object that are in-progress of being consumed by the thread.
This container is designed to be used for synchronization inter-threads of data
(and the buffer variable should be a global shared one). A function tagged "thread safe"
is thread safe only if the container has been generated with the THREAD_SAFE option.
The oplist shall have at least the following operators (INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
The PUSH and POP methods operate like push_blocking and pop_blocking when the blocking parameter
is true.
BUFFER_DEF_AS is the same as BUFFER_DEF except the name of the type name_t is provided.
Example:
BUFFER_DEF(buffer_uint, unsigned int, 10, BUFFER_QUEUE|BUFFER_BLOCKING)
buffer_uint_t g_buff;
void f(unsigned int i) {
buffer_uint_init(g_buff, 10);
buffer_uint_push(g_buff, i);
buffer_uint_pop(&i, g_buff);
buffer_uint_clear(g_buff);
}
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the buffer.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_clear(buffer_t buffer) /* Not thread safe */
void name_reset(buffer_t buffer) /* Thread safe */
bool name_empty_p(const buffer_t buffer) /* Thread safe */
size_t name_size(const buffer_t buffer) /* Thread safe */
size_t name_capacity(const buffer_t buffer) /* Thread safe */
bool name_push(buffer_t buffer, const type data)
bool name_pop(type *data, buffer_t buffer)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_init(buffer_t buffer, size_t size)
Initialize the buffer buffer for size elements.
The size argument shall be the same as the one used to create the buffer
or the one used to create the buffer was 0.
The size of the buffer shall be lower or equal than UINT_MAX.
This function is not thread safe.
bool name_full_p(const buffer_t buffer)
Return true if the buffer is full, false otherwise. This function is thread safe if the buffer was built thread safe.
size_t name_overwrite(const buffer_t buffer)
If the buffer is built with the BUFFER_PUSH_OVERWRITE option,
this function returns the number of elements that have been overwritten
and thus discarded.
If the buffer was not built with the BUFFER_PUSH_OVERWRITE option,
it returns 0.
bool name_push_blocking(buffer_t buffer, const type data, bool blocking)
Push the object data in the buffer buffer,
waiting for an empty room if blocking is true (performing a blocking wait)
Returns true if the data was pushed, false otherwise.
Always return true if the buffer is blocking.
This function is thread safe if the buffer was built thread safe.
bool name_pop_blocking(type *data, buffer_t buffer, bool blocking)
Pop from the buffer buffer into the object *data,
waiting for a data if blocking is true.
If the buffer is built with the BUFFER_PUSH_INIT_POP_MOVE option,
the object pointed by data shall be uninitialized
as the pop function will perform a quick initialization of the object
(using an INIT_MOVE operator)
, otherwise it shall be an initialized object (the pop function will
perform a SET operator).
If the buffer is built with the BUFFER_DEFERRED_POP option,
the object is still considered being present in the queue until
a call to name_pop_release.
Returns true if a data was popped, false otherwise. Always return true if the buffer is blocking. This function is thread safe if the buffer was built thread safe.
bool name_pop_release(buffer_t buffer)
If the buffer is built with the BUFFER_DEFERRED_POP option,
the object being popped is considered fully release (freeing a
space in the queue).
Otherwise it does nothing.
QUEUE_MPMC_DEF(name, type, policy[, oplist])
QUEUE_MPMC_DEF_AS(name, name_t, type, policy[, oplist])
Define the MPMC queue name_t and its associated methods as static inline functions.
A MPMC queue is a fixed circular queue implementing a queue (or stack) interface.
It can be used to transfer message from Multiple Producer threads to Multiple Consumer threads.
This queue is not strictly lock free but has
a lot of the properties of such algorithms.
The size is specified only at run-time and shall be a power of 2.
name shall be a C identifier that will be used to identify the queue.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
An additional policy can be applied to the buffer by performing a logical or of the following properties:
BUFFER_QUEUE— define a FIFO queue (default),BUFFER_PUSH_INIT_POP_MOVE— change the behavior ofPUSHto push a new initialized object, andPOPas moving this new object into the new emplacement (this is mostly used for performance reasons or to handle properly a shared_ptr semantic). In practice, it works as ifPOPperforms the initialization of the object.
This container is designed to be used for easy synchronization inter-threads in a context of very fast communication (the variable should be a global shared one). There should not have much more threads using this queue than they are available hardware cores due to the only partial protection on Context-switch Immunity of this structure (This can happen only if you abuse massively the number of threads vs the number of cores).
The oplist shall have at least the following operators (INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
The size method is thread safe but may return a size greater than
the size of the queue in some race condition.
QUEUE_MPMC_DEF_AS is the same as QUEUE_MPMC_DEF except the name of the type name_t
is provided.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the circular queue.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_clear(buffer_t buffer)
bool name_empty_p(const buffer_t buffer) /* Thread safe */
size_t name_size(const buffer_t buffer) /* Thread safe */
size_t name_capacity(const buffer_t buffer) /* Thread safe */
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_init(buffer_t buffer, size_t size)
Initialize the buffer buffer with size elements.
The size argument shall be a power of two greater than 0, and less than UINT_MAX.
This function is not thread safe.
##### bool name_full_p(const buffer_t buffer)
Return true if the buffer is full, false otherwise. This function is thread safe.
bool name_push(buffer_t buffer, const type data)
Push the object data in the buffer buffer if possible.
Returns true if the data was pushed, false otherwise
(buffer full or unlikely data race).
This function is thread safe.
bool name_pop(type *data, buffer_t buffer)
Pop from the buffer buffer into the object *data if possible.
If the buffer is built with the BUFFER_PUSH_INIT_POP_MOVE option,
the object pointed by data shall be uninitialized
as the pop function will perform a quick initialization of the object
(using an INIT_MOVE operator)
, otherwise it shall be an initialized object (the pop function will
perform a SET operator).
Returns true if a data was popped, false otherwise (buffer empty or unlikely data race). This function is thread safe.
QUEUE_SPSC_DEF(name, type, policy[, oplist])
QUEUE_SPSC_DEF_AS(name, name_t, type, policy[, oplist])
Define the SPSC queue name_t and its associated methods as static inline functions.
A SPSC queue is a fixed circular queue implementing a queue (or stack) interface.
It can be used to transfer message from a Single Producer thread to a Single Consumer thread.
This is done internally using lock-free objects.
It is more specialized than QUEUE_MPMC_DEF and as such, is faster.
The size is specified only at run-time and shall be a power of 2.
name shall be a C identifier that will be used to identify the queue.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
An additional policy can be applied to the buffer by performing a logical or of the following properties:
BUFFER_QUEUE— define a FIFO queue (default),BUFFER_PUSH_INIT_POP_MOVE— change the behavior ofPUSHto push a new initialized object, andPOPas moving this new object into the new emplacement (this is mostly used for performance reasons or to handle properly a shared_ptr semantic). In practice, it works as ifPOPperforms the initialization of the object.
This container is designed to be used for easy synchronization inter-threads in a context of very fast communication (the variable should be a global shared one).
The oplist shall have at least the following operators (INIT, INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
QUEUE_SPSC_DEF_AS is the same as QUEUE_MPMC_DEF except the name of the type name_t
is provided.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the circular queue.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_clear(buffer_t buffer)
bool name_empty_p(const buffer_t buffer) /* Thread safe */
size_t name_size(const buffer_t buffer) /* Thread safe */
size_t name_capacity(const buffer_t buffer) /* Thread safe */
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_init(buffer_t buffer, size_t size)
Initialize the buffer buffer with size elements.
The size argument shall be a power of two greater than 0, and less than UINT_MAX.
This function is not thread safe.
bool name_full_p(const buffer_t buffer)
Return true if the buffer is full, false otherwise. This function is thread safe.
bool name_push(buffer_t buffer, const type data)
Push the object data in the buffer buffer if possible.
Returns true if the data was pushed, false otherwise (buffer full).
This function is thread safe.
bool name_push_move(buffer_t buffer, type *data)
Push & move the object *data in the buffer buffer if possible.
Returns true if the data was pushed, false otherwise (buffer full).
Afterwards *data is cleared (destructor) if true is returned.
This function is thread safe.
bool name_push_force(buffer_t buffer, const type data)
Push the object data in the buffer buffer
discarding the oldest data if needed.
This function is thread safe.
bool name_push_bulk(buffer_t buffer, unsigned n, const type data[])
Push as much objects from the array data in the buffer buffer as possible,
starting from the object at index 0 to the object at index n-1.
Returns the number of objects effectively pushed (it depends on the free size of the queue)
This function is thread safe.
bool name_pop(type *data, buffer_t buffer)
Pop from the buffer buffer into the object *data if possible.
If the buffer is built with the BUFFER_PUSH_INIT_POP_MOVE option,
the object pointed by data shall be uninitialized
as the pop function will perform a quick initialization of the object
(using an INIT_MOVE operator)
, otherwise it shall be an initialized object (the pop function will
perform a SET operator).
Returns true if a data was popped, false otherwise (buffer empty or unlikely data race). This function is thread safe.
unsigned name_pop_bulk(unsigned n, type tab[n], buffer_t buffer)
Pop from the buffer buffer as many objects as possible to fill in tab
and at most n.
If the buffer is built with the BUFFER_PUSH_INIT_POP_MOVE option,
the object pointed by data shall be uninitialized
as the pop function will perform a quick initialization of the object
(using an INIT_MOVE operator)
, otherwise it shall be an initialized object (the pop function will
perform a SET operator).
It returns the number of objects popped. This function is thread safe.
M-SNAPSHOT
This header is for created snapshots.
A snapshot is a mechanism enabling a reader thread and a writer thread, working at different speeds, to exchange messages in a fast, reliable and thread safe way (the message is always passed atomically from a thread point of view) without waiting for synchronization. The consumer thread always accesses to the latest published data of the producer thread.
It is implemented in a fast way as the writer directly writes the message in the buffer that will be passed to the reader (avoiding copy of the buffer) and a simple exchange of index is sufficient to handle the switch.
This container is designed to be used for easy synchronization inter-threads.
This is linked to shared atomic register in the literature and snapshot names vector of such registers where each element of the vector can be updated separately. They can be classified according to the number of producers/consumers:
- SPSC (Single Producer, Single Consumer),
- MPSC (Multiple Producer, Single Consumer),
- SPMC (Single Producer, Multiple Consumer),
- MPMC (Multiple Producer, Multiple Consumer),
The provided containers by the library are designed to handle huge
structure efficiently and as such deal with the memory reclamation needed to handle them.
If the data you are sharing are supported by the atomic header (like bool or integer),
using atomic_load and atomic_store is a much more efficient and simple way
to do even in the case of MPMC.
SNAPSHOT_SPSC_DEF(name, type[, oplist])
SNAPSHOT_SPSC_DEF_AS(name, name_t, type[, oplist])
Define the snapshot name ## _t (or name_t) and its associated methods as static inline functions.
Only a single reader thread and a single writer thread are supported.
It is a SPSC atomic shared register.
In practice, it is implemented using a triple buffer (lock-free).
name shall be a C identifier that will be used to identify the snapshot.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The oplist shall have at least the following operators (INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
Example:
SNAPSHOT_DEF(snapshot_uint, unsigned int)
snapshot_uint_t message;
void f(unsigned int i) {
unsigned *p = snapshot_uint_get_write_buffer(message);
*p = i;
snapshot_uint_write(message);
}
unsigned int g(void) {
unsigned *p = snapshot_uint_read(message);
return *p;
}
SNAPSHOT_SPSC_DEF_AS is the same as SNAPSHOT_SPSC_DEF except the name of the type name_t is provided.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the circular queue.
Generic methods
The following methods of the generic interface are defined (See generic interface for details) but none is thread safe:
void name_init(snapshot_t snapshot)
void name_clear(snapshot_t snapshot)
void name_init_set(snapshot_t snapshot, const snapshot_t org)
void name_set(snapshot_t snapshot, const snapshot_t org)
void name_init_move(snapshot_t snapshot, snapshot_t org)
void name_move(snapshot_t snapshot, snapshot_t org)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
type *name_write(snapshot_t snap)
Publish the "in-progress" data of the snapshot snap so that the read
thread can have access to the data.
It returns the pointer to the new "in-progress" data buffer
of the snapshot (which is not yet published but will be published
for the next call of name_write).
This function is thread-safe and performs atomic operation on the snapshot.
type *name_read(snapshot_t snap)
Get access to the last published data of the snapshot snap.
It returns the pointer to the data.
If a publication has been performed since the last call to name_read
a new pointer to the data is returned.
Otherwise the previous pointer is returned.
This function is thread-safe and performs atomic operation on the snapshot.
bool name_updated_p(snapshot_t snap)
Return true if a new publication is available since the last time it was read. This function is thread-safe and performs atomic operation on the snapshot.
type *name_get_write_buffer(snapshot_t snap)
Return a pointer to the active "in-progress" data of the snapshot snap.
It is the same as the last return from name_write.
This function is thread-safe and performs atomic operation on the snapshot.
type *name_get_read_buffer(snapshot_t snap)
Return a pointer to the last already read published data of the snapshot snap.
It is the same as the last return from name_read.
It doesn't perform any switch of the data that has to be read.
This function is thread-safe and performs atomic operation on the snapshot.
SNAPSHOT_SPMC_DEF(name, type[, oplist])
SNAPSHOT_SPMC_DEF_AS(name, name_t, type[, oplist])
Define the snapshot name ## _t (or name_t) and its associated methods as static inline functions.
A snapshot is an atomic shared register where only the latest state is
important and accessible: it is like a global variable of type type
but ensuring integrity and coherency of the data across multiple threads.
One single writer and multiple (=N) readers are supported.
In practice, it is implemented using a N+2 buffer (lock-free).
name shall be a C identifier that will be used to identify the snapshot.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The oplist shall have at least the following operators (INIT, INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
SNAPSHOT_SPMC_DEF_AS is the same as SNAPSHOT_SPMC_DEF except the name of the type name_t is provided.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the circular queue.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_clear(snapshot_t snapshot)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_init(snapshot_t snapshot, size_t numReaders)
Initialize the communication snapshot snapshot with numReaders reader threads.
numReaders shall be less than 2046.
This function is not thread safe.
type *name_write(snapshot_t snap)
Publish the "in-progress" data of the snapshot snap so that the read
threads can have access to the data.
It returns the pointer to the new "in-progress" data buffer
of the snapshot (which is not yet published but will be published
for the next call of name_write).
This function is thread-safe and performs atomic operation on the snapshot.
type *name_read_start(snapshot_t snap)
Get access to the last published data of the snapshot snap.
It returns the pointer to the data.
If a publication has been performed since the last call to name_read_start
a new pointer to the data is returned.
Otherwise the previous pointer is returned.
It marks the data has being reserved by the thread, so afterwards, using the pointer is safe until the end of the reservation. This function is thread-safe and performs atomic operation on the snapshot.
For each call to name_read_start a matching call to
name_read_end shall be performed by the same thread before
any new call to name_read_start.
type *name_read_end(snapshot_t snap, type *old)
End the reservation of the data old.
This function is thread-safe and performs atomic operation on the snapshot.
type *name_get_write_buffer(snapshot_t snap)
Return a pointer to the active "in-progress" data of the snapshot snap.
It is the same as the last return from name_write.
This function is thread-safe and performs atomic operation on the snapshot.
SNAPSHOT_MPMC_DEF(name, type[, oplist])
SNAPSHOT_MPMC_DEF_AS(name, name_t, type[, oplist])
Define the snapshot name ## _t (or name_t) and its associated methods as static inline functions.
A snapshot is an atomic shared register where only the latest state is
important and accessible: it is like a global variable of type type
but ensuring integrity and coherency of the data across multiple threads.
Multiple (=M) writers and multiple (=N) readers are supported.
In practice, it is implemented using a M+N+2 buffer (lock-free)
by avoiding copying the data.
name shall be a C identifier that will be used to identify the snapshot.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The oplist shall have at least the following operators (INIT, INIT_SET, SET and CLEAR),
otherwise it won't generate compilable code.
SNAPSHOT_MPMC_DEF_AS is the same as SNAPSHOT_MPMC_DEF except the name of the type name_t is provided.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the circular queue.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_clear(snapshot_t snapshot)
Specialized methods
void name_init(snapshot_t snapshot, size_t numReaders, size_t numWriters)
Initialize the communication snapshot snapshot with numReaders reader threads
and numWriters writer threads.
The sum of numReaders and numWriters shall be less than 2046.
This function is not thread safe.
type *name_write_start(snapshot_t snap)
Return the current "in-progress" data of the snapshot snap
so that the writer thread can update this data.
This function is thread-safe and performs atomic operation on the snapshot.
type *name_write_end(snapshot_t snap, type *data)
Mark the provided "in-progress" data of the snapshot snap
as available for the reader threads: this will be the new seen data.
This function is thread-safe and performs atomic operation on the snapshot.
type *name_read_start(snapshot_t snap)
Get access to the last published data of the snapshot snap.
It returns the pointer to the data.
If a publication has been performed since the last call to name_read_start
a new pointer to the data is returned.
Otherwise, the previous pointer is returned.
It marks the data has being reserved by the thread, so afterwards, using the pointer is safe until the end of the reservation. This function is thread-safe and performs atomic operation on the snapshot.
For each call to name_read_start a matching call to
name_read_end shall be performed by the same thread before
any new call to name_read_start.
type *name_read_end(snapshot_t snap, type *old)
End the reservation of the data old.
This function is thread-safe and performs atomic operation on the snapshot.
M-SHARED
This header is for creating shared pointer. A shared pointer is a smart pointer that retains shared ownership of an object. Several shared pointers may own the same object, sharing ownership of an object.
SHARED_PTR_DEF(name, type[, oplist])
SHARED_PTR_DEF_AS(name, name_t, type[, oplist])
Define the shared pointer name_t and its associated methods as static inline functions.
A shared pointer is a mechanism to keep tracks of all registered users of an object
and performs an automatic destruction of the object only when all users release
their need on this object.
name shall be a C identifier that will be used to identify the shared pointer.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The tracking of ownership is atomic and the destruction of the object is thread safe.
The object oplist is expected to have at least the following operators (CLEAR to clear the object and DEL to free the allocated memory).
There are designed to work with buffers with policy BUFFER_PUSH_INIT_POP_MOVE
to send a shared pointer across multiple threads.
If the type is an incomplete type, you need to disable the INIT operator and not defined the EMPLACE_TYPE operator in the given oplist like this:
(INIT(0), CLEAR(API_2(incomplete_clear))) )
SHARED_PTR_DEF_AS is the same as SHARED_PTR_DEF except the name of the type name_t
is provided.
Example:
SHARED_PTR_DEF(shared_mpz, mpz_t, (CLEAR(mpz_clear)))
void f(void) {
shared_mpz_t p;
mpz_t z;
mpz_init(z);
shared_mpz_init2 (p, z);
buffer_uint_push(g_buff1, p);
buffer_uint_push(g_buff2, p);
shared_mpz_clear(p);
}
SHARED_PTR_RELAXES_DEF(name, type[, oplist])
SHARED_PTR_RELAXES_DEF_AS(name, name_t, type[, oplist])
Theses are the same as SHARED_PTR_DEF / SHARED_PTR_DEF_AS
except that they are not thread safe.
See SHARED_PTR_DEF for other details.
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the shared pointer.
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_init(shared_t shared)
Initialize the shared pointer shared to represent the NULL pointer
(no object is therefore referenced).
void name_init2(shared_t shared, type *data)
Initialize the shared pointer shared to reference the object *data
and takes ownership of this object.
User code shall not use *data (or any pointer to it) anymore
as the shared pointer gets the exclusive ownership of the object.
void name_init_new(shared_t shared)
Initialize the shared pointer shared to a new object of type type.
The default constructor of type is used to initialize the object.
This method is only created if the INIT method is provided.
void name_init_set(shared_t shared, const shared_t src)
Initialize the shared pointer shared to the same object than the one
pointed by src (sharing ownership).
This function is thread safe from src point of view.
void name_init_with[suffix](shared_t shared, args...)
Initialize the shared pointer shared to the new object initialized with args.
The provided arguments shall therefore match one of the constructor provided
by the EMPLACE_TYPE operator.
There is one generated method per suffix defined in the EMPLACE_TYPE operator,
and the suffix in the generated method name corresponds to the suffix defined
in the EMPLACE_TYPE operator (it can be empty).
This method is created only if the EMPLACE_TYPE operator is provided.
See emplace chapter for more details.
It is equivalent to the C++ make_shared.
bool name_NULL_p(const shared_t shared)
Return true if shared doesn't reference any object (i.e. is the NULL pointer).
void name_clear(shared_t shared)
Clear the shared pointer (destructor): the shared pointer loses its ownership of the object and it destroys the shared object if no longer any other shared pointers own it. This function is thread safe.
void name_reset(shared_t shared)
shared loses ownership of its shared object and destroys it
if no longer any other shared pointers own it.
Then it makes the shared pointer shared references no object (NULL)
(it doesn't reference its object any-longer and loses its ownership of it).
This function is thread safe.
void name_set(shared_t shared, const shared_t src)
shared loses ownership of its object and destroy it
if no longer any other shared pointers own it.
Then it sets the shared pointer shared to the same object
than the one pointed by src (sharing ownership).
This function is thread safe.
void name_init_move(shared_t shared, shared_t src)
Move the shared pointer from the initialized src to shared.
void name_move(shared_t shared, shared_t src)
shared loses ownership of its object and destroy it
if no longer any other shared pointers own it.
Then it moves the shared pointer from the initialized src to shared.
void name_swap(shared_t shared1, shared_t shared2)
Swap the references of the objects owned by the shared pointers shared1 and shared2.
bool name_equal_p(const shared_t shared1, const shared_t shared2)
Return true if both shared pointers own the same object.
const type *name_cref(const shared_t shared)
Return a constant pointer to the shared object owned by the shared pointer. The pointer shall be kept only until another use of shared pointer method. Keeping the pointer otherwise is undefined behavior.
type *name_ref(const shared_t shared)
Return a pointer to the shared object pointed by the shared pointer. The pointer shall be kept only until another use of shared pointer method. Keeping the pointer otherwise is undefined behavior.
TODO: Document shared resource
M-I-SHARED
This header is for creating intrusive shared pointer.
ISHARED_PTR_INTERFACE(name, type)
Extend the definition of the structure of an object of type type by adding the
necessary interface to handle it as a shared pointer named name.
It shall be put within the structure definition of the object (See example).
ISHARED_PTR_STATIC_INIT(name, type)
Provide the static initialization value of an object defined with a
ISHARED_PTR_INTERFACE extra fields. It shall be used only for global
variables with the _init_once function.
Usage (provided that the interface is used as the first element of the structure):
struct mystruct variable = { ISHARED_PTR_STATIC_INIT(ishared_double, struct mystruct) };
ISHARED_PTR_STATIC_DESIGNATED_INIT(name, type)
Provide the static initialization value of an object defined with a
ISHARED_PTR_INTERFACE extra fields. It shall be used only for global
variables with the _init_once function.
It uses designated initializers to set the right fields.
Usage:
struct mystruct variable = {ISHARED_PTR_STATIC_DESIGNATED_INIT(ishared_double, struct mystruct) };
ISHARED_PTR_DEF(name, type[, oplist])
ISHARED_PTR_DEF_AS(name, name_t, type[, oplist])
Define the associated methods to handle the shared pointer named name
as static inline functions.
A shared pointer is a mechanism to keep tracks of all users of an object
and performs an automatic destruction of the object whenever all users release
their need on this object.
The destruction of the object is thread safe and occurs when the last user of the object releases it. The destruction of the object implies:
- calling the
CLEARoperator to clear the object, - calling the
DELoperator to release the memory used by the object (if the method has not been disabled).
The object oplist is expected to have the following operators (CLEAR and DEL),
otherwise default methods are used. If there is no given oplist, the default
operators are also used. The created methods will use the operators to init, set
and clear the contained object.
There are designed to work with buffers with policy BUFFER_PUSH_INIT_POP_MOVE
to send a shared pointer across multiple threads.
It is recommended to use the intrusive shared pointer over the standard one if possible. They are faster and cleaner.
The default is to use heap allocated entities, which are allocated by NEW and
freed by DEL.
It can be used for statically allocated entities. However, in this case,
you shall disable the operator NEW and DEL when expanding the oplist
so that the destruction doesn't try to free the objects, like this:
(NEW(0), DEL(0))
NEW and DEL operators shall be either both defined, or both disabled.
ISHARED_PTR_DEF_AS is the same as ISHARED_PTR_DEF except the name of the type name_t
is provided.
Example (dynamic):
typedef struct mystruct_s {
ISHARED_PTR_INTERFACE(ishared_mystruct, struct mystruct_s);
char *message;
} mystruct_t;
static inline void mystruct_init(mystruct_t *p) { p->message = NULL; }
static inline void mystruct_clear(mystruct_t *p) { free(p->message); }
ISHARED_PTR_DEF(ishared_mystruct, mystruct_t, (INIT(mystruct_init), CLEAR(mystruct_clear M_IPTR)))
void f(void) {
mystruct_t *p = ishared_mystruct_init_new();
p->message = strdup ("Hello");
buffer_mystruct_push(g_buff1, p);
buffer_mystruct_push(g_buff2, p);
ishared_mystruct_clear(p);
}
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
It will define name_t as a pointer to shared counted object. This is a synonymous to a pointer to the object.
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
name_t name_init(type *object)
Return a shared pointer to object which owns object.
It initializes the private fields of object handling the shared pointer,
returning the same pointer to the object from a value point of view,
but with the shared pointer field initialized.
As a consequence, the shared pointer part of object shall not have been initialized yet.
The other part of object may or may not be initialized before calling this method.
name_t name_init_set(name_t shared)
Return a new shared pointer to the same object than the one pointed by shared,
incrementing the ownership of the object.
This function is thread safe.
name_t name_init_new(void)
Allocate a new object, initialize it and return an initialized shared pointer to it.
The used allocation function is the NEW operator.
This method is only created if the INIT and NEW methods are provided and not disabled.
name_t name_init_once(type *object)
Initialize the new object object and return an initialized shared pointer to it.
The INIT operator of object is ensured to be called only once,
even if multiple threads try to initialize it at the same time.
Once the object is fully cleared, the initialization function may occur once again.
object shall be a global variable initialized with the
ISHARED_PTR_STATIC_INIT macro.
This method is only created if the INIT and NEW methods are provided and not disabled.
void name_clear(name_t shared)
Clear the shared pointer, releasing ownership of the object
and destroying the shared object if no longer
any other shared pointers own it.
This function is thread safe.
void name_clear_ptr(name_t *shared)
Clear the shared pointer *shared, releasing ownership of the object
and destroying the shared object if no longer
any other shared pointers own it.
This function is thread safe.
Afterwards, *shared is set to NULL.
void name_set(name_t *shared1, name_t shared2)
Update the shared pointer *shared1 to point to the same object than
the shared pointer shared2.
Destroy the shared object pointed by *shared1 if no longer any other shared
pointers own it, set the shared pointer shared to the same object
than the one pointed by src.
This function is thread safe.
M-I-LIST
This header is for creating intrusive doubly-linked list.
ILIST_INTERFACE(name, type)
Extend an object by adding the necessary interface to handle it within
an intrusive doubly-linked list.
This is the intrusive part.
It shall be put within the structure of the object to link, at the top
level of the structure.
See example of ILIST_DEF.
ILIST_INIT_FIELD(name, object)
Initialize the fields added by ILIST_INTERFACE of the object.
ILIST_DEF(name, type[, oplist])
ILIST_DEF_AS(name, name_t, name_it_t, type[, oplist])
Define the intrusive doubly-linked list
and define the associated methods to handle it as static inline functions.
name shall be a C identifier that will be used to identify the list.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
The oplist shall have at least the following operators (CLEAR),
otherwise it won't generate compilable code.
An object is expected to be part of only one list of a kind in the entire program at a time.
An intrusive list enables to move from an object to the next object without needing to go through the entire list,
or to remove an object from a list in O(1).
It may, or may not, be better than standard list. It depends on the context.
The given interface won't allocate anything to handle the objects as
all allocations and initialization are let to the user.
However, the objects within the list can be automatically be cleared
(by calling the CLEAR method to destruct the object) on list destruction.
Then the memory allocation, performed by the user program, can also be reclaimed
by defining a DEL operator to free the used memory in the object oplist.
If there is no DEL operator, it is up to the user to free the used memory.
The list iterates from back to front.
ILIST_DEF_AS is the same as ILIST_DEF except the name of the types name_t, name_it_t
are provided.
Example:
typedef struct test_s {
int n;
ILIST_INTERFACE (ilist_tname, struct test_s);
} test_t;
ILIST_DEF(ilist_tname, test_t)
void f(void) {
test_t x1, x2, x3;
ilist_tname_t list;
x1.n = 1;
x2.n = 2;
x3.n = 3;
ilist_tname_init(list);
ilist_tname_push_back (list, &x3);
ilist_tname_push_front (list, &x1);
ilist_tname_push_after (&x1, &x2);
int n = 1;
for M_EACH(item, list, ILIST_OPLIST(ilist_tname)) {
assert (n == item->n);
n++;
}
ilist_tname_clear(list);
}
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the list of type.
name_it_t
Type of an iterator over this list.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t list)
void name_clear(name_t list)
void name_reset(name_t list)
type *name_back(const name_t list)
type *name_front(const name_t list)
bool name_empty_p(const name_t list)
void name_swap(name_t list1, name_t list2)
void name_it(name_it_t it, name_t list)
void name_it_set(name_it_t it, const name_it_t ref)
void name_it_last(name_it_t it, name_t list)
void name_it_end(name_it_t it, name_t list)
bool name_end_p(const name_it_t it)
bool name_last_p(const name_it_t it)
bool name_it_equal_p(const name_it_t it1, const name_it_t it2)
void name_next(name_it_t it)
void name_previous(name_it_t it)
type *name_ref(name_it_t it)
const type *name_cref(const name_it_t it)
size_t name_size(const name_t list)
void name_remove(name_t list, name_it_t it)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_init_field(type *obj)
Initialize the additional fields of the object *obj handling the list.
This function shall be used in the object constructor.
void name_push_back(name_t list, type *obj)
Push the object *obj itself (and not a copy) at the back of the list list.
void name_push_front(name_t list, type *obj)
Push the object *obj itself (and not a copy) at the front of the list list.
void name_push_after(type *position, type *obj)
Push the object *obj itself (and not a copy) after the object *position.
type *name_pop_back(name_t list)
Pop the object from the back of the list list
and return a pointer to the popped object,
given back the ownership of the object to the caller program
(which becomes responsible to calling the destructor of this object).
type *name_pop_front(name_t list)
Pop the object from the front of the list list
and return a pointer to the popped object,
given back the ownership of the object to the caller program
(which becomes responsible to calling the destructor of this object).
void name_unlink(type *obj)
Remove the object *obj from the list.
It gives back the ownership of the object to the caller program
which becomes responsible to calling the destructor of this object.
type *name_next_obj(const name_t list, const type *obj)
Return the object that is after the object *obj in the list
or NULL if there is no more object.
type *name_previous_obj(const name_t list, const type *obj)
Return the object that is before the object *obj in the list
or NULL if there is no more object.
void name_insert(name_t list, name_it_t it, type *x)
This method is the same as the generic one, except it is really x that is added in the list, not a copy.
void name_splice_back(name_t list1, name_t list2, name_it_t it)
Move the element pointed by it from the list list2 to the back position of list1.
it shall be an iterator of list2.
Afterwards, it points to the next element of list2.
void name_splice(name_t list1, name_t list2)
Move all the element of list2 into list1, moving the last element
of list2 after the first element of list1.
Afterwards, list2 is emptied.
M-CONCURRENT
This header is for transforming a standard container (LIST, ARRAY, DICT, DEQUE, ...)
into an equivalent container but compatible with concurrent access by different threads.
In practice, it puts a mutex lock to access the container.
As such it is quite generic. However, it is less efficient than containers specially tuned for multiple threads. There is also no iterators.
CONCURRENT_DEF(name, type[, oplist])
CONCURRENT_DEF_AS(name, name_t, type[, oplist])
Define the concurrent container name based on container type of oplist oplist,
and define the associated methods to handle it as static inline functions.
name shall be a C identifier that will be used to identify the concurrent container.
It will be used to create all the types (including the iterator)
and functions to handle the container.
This definition shall be done once per name and per compilation unit.
It scans the oplist of the type to create equivalent function,
so the exact generated methods depend on explicitly the exported methods in the oplist.
The init method is only defined if the base container exports the INIT operator,
same for the clear method and the CLEAR operator,
and so on for all created methods.
In the description below,
subtype_t is the type of the element within the given container type (if it exists),
key_t is the key type of the element within the given container type (if it exists),
value_t is the value type of the element within the given container type (if it exists).
CONCURRENT_DEF_AS is the same as CONCURRENT_DEF except the name of the type name_t
is provided.
Example:
/* Define a stack container (STACK)*/
ARRAY_DEF(array1, int)
CONCURRENT_DEF(parray1, array1_t, ARRAY_OPLIST(array1))
/* Define a queue container (FIFO) */
DEQUE_DEF(deque_uint, unsigned int)
CONCURRENT_DEF(cdeque_uint, deque_uint_t, M_OPEXTEND(DEQUE_OPLIST(deque_uint, M_BASIC_OPLIST), PUSH(deque_uint_push_front)))
extern parray1_t x1;
extern cdeque_uint_t x2;
void f(void) {
parray1_push (x1, 17);
cdeque_uint_push (x2, 17);
}
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the concurrent container of type.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t concurrent)
void name_init_set(name_t concurrent, const name_t src)
void name_init_move(name_t concurrent, name_t src)
void name_set(name_t concurrent, const name_t src)
void name_move(name_t concurrent, name_t src)
void name_reset(name_t concurrent)
void name_clear(name_t concurrent)
void name_swap(name_t concurrent1, name_t concurrent2)
bool name_empty_p(const name_t concurrent)
void name_set_at(name_t concurrent, key_t key, value_t value)
bool name_erase(name_t concurrent, const key_t key)
void name_push(name_t concurrent, const subtype_t data)
void name_push_move(name_t concurrent, subtype_t *data)
void name_pop_move(subtype_t *data, name_t concurrent)
void name_get_str(string_t str, name_t concurrent, bool append)
void name_out_str(FILE *file, name_t concurrent)
bool name_parse_str(name_t concurrent, const char str[], const char **end)
bool name_in_str(name_t concurrent, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t container)
m_serial_return_code_t name_in_str(name_t container, m_serial_read_t serial)
bool name_equal_p(name_t concurrent1, name_t concurrent2)
size_t name_hash(name_t concurrent)
Returns true in case of success, false otherwise.
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
bool name_get_copy(value_t *value, name_t concurrent, key_t key)
Read the value associated to the key key.
If it exists, it sets *value to it and returns true.
Otherwise it returns false (*value is unchanged).
This method is only defined if the base container exports the GET_KEY operator.
void name_safe_get_copy(value_t *value, name_t concurrent, key_t key)
Read the value associated to the key key.
If it exists, it sets *value to it.
Otherwise, it creates a new value (default constructor) and sets *value to it.
This method is only defined if the base container exports the SAFE_GET_KEY operator.
void name_pop(subtype_t *data, name_t concurrent)
Pop data from the container and set it in *data.
There shall be at least one data to pop.
Testing with the operator EMPTY_P before calling this function is not enough
as there can be some concurrent scenario where another thread pop the last value.
name_pop_blocking should be used instead.
This method is only defined if the base container exports the POP operator.
bool name_get_blocking(value_t *value, name_t concurrent, key_t key, bool blocking)
Read the value associated to the key key.
If it exists, it sets *value to it and returns true.
Otherwise, if blocking is true, it waits for the data to be filled.
After the wait, it sets *value to it and returns true.
Otherwise, if blocking is false, it returns false.
This method is only defined if the base container exports the GET_KEY operator.
bool name_pop_blocking(type_t *data, name_t concurrent, bool blocking)
Pop a value from the container and set *data with it.
If the container is not empty, it sets *data and return true.
Otherwise, if blocking is true, it waits for the data to be pushed.
After the wait, it sets *data to it and returns true.
Otherwise, if blocking is false, it returns false.
This method is only defined if the base container exports the POP and EMPTY_P operators.
bool name_pop_move_blocking(type_t *data, name_t concurrent, bool blocking)
Pop a value from the container and initialize and set *data with it.
If the container is not empty, it initializes and sets *data and return true.
Otherwise if blocking is true, it waits for the data to be pushed.
After the wait, it initializes and sets *data to it and returns true.
Otherwise, if blocking is false, it returns false.
[!WARNING]
*dataremains uninitialized!
This method is only defined if the base container exports the POP_MOVE and EMPTY_P operators.
M-BITSET
This header is for using bitset.
A bitset can be seen as a specialized version of an array of bool, where each item takes only 1 bit. It enables for compact representation of such array.
Example:
void f(void) {
bitset_t set;
bitset_init(set);
for(int i = 0; i < 100; i ++)
bitset_push_back(set, i%2);
bitset_clear(set);
}
Methods, types & constants
The following methods are available:
bitset_t
This type defines a dynamic array of bit and is the primary type of the module.
bitset_it_t
This type defines an iterator over the bitset.
void bitset_init(bitset_t array)
Initialize the bitset array (aka constructor) to an empty array.
void bitset_init_set(bitset_t array, const bitset_t ref)
Initialize the bitset array (aka constructor) and set it to the value of ref.
void bitset_set(bitset_t array, const bitset_t ref)
Set the bitset array to the value of ref.
void bitset_init_move(bitset_t array, bitset_t ref)
Initialize the bitset array (aka constructor) by stealing as many
resources from ref as possible. Afterwards ref is cleared.
void bitset_move(bitset_t array, bitset_t ref)
Set the bitset array by stealing as many resources from ref as possible.
Afterwards ref is cleared.
void bitset_clear(bitset_t array)
Clear the bitset array (aka destructor).
void bitset_reset(bitset_t array)
Reset the bitset. The bitset becomes empty but remains initialized.
void bitset_push_back(bitset_t array, const bool value)
Push a new element into the back of the bitset array
with the value value.
void bitset_push_at(bitset_t array, size_t key, const bool value)
Push a new element into the position key of the bitset array
with the value value.
key shall be a valid position of the array:
from 0 to the size of array (included).
void bitset_pop_back(bool *data, bitset_t array)
Pop a element from the back of the bitset array and set *data to this value
if data is not NULL (if data is NULL, the popped data is cleared).
void bitset_pop_at(bool *dest, bitset_t array, size_t key)
Set *dest to the value the element key if dest is not NULL,
then remove the element key from the bitset.
key shall be within the size of the bitset.
bool bitset_front(const bitset_t array)
Return the first element of the bitset. The bitset shall have at least one element.
bool bitset_back(const bitset_t array)
Return the last element of the bitset. The bitset shall have at least one element.
void bitset_set_at(bitset_t array, size_t i, bool value)
Set the element i of bitset array to value.
i shall be within 0 to the size of the array (excluded).
void bitset_flip_at(bitset_t array, size_t i)
Flip the element i of bitset array'.
i shall be within 0 to the size of the array (excluded).
bool bitset_get(bitset_t array, size_t i)
Return the element i of the bitset.
i shall be within 0 to the size of the array (excluded).
bool bitset_empty_p(const bitset_t array)
Return true if the bitset is empty, false otherwise.
size_t bitset_size(const bitset_t array)
Return the size of the bitset.
size_t bitset_capacity(const bitset_t array)
Return the capacity of the bitset.
void bitset_resize(bitset_t array, size_t size)
Resize the bitset array to the size size (initializing or clearing elements).
void bitset_reserve(bitset_t array, size_t capacity)
Extend or reduce the capacity of the array to a rounded value based on capacity.
If the given capacity is below the current size of the bitset,
the capacity is set to the size of the bitset.
void bitset_swap(bitset_t array1, bitset_t array2)
Swap the bitsets array1 and array2.
void bitset_swap_at(bitset_t array, size_t i, size_t j)
Swap the elements i and j of the bitset array.
i and j shall reference valid elements of the array.
void bitset_it(bitset_it_t it, bitset_t array)
Set the iterator it to the first element of array.
void bitset_it_last(bitset_it_t it, bitset_t array)
Set the iterator it to the last element of array.
void bitset_it_end(bitset_it_t it, bitset_t array)
Set the iterator it to the end of array.
void bitset_it_set(bitset_it_t it1, bitset_it_t it2)
Set the iterator it1 to it2.
bool bitset_end_p(bitset_it_t it)
Return true if the iterator doesn't reference a valid element anymore.
bool bitset_last_p(bitset_it_t it)
Return true if the iterator references the last element of the array, or doesn't reference a valid element.
bool bitset_it_equal_p(const bitset_it_t it1, const bitset_it_t it2)
Return true if both iterators reference the same element.
void bitset_next(bitset_it_t it)
Move the iterator it to the next element of the array.
void bitset_previous(bitset_it_t it)
Move the iterator it to the previous element of the array.
const bool *bitset_cref(const bitset_it_t it)
Return a constant pointer to the element pointed by the iterator. This pointer remains valid until the array or the iterator is modified by another method.
void bitset_get_str(string_t str, const bitset_t array, bool append)
Generate a formatted string representation of the bitset array and set str to this
representation (if append is false) or append str with this representation
(if append is true).
This method is only defined if the header m-string.h was included before
including m-bitset.h
bool bitset_parse_str(bitset_t array, const char str[], const char **endp)
Parse the formatted string str that is assumed to be a string representation of a bitset
and set array to this representation.
It returns true if success, false otherwise.
If endp is not NULL, it sets *endp to the pointer of the first character not
decoded by the function.
void bitset_out_str(FILE *file, const bitset_t array)
Generate a formatted string representation of the bitset array
and outputs it into the FILE file.
void bitset_in_str(bitset_t array, FILE *file)
Read from the file file a formatted string representation of a bitset
and set array to this representation.
bool bitset_equal_p(const bitset_t array1, const bitset_t array2)
Return true if both bitsets array1 and array2 are equal.
size_t bitset_hash(const bitset_t array)
Return a hash value of array.
void bitset_and(bitset_t dst, const bitset_t src)
Perform a bitwise AND operation in dst between dst and src
(effectively performing an intersection of the sets).
void bitset_or(bitset_t dst, const bitset_t src)
Perform a bitwise OR operation in dst between dst and src
(effectively performing an union of the sets).
void bitset_xor(bitset_t dst, const bitset_t src)
Perform a bitwise XOR operation in dst between dst and src.
void bitset_not(bitset_t dst)
Perform a bitwise NOT operation for dst.
size_t bitset_clz(const bitset_t src)
Return the leading zero position in src (Count Leading Zero).
size_t bitset_popcount(const bitset_t src)
Count the number of 1 in src.
M-STRING
This header is for using dynamic string. The size of the string is automatically updated in function of the needs.
Example:
void f(void) {
string_t s1;
string_init (s1);
string_set_str (s1, "Hello, world!");
string_clear(s1);
}
The basic usage is a string of ASCII byte-character. However, the functions supports also UTF-8 encoded string (except said otherwise). It supports encoding/decoding of UTF8 code point.
Methods, types & constants
The following methods are available:
string_t
This type defines a dynamic string and is the primary type of the module. The provided methods are just handy wrappers to the C library, providing few algorithms on its own.
STRING_FAILURE
Constant Macro defined as the index value returned in case of error.
(equal as -1U).
string_fgets_t
This type defines the different enumerate value for the string_fgets function:
STRING_READ_LINE— read a full line until theEOLcharacter (included),STRING_READ_PURE_LINE— read a full line until theEOLcharacter (excluded),STRING_READ_FILE— read the full file.
void string_init(string_t str)
Init the string str to an empty string.
void string_clear(string_t str)
Clear the string str and frees any allocated memory.
char *string_clear_get_str(string_t v)
Clear the string str and returns the allocated array of char,
representing a C string, giving back ownership of this array to the caller.
This array will have to be freed. It can return NULL if no array
was allocated by the string.
void string_reset(string_t str)
Reset the string str to an empty string.
size_t string_size(const string_t str)
Return the size in bytes of the string.
It can be also the number of characters of the string
if the encoding type is one character per byte.
If the characters are encoded as UTF8, the function string_length_u is preferred.
size_t string_capacity(const string_t str)
Return the capacity in bytes of the string. The capacity is the number of bytes the string accept before a reallocation of the underlying array of char has to be performed.
char string_get_char(const string_t v, size_t index)
Return the byte at position index of the string v.
index shall be within the allowed range of bytes of the string.
void string_set_char(string_t v, size_t index, const char c)
Set the byte at position index of the string v to c.
index shall be within the allowed range of bytes of the string.
bool string_empty_p(const string_t v)
Return true if the string is empty, false otherwise.
void string_reserve(string_t v, size_t alloc)
Update the capacity of the string to be able to receive at least
alloc bytes.
Calling with alloc lower or equal than the size of the string
enables the function to perform a shrink
of the string to its exact needs. If the string is
empty, it will free the memory.
void string_set_str(string_t v, const char str[])
Set the string to the array of char str.
str is supposed to be \0 terminated as any C string.
void string_set_strn(string_t v, const char str[], size_t n)
Set the string to the array of char str by copying at most n
char from the array.
str is supposed to be \0 terminated as any C string.
const char *string_get_cstr(const string_t v)
Return a constant pointer to the underlying array of char of the string.
This array of char is terminated by \0, enabling the pointer to be passed
to standard C function.
The pointer remains valid until the string itself remains valid
and the next call to a function that updates the string.
void string_set (string_t v1, const string_t v2)
Set the string v1 to the value of the string v2.
void string_set_n(string_t v, const string_t ref, size_t offset, size_t length)
Set the string to the value of the string ref by skipping the first offset
char of the array of char of ref and copying at most length char
in the remaining array of characters of ref.
offset shall be within the range of index of the string ref.
ref and v cannot be the same string.
void string_set_si (string_t v1, const int n)
void string_set_ui (string_t v1, const unsigned n)
Set the string v1 to the character representation of the integer n.
void string_init_set(string_t v1, const string_t v2)
Initialize v1 to the value of the string v2.
void string_init_set_str(string_t v1, const char str[])
Initialize v1 to the value of the array of char str.
The array of char shall be terminated with \0.
void string_init_move(string_t v1, string_t v2)
Initialize v1 by stealing as most resource from v2 as possible
and clear v2 afterward.
void string_move(string_t v1, string_t v2)
Set v1 by stealing as most resource from v2 as possible
and clear v2 afterward.
void string_swap(string_t v1, string_t v2)
Swap the content of both strings.
void string_push_back (string_t v, char c)
Append the character c to the string v
void string_cat_str(string_t v, const char str[])
Append the array of char str to the string v.
The array of char shall be terminated with \0.
void string_cat(string_t v, const string_t v2)
Append the string v2 to the string v.
[!NOTE]
v2can also be aconst char*in C11.
void string_cats(string_t v, const string_t v2[, ...] )
Append all the strings v2, ... to the string v.
[!NOTE]
v2can also be aconst char*in C11.
void string_sets(string_t v, const string_t v2[, ...] )
Set the string v to the concatenation of all the strings v2
[!NOTE]
v2can also be aconst char*in C11.
int string_cmp_str(const string_t v1, const char str[])
int string_cmp(const string_t v1, const string_t str)
Perform a byte comparison of both string by using the strcmp function and return the result of this comparison.
bool string_equal_str_p(const string_t v1, const char str[])
Return true if the string is equal to the array of char, false otherwise.
bool string_equal_p(const string_t v1, const string_t v2)
Return true if both strings are equal, false otherwise.
int string_cmpi_str(const string_t v, const char str[])
int string_cmpi(const string_t v, const string_t str)
This function compares both strings by ignoring the difference due to the case. This function doesn't work with UTF-8 strings. It returns a negative integer if the string is before the array, 0 if there are equal, a positive integer if the string is after the array.
size_t string_search_char (const string_t v, char c [, size_t start])
Search for the character c in the string from the offset start.
start shall be within the valid ranges of offset of the string.
start is an optional argument. If it is not present, the default
value 0 is used instead.
This doesn't work if the function is used as function pointer.
Return the offset of the string where the character is first found,
or STRING_FAILURE otherwise.
size_t string_search_rchar (const string_t v, char c [, size_t start])
Search backwards for the character c in the string from the offset start.
start shall be within the valid ranges of offset of the string.
start is an optional argument. If it is not present, the default
value 0 is used instead.
This doesn't work if the function is used as function pointer.
Return the offset of the string where the character is last found,
or STRING_FAILURE otherwise.
size_t string_search_str (const string_t v, char str[] [, size_t start])
size_t string_search (const string_t v, string_t str [, size_t start])
Search for the string str in the string from the offset start.
start shall be within the valid ranges of offset of the string.
start is an optional argument. If it is not present, the default
value 0 is used instead.
This doesn't work if the function is used as function pointer.
Return the offset of the string where str is first found,
or STRING_FAILURE otherwise.
size_t string_pbrk(const string_t v, const char first_of[] [, size_t start])
Search for the first occurrence in the string v from the offset start of
any the bytes in the string first_of.
start shall be within the valid ranges of offset of the string.
start is an optional argument. If it is not present, the default
value 0 is used instead.
This doesn't work if the function is used as function pointer.
Return the offset of the string where str is first found,
or STRING_FAILURE otherwise.
int string_strcoll_str(const string_t str1, const char str2[])
int string_strcoll(const string_t str1, const string_t str2[])
Compare the two strings str1 and str2.
It returns an integer less than, equal to, or greater than zero if s1 is found,
respectively, to be less than, to match, or be greater than s2. The
comparison is based on strings interpreted as appropriate for the program's
current locale.
size_t string_spn(const string_t v1, const char accept[])
Calculate the length (in bytes) of the initial segment of the string that consists entirely of bytes in accept.
size_t string_cspn(const string_t v1, const char reject[])
Calculate the length (in bytes) of the initial segment of the string that consists entirely of bytes not in reject.
void string_left(string_t v, size_t index)
Keep at most the index left bytes of the string,
terminating the string at the given index.
index can be out of range.
void string_right(string_t v, size_t index)
Keep the right part of the string, after the index index.
void string_mid (string_t v, size_t index, size_t size)
Extract the medium string from offset index and up to size bytes.
size_t string_replace_str (string_t v, const char str1[], const char str2[] [, size_t start])
size_t string_replace (string_t v, const string_t str1, const string_t str2 [ , size_t start])
Replace in the string v from the offset start
the string str1 by the string str2 once.
Returns the offset of the replacement or STRING_FAILURE if no replacement
was performed.
str1 shall be a non-empty string.
size_t string_replace_all_str (string_t v, const char str1[], const char str2[])
size_t string_replace_all (string_t v, const string_t str1, const string_t str2)
Replace in the string v all the occurrences of
the string str1 by the string str2.
str1 shall be a non-empty string.
void string_replace_at (string_t v, size_t pos, size_t len, const char str2[])
Replace in the string v the sub-string defined as starting from pos and
of size len by the string str2.
It assumes that pos + len is before the end of the string of v.
void string_init_printf(string_t v, const char format[], ...)
Initialize v to the formatted string format with the given variable argument lists.
format is like the printf function family.
void string_init_vprintf(string_t v, const char format[], va_list args)
Initialize v to the formatted string format with the given variable argument lists args.
format is like the printf function family.
int string_printf (string_t v, const char format[], ...)
Set the string v to the formatted string format.
format is like the printf function family with the given variable argument list.
Return the number of characters printed (excluding the final \0 char), or a negative value in case of error.
int string_vprintf (string_t v, const char format[], va_list args)
Set the string v to the formatted string format.
format is like the vprintf function family with the variable argument list args.
Return the number of characters printed (excluding the final \0 char), or a negative value in case of error.
int string_cat_printf (string_t v, const char format[], ...)
Appends to the string v the formatted string format.
format is like the printf function family.
bool string_fgets(string_t v, FILE *f, string_fgets_t arg)
Read from the opened file f a stream of characters and set v
with this stream.
It stops after the character end of line
if arg is STRING_READ_PURE_LINE or STRING_READ_LINE,
and until the end of the file if arg is STRING_READ_FILE.
If arg is STRING_READ_PURE_LINE, the character end of line
is removed from the string.
Return true if something has been read, false otherwise.
bool string_fget_word (string_t v, const char separator[], FILE *f)
Read a word from the file f and set v with this word.
A word is separated from another by the list of characters in the array separator.
(Example: ^ \t.\n).
It is highly recommended for separator to be a constant string.
separator shall be at most composed of 100 bytes.
It works with UTF8 stream with the restriction that the separator character shall only be ASCII character.
void string_fputs(FILE *f, const string_t v)
Put the string in the file.
bool string_start_with_str_p(const string_t v, const char str[])
bool string_start_with_string_p(const string_t v, const string_t str)
Return true if the string starts with the same characters than str,
false otherwise.
bool string_end_with_str_p(const string_t v, const char str[])
bool string_end_with_string_p(const string_t v, const string_t str)
Return true if the string ends with the same characters than str,
false otherwise.
size_t string_hash(const string_t v)
Return a hash of the string.
void string_strim(string_t v [, const char charTab[]])
Remove from the string any leading or trailing space-like characters
(space or tabulation or end of line).
If charTab is given, it get the list of characters to remove from
this argument.
bool string_oor_equal_p(const string_t v, unsigned char n)
Provide the OOR_EQUAL_P method of a string.
void string_oor_set(string_t v, unsigned char n)
Provide the OOR_SET method of a string.
void string_get_str(string_t v, const string_t v2, bool append)
Convert a string into a formatted string usable for I/O:
Outputs the input string with quote around,
replacing any " by \" within the string
into the output string.
bool string_parse_str(string_t v, const char str[], const char **endp)
Parse the formatted string str that is assumed to be a string representation of a string
and set v to this representation.
This method is only defined if the type of the element defines a PARSE_STR method itself.
It returns true if success, false otherwise.
If endp is not NULL, it sets *endp to the pointer of the first character not
decoded by the function.
void string_out_str(FILE *f, const string_t v)
Write a string into a FILE* as a formatted string:
Outputs the input string while quoting around,
replacing any " by \" within the string,
and quote special characters.
bool string_in_str(string_t v, FILE *f)
Read a formatted string from a FILE*. The string shall follow the formatting rules of string_out_str.
It returns true if it has successfully parsed the string,
false otherwise. In this case, the position within the FILE*
is undefined.
string_unicode_t
Define a type suitable to store an unicode code point as an integer.
string_it_t
Define an iterator over the string, enabling to iterate the string over UTF8 encoded code point.
The basic element of the string is a byte. An UTF-8 code point is composed of one to four bytes, encoded in a variable way. However, a Unicode character can be also composed of one or more code point. (See UTF-8 )
This library doesn't provide any treatment over code points.
void string_it(string_it_t it, const string_t str)
Initialize the iterator it to iterate over the UTF-8 code points of
string str.
void string_it_end(string_it_t it, const string_t str)
Initialize the iterator it to the end iteration of the string str.
void string_it_set(string_it_t it1, const string_it_t it2)
Initialize the iterator it1 to the same position than it2.
void string_it_pos(string_it_t it, const string_t str, size_t pos)
Initialize the iterator it to iterate over the UTF-8 code points
of string str, starting from position pos.
pos shall be within the size of the string.
pos shall reference the starting point of an UTF-8 code point.
bool string_end_p (string_it_t it)
Return true if the iterator has reached the end of the string, false otherwise.
void string_next (string_it_t it)
Move the iterator to the next UTF8 encoded code point.
void string_previous (string_it_t it)
Move the iterator to the previous UTF8 encoded code point.
string_unicode_t string_get_cref (const string_it_t it)
Return the unicode code point associated to the iterator.
It returns -1 in case of error in decoding the UTF8 string.
size_t string_it_get_pos (const string_it_t it)
Return the position in the stream of the iterator it.
void string_it_set_ref(string_it_t it, string_t str, string_unicode_t u)
Replace the unicode code point referenced by it to the unicode code point u
in the string str.
If u is 0, then it will resize the string to the size of the referenced iterator
only keeping the unicode code points before the iterator.
it shall be a valid iterator of str.
bool string_it_equal_p (const string_it_t it1, const string_it_t it2)
Return true if both iterators reference the same position, false otherwise.
void string_push_u (string_t str, string_unicode_t u)
Push the unicode code point u into the string str
encoding it as a variable UTF8 encoded code point.
bool string_pop_u (string_unicode_t *u, string_t str)
Pop the last unicode code point from the string str
encoded as a variable UTF8 encoded code point
and store in *u the popped unicode code point if u is not NULL.
It returns true in case of success or false otherwise (no character to pop or no valid UTF8).
size_t string_length_u(string_t str)
Return the number of UTF8 encoded code point in the string.
bool string_utf8_p(string_t str)
Return true if the string is a valid UTF8, false otherwise. It doesn't check for unique canonical form for UTF8 string.
STRING_CTE(string)
Macro to convert a constant C string into a temporary string_t variable
suitable only for being called within a function.
STRING_OPLIST
The oplist of a string_t
BOUNDED_STRING_DEF(name, size)
Define a bounded string of size size, aka char[ size + 1 ] (including the final \0 char).
Created types
The following types are automatically defined by the previous definition macro if not provided by the user:
name_t
Type of the concurrent container of type.
Generic methods
The following methods of the generic interface are defined (See generic interface for details):
void name_init(name_t bounded_string)
void name_init_set(name_t bounded_string, const name_t src)
void name_set(name_t bounded_string, const name_t src)
void name_reset(name_t bounded_string)
void name_clear(name_t bounded_string)
size_t name_size(const name_t bounded_string)
size_t name_capacity(const name_t bounded_string)
bool name_empty_p(const name_t bounded_string)
void name_get_str(string_t str, name_t bounded_string, bool append)
void name_out_str(FILE *file, name_t bounded_string)
bool name_parse_str(name_t bounded_string, const char str[], const char **end)
bool name_in_str(name_t bounded_string, FILE *file)
m_serial_return_code_t name_out_serial(m_serial_write_t serial, const name_t bounded_string)
m_serial_return_code_t name_in_str(name_t bounded_string, m_serial_read_t serial)
bool name_equal_p(name_t bounded_string1, name_t bounded_string2)
int name_cmp(const name_t bounded_string1, const name_t bounded_string2)
size_t name_hash(name_t bounded_string)
Specialized methods
The following specialized methods are automatically created by the previous definition macro:
void name_init_set_cstr(bounded_t string, const char str[])
Initialize the bounded string to the given C string str, truncating if needed.
void name_set_cstr(bounded_t string, const char str[])
Set the bounded string string to the given C string str, truncating if needed.
void name_set_cstrn(bounded_t string, const char str[], size_t n)
Set the bounded string string to the n first byte characters of the given C string str, truncating if needed.
void name_set_n(bounded_t string, const bounded_t string, size_t offset, size_t length)
Set the bounded string string to the length first byte characters from the offset offset
of the bounded given C string str, truncating if needed.
const char *name_get_cstr(const bounded_t string)
Return the C string representation of the bounded string.
char name_get_char(const bounded_t string, size_t index)
Return the byte character at the given index of the string.
index shall be within the size of the string.
void name_cat(bounded_t string, const bounded_t str)
void name_cat_cstr(bounded_t string, const char str[])
Concat the given C string to the bounded string.
int name_cmp_cstr(const bounded_t string, const char str[])
Compared the bounded string to the given C string:
return a negative integer if the bounded string is before the C string,
0 if there are equals,
a positive integer otherwise.
bool name_equal_cstr_p(const bounded_t string, const char str[])
Return true if the bounded string is equal to the given C string.
int name_printf(bounded_t string, const char format[], ...)
Set the bounded string to the format C string.
int name_cat_printf(bounded_t string, const char format[], ...)
Concat to the bounded string the format C string.
bool name_fgets(bounded_t string, FILE *f, string_fgets_t arg)
Read at most max_size + 1 bytes from the file f and set the bounded string to it.
bool name_fputs(FILE *f, const bounded_t string)
Put the bounded string to the file f.
bool name_oor_equal_p(const bounded_t string, unsigned char n)
Provide the OOR_EQUAL_P method of a string.
void name_oor_set(bounded_t string, unsigned char n)
Provide the OOR_SET method of a string.
M-BSTRING
This header is for using dynamic string of bytes (including null byte) The size of the string is automatically updated in function of the needs.
Example:
void f(void) {
bstring_t s1;
bstring_init (s1);
bstring_push_back (s1, 0);
bstring_clear(s1);
}
Methods, types & constants
The following methods are available:
bstring_t
This type defines a dynamic string of byte.
void bstring_init(bstring_t str)
Init the byte string str to an empty string.
void bstring_clear(bstring_t str)
Clear the byte string str and free any allocated memory.
void bstring_reset(bstring_t str)
Reset the byte string str to an empty string.
size_t bstring_size(const bstring_t str)
Return the size in bytes of the string.
size_t bstring_capacity(const bstring_t str)
Return the capacity in bytes of the string. The capacity is the number of bytes the string accept before a reallocation of the underlying array of char has to be performed.
uint8_t bstring_get_byte(const bstring_t v, size_t index)
Return the byte at position index of the byte string v.
index shall be within the allowed range of bytes of the string.
void bstring_set_byte(bstring_t v, size_t index, const uint8_t c)
Set the byte at position index of the byte string v to c.
index shall be within the allowed range of bytes of the string.
bool bstring_empty_p(const bstring_t v)
Return true if the byte string is empty, false otherwise.
void bstring_reserve(bstring_t v, size_t alloc)
Update the capacity of the byte string to be able to receive at least
alloc bytes.
Calling with alloc lower or equal than the size of the string
enables the function to perform a shrink
of the string to its exact needs. If the string is
empty, it will free the memory.
void bstring_set (bstring_t v1, const bstring_t v2)
Set the byte string v1 to the value of the string v2.
void bstring_init_set(bstring_t v1, const bstring_t v2)
Initialize v1 to the value of the byte string v2.
void bstring_init_move(bstring_t v1, bstring_t v2)
Initialize v1 by stealing as most resource from v2 as possible
and clear v2 afterward.
void bstring_move(bstring_t v1, bstring_t v2)
Set v1 by stealing as most resource from v2 as possible
and clear v2 afterward.
void bstring_swap(bstring_t v1, bstring_t v2)
Swap the content of both byte strings.
void bstring_push_back (bstring_t v, uint8_t c)
Append the byte c to the byte string v
void bstring_push_back_bytes (bstring_t v, size_t n, const void *buffer)
Append the buffer of 'n' bytes to the byte string v
void bstring_splice (bstring_t dst, bstring_t src)
Append the byte string src to the byte string dst,
emptying 'src' afterwards.
uint8_t bstring_pop_back (bstring_t v)
Pop the last byte of the byte string v
The byte string shall be not empty.
void bstring_pop_back_bytes (size_t n, void *buffer, bstring_t v)
Pop the 'n' last bytes of the byte string v and copy them in 'buffer'
The byte string shall have at least 'n' bytes.
uint8_t bstring_pop_front (bstring_t v)
Pop the first byte of the byte string v
The byte string shall be not empty.
void bstring_pop_front_bytes (size_t n, void *buffer, bstring_t v)
Pop the 'n' first bytes of the byte string v and copy them in 'buffer'
The byte string shall have at least 'n' bytes.
void m_bstring_push_bytes_at (m_bstring_t v, size_t pos, size_t n, const void *buffer)
Push (Insert) the 'n' bytes of 'buffer' at the position 'pos' of the byte string 'v'. The position 'pos' shall be within the boundary of the byte string (0 to the size of the byte string).
void m_bstring_pop_bytes_at(size_t n, void *buffer, m_bstring_t v, size_t pos)
Pop the 'n' bytes at position 'pos' of the byte string 'v' and copy them in 'buffer' The position 'pos' shall be within the boundary of the byte string (0 to the size of the byte string). The byte string shall have at least 'n' bytes from position 'pos' in the byte string.
int bstring_cmp_bytes(const bstring_t v1, size_t s2, const void *p2)
int bstring_cmp(const bstring_t v1, const bstring_t str)
Perform a byte comparison of both byte strings by using the memcmp function and return the result of this comparison.
bool bstring_equal_bytes_p(const bstring_t v1, size_t s2, const void *p2)
bool bstring_equal_p(const bstring_t v1, const bstring_t v2)
Return true if both strings are equal, false otherwise.
void m_bstring_resize (m_bstring_t v, size_t n)
Resize the byte string to be 'n' bytes, appending by 0 if it increases the size of the byte string, truncating otherwise.
void m_bstring_reserve (m_bstring_t v, size_t n)
Extend or reduce the capacity of the c to a rounded value based on n.
If the given capacity is below the current size of the container,
the capacity is set to a rounded value based on the size of the container.
Therefore a capacity of 0 is used to perform a shrink-to-fit operation on the container,
i.e. reducing the container usage to the minimum possible allocation.
const uint8_t * m_bstring_view(const m_bstring_t v, size_t offset, size_t size_requested)
Return a constant byte pointer to the sub string at position 'offset' and of size '##### const uint8_t * m_bstring_view(const m_bstring_t v, size_t offset, size_t size_requested)
' of the byte string 'v'
The position 'offset' shall be within the boundary of the byte string (0 to the size of the byte string).
The byte string shall have at least 'size_requested' bytes from position 'offset' in the byte string.
The returned pointer is valid until a modification is done on the byte string.
uint8_t *m_bstring_acquire_access(m_bstring_t v, size_t offset, size_t size_requested)
Acquire direct access to the byte string, allowing to write directly in it.
Return a modifiable byte pointer to the sub string at position 'offset' and of size '##### const uint8_t * m_bstring_view(const m_bstring_t v, size_t offset, size_t size_requested)
' of the byte string 'v'
The position 'offset' shall be within the boundary of the byte string (0 to the size of the byte string).
The byte string shall have at least 'size_requested' bytes from position 'offset' in the byte string.
After calling this service, the container is put in direct access mode and won't allow any other API usage until m_bstring_release_access is called.
void m_bstring_release_access(m_bstring_t v)
Release direct access mode to the byte string, allowing other API calls to be performed.
This service shall be the only one being called after calling m_bstring_acquire_access
bool bstring_fread(bstring_t v, FILE *f, size_t num)
Read from the opened file f a stream of 'num' bytes and set v
with this stream.
Return true if everything has been read, false otherwise.
size bstring_fwrite(FILE *f, const bstring_t v)
Put the byte string in the file, returning the number of bytes written.
size_t bstring_hash(const bstring_t v)
Return a hash of the byte string.
BSTRING_OPLIST
The oplist of a bstring_t
M-CORE
This header is the internal core of M*LIB, providing a lot of functionality by extending the preprocessing capability. Working with these macros is not easy and the developer needs to know how the macro preprocessing works. It also adds the needed macro for handling the oplist. As a consequence, it is needed by all other header files.
A few macros are using recursion to work.
This is not an easy feat to do as it needs some tricks to work (see
reference).
This still work well with only one major limitation: it can not be chained.
For example, if MACRO is a macro implementing recursion, then
MACRO(MACRO()) won't work.
Example:
M_MAP(f, 1, 2, 3, 4)
M_REDUCE(f, g, 1, 2, 3, 4)
M_SEQ(1, 20, f)
Compiler Macros
The following compiler macros are available:
M_ASSUME(cond)
M_ASSUME is equivalent to assert, but gives hints to compiler
about how to optimize the code if NDEBUG is defined.
M_LIKELY(cond) / M_UNLIKELY(cond)
M_LIKELY / M_UNLIKELY gives hints on the compiler of the likelihood
of the given condition.
Preprocessing macro extension
M_MAX_NB_ARGUMENT
Maximum default number of argument that can be handled by this header. It is currently 52 (even if some local macros may have increased this limit).
M_C(a,b)
M_C3(a,b,c)
M_C4(a,b,c,d)
Return a symbol corresponding to the concatenation of the input arguments.
M_F(base, suffix)
Return a function name corresponding to the concatenation of the input arguments.
In developer mode, it can be overrided before inclusion of any header to support user customization of suffix.
To do this you need to define M_F as M_OVERRIDE_F, then define as many suffix macros as needed. As suffix macro shall be named M_OVERRIDE_ ## suffix () and each generated suffix shall start with a comma (preliminary interface).
Example:
#define M_F(a,b) M_OVERRIDE_F(a,b)
#define M_OVERRIDE__clear() , _cleanup ,
#include "m-core.h"
M_INC(number)
Increment the number given as argument and return
a pre-processing token corresponding to this value (meaning it is evaluated
at macro processing stage, not at compiler stage).
The number shall be within the range [ 0..M_MAX_NB_ARGUMENT - 1 ].
M_DEC(number)
Decrement the number given as argument and return
a pre-processing token corresponding to this value (meaning it is evaluated
at macro processing stage, not at compiler stage).
The number shall be within the range [ 1..M_MAX_NB_ARGUMENT ].
M_ADD(x, y)
Return x+y (resolution is performed at preprocessing time).
x, y shall be within [ 0..M_MAX_NB_ARGUMENT ].
If the result is not in [ 0..M_MAX_NB_ARGUMENT + 1 ], it returns M_OVERFLOW.
M_SUB(x, y)
Return x and y (resolution is performed at preprocessing time).
x, y shall be within [ 0..M_MAX_NB_ARGUMENT ].
If the result is not in [ 0..M_MAX_NB_ARGUMENT ], it returns M_UNDERFLOW.
M_BOOL(cond)
Convert an integer or a symbol into 0 (if 0) or 1 (if not 0 or symbol unknown).
Return a pre-processing token corresponding to this value (meaning it is evaluated
at macro processing stage, not at compiler stage).
M_INV(cond)
Inverse 0 into 1 and 1 into 0. It is undefined if cond is not 0 or 1
(You could use M_BOOL to convert).
Return a pre-processing token corresponding to this value (meaning it is evaluated
at macro processing stage, not at compiler stage).
M_AND(cond1, cond2)
Perform a logical AND between cond1 and cond2.
cond1 and cond2 shall be 0 or 1.
(You could use M_BOOL to convert).
Return a pre-processing token corresponding to this value (meaning it is evaluated
at macro processing stage, not at compiler stage).
M_OR(cond1, cond2)
Perform a logical OR between cond1 and cond2.
cond1 and cond2 shall be 0 or 1.
(You could use M_BOOL to convert).
Return a pre-processing token corresponding to this value (meaning it is evaluated
at macro processing stage, not at compiler stage).
M_NOTEQUAL(x, y)
Return 1 if x != y, 0 otherwise (resolution is performed at preprocessing time).
x and y shall be within [ 0..M_MAX_NB_ARGUMENT ].
M_EQUAL(x, y)
Return 1 if x == y, 0 otherwise (resolution is performed at preprocessing time).
x and y shall be within [ 0..M_MAX_NB_ARGUMENT ].
M_LESS_THAN_P(x, y)
Return 1 if x < y, 0 otherwise (resolution is performed at preprocessing time).
x and y shall be within [ 0..M_MAX_NB_ARGUMENT ].
M_LESS_OR_EQUAL_P(x, y)
Return 1 if x <= y, 0 otherwise (resolution is performed at preprocessing time).
x and y shall be within [ 0..M_MAX_NB_ARGUMENT ].
M_GREATER_OR_EQUAL_P(x, y)
Return 1 if x >= y, 0 otherwise (resolution is performed at preprocessing time).
x and y shall be within [ 0..M_MAX_NB_ARGUMENT ].
M_GREATER_THAN_P(x, y)
Return 1 if x > y, 0 otherwise (resolution is performed at preprocessing time).
x and y shall be within [ 0..M_MAX_NB_ARGUMENT ].
M_COMMA_P(arglist)
Return 1 if there is a comma inside the argument list, 0 otherwise. Return a pre-processing token corresponding to this value (meaning it is evaluated at macro processing stage, not at compiler stage).
M_EMPTY_P(expression)
Return 1 if the argument expression is empty, 0 otherwise.
Return a pre-processing token corresponding to this value (meaning it is evaluated
at macro processing stage, not at compiler stage).
[!NOTE] It should work for a wide range of inputs except when it is called with a macro function that takes more than one argument and without its arguments (in which case it generates a compiler error). It also won't work for expression starting with
)
M_PARENTHESIS_P(expression)
Return 1 if the argument expression starts with a parenthesis and ends with it
(like (...)), 0 otherwise.
Return a pre-processing token corresponding to this value (meaning it is evaluated
at macro processing stage, not at compiler stage).
M_KEYWORD_P(reference_keyword, get_keyword)
Return 1 if the argument get_keyword is equal to reference_keyword,
0 otherwise.
reference_keyword shall be a keyword in the following list:
andoradd(or sum, they are considered equivalent)mul(or product, they are considered equivalent)voidboolcharshortintlongfloatdoubleTYPESUBTYPEIT_TYPEM_OVERFLOWM_UNDERFLOWSEQUENCEMAPKEYVALKEYVAL_PTR
M_IF(cond)(action_if_true, action_if_false)
Return the pre-processing token action_if_true if cond is true,
action_if_false otherwise (meaning it is evaluated
at macro processing stage, not at compiler stage).
cond shall be a 0 or 1 as a preprocessing constant.
(You could use M_BOOL to convert).
M_IF_EMPTY(cond)(action_if_true, action_if_false)
Return the pre-processing token action_if_true if cond is empty,
action_if_false otherwise (meaning it is evaluated
at macro processing stage, not at compiler stage).
M_DELAY1(expr)
M_DELAY2(expr)
M_DELAY3(expr)
M_DELAY4(expr)
M_ID(...)
Delay the evaluation by 1, 2, 3 or 4 steps.
This is necessary to write macros that are recursive.
The argument is a macro-function that has to be deferred.
M_ID is an equivalent of M_DELAY1.
M_EVAL(expr)
Perform a complete stage evaluation of the given expression,
removing recursive expression within it.
Only ONE M_EVAL expression is expected in the evaluation chain.
Can not be chained.
M_APPLY(func, args...)
Apply func to (args...) ensuring
that func() isn't evaluated until all args have been also evaluated.
It is used to delay evaluation.
M_EAT(...)
Clobber the input, whatever it is.
M_RET_ARG'N'(arglist...)
Return the argument N of the given arglist.
N shall be within [ 1..76 ].
The argument shall exist in the arglist.
The arglist shall have at least one more argument that N.
M_GET_AT(list, index)
Return the index index of the list list,
which is a list of arguments encapsulated with parenthesis,
(it is not a true C array).
Return the pre-processing token corresponding to this value (meaning it is evaluated
at macro processing stage, not at compiler stage).
M_GET_AT((f_0,f_1,f_2),1)
==>
f_1
M_SKIP_ARGS(N,...)
Skip the Nth first arguments of the argument list.
N shall be within [ 0..M_MAX_NB_ARGUMENT ].
M_SKIP_ARGS(2, a, b, c, d)
==>
c, d
M_KEEP_ARGS(N,...)
Keep the Nth first arguments of the argument list.
N shall be within [ 0..M_MAX_NB_ARGUMENT ].
M_KEEP_ARGS(2, a, b, c, d)
==>
a, b
M_MID_ARGS(first, len,...)
Keep the medium arguments of the argument list,
starting from the 'first'-th one (zero based) and up to len arguments.
first and len shall be within [ 0..M_MAX_NB_ARGUMENT ].
first + len shall be within the argument of the argument list.
M_MID_ARGS(2, 1, a, b, c, d)
==>
c
M_REVERSE(args...)
Reverse the argument list.
M_REVERSE(a, b, c, d)
==>
d, c, b, a
M_MAP(func, args...)
Apply func to each argument of the args... list of argument.
M_MAP(f, 1, 2, 3)
==>
f(1) f(2) f(3)
M_MAP_C(func, args...)
Apply func to each argument of the args... list of argument,
putting a comma between each expanded func(args)
M_MAP_C(f, 1, 2, 3)
==>
f(1) , f(2) , f(3)
M_MAP2(func, data, args...)
Apply func to each couple (data, argument)
with argument an element of the args... list.
M_MAP2(f, d, 1, 2, 3)
==>
f(d, 1) f(d, 2) f(d, 3)
M_MAP2_C(func, data, args...)
Apply func to each couple (data, argument)
with argument an element of the args... list,
putting a comma between each expanded func(argc)
M_MAP2_C(f, d, 1, 2, 3)
==>
f(d, 1) , f(d, 2) , f(d, 3)
M_MAP3(func, data, args...)
Apply func to each tuple (data, number, argument)
with argument an element of the args... list
and number from 1 to N (the index of the list).
M_MAP3(f, d, a, b, c)
==>
f(d, 1, a) f(d, 2, b) f(d, 3, c)
M_MAP3_C(func, data, args...)
Apply func to each tuple (data, number, argument)
with argument an element of the args... list,
and number from 1 to N (the index of the list)
putting a comma between each expanded func(argc)
M_MAP3_C(f, d, a, b, c)
==>
f(d, 1, a) , f(d, 2, b) , f(d, 3, c)
M_CROSS_MAP(func, arglist1, arglist2)
Apply func to each pair composed of one argument of arglist1 and one argument of arglist2,
M_CROSS_MAP(f, (1, 3), (2, 4) )
==>
f(1, 2) f(1, 4) f(3, 2) f(3, 4)
M_CROSS_MAP2(func, data, arglist1, arglist2)
Apply func to each triplet composed of data, one argument of arglist1 and one argument of arglist2,
M_CROSS_MAP2(f, 5, (1, 3), (2, 4) )
==>
f(5, 1, 2) f(5, 1, 4) f(5, 3, 2) f(5, 3, 4)
M_REDUCE(funcMap, funcReduce, args...)
Map the macro funcMap to all given arguments args
and reduce all these computation with the macro funcReduce.
M_REDUCE(f, g, a, b, c)
==>
g( f(a) , g( f(b) , f(c) ) )
M_REDUCE2(funcMap, funcReduce, data, args...)
Map the macro funcMap to all pair (data, arg) of the given argument list args
and reduce all these computation with the macro funcReduce.
M_REDUCE2(f, g, d, a, b, c)
==>
g( f(d, a) , g( f(d, b) , f(d, c) ) )
M_REDUCE3(funcMap, funcReduce, data, args...)
Map the macro funcMap to all tuple (data, number arg) of the given argument list args
with number from 1 to N ( the size of args)
and reduce all these computation with the macro funcReduce.
M_REDUCE3(f, g, d, a, b, c)
==>
g( f(d, 1, a) , g( f(d, 2, b) , f(d, 3, c) ) )
M_SEQ(init, end)
Generate a sequence of number from init to end (included)
M_SEQ(1, 6)
==>
1,2,3,4,5,6
M_REPLICATE(N, value)
Replicate the value value N times.
M_REPLICATE(5, D)
==>
D D D D D
M_REPLICATE_C(N, value)
Replicate the value value N times, separating then by commas.
M_REPLICATE_C(5, D)
==>
D , D , D , D , D
M_FILTER(func, data, ...)
Filter the arglists by keeping only the element that match the function func(data, element)
M_FILTER(M_NOTEQUAL, 8, 1, 3, 4, 8, 9, 8, 10)
==>
1 3 4 9 10
M_FILTER_C(func, data, ...)
Filter the arglists by keeping only the element that match the function func(data, element)
separated by commas.
M_FILTER(M_NOTEQUAL, 8, 1, 3, 4, 8, 9, 8, 10)
==>
1 , 3 , 4 , 9 , 10
M_NARGS(args...)
Return the number of argument of the given list. args shall not be an empty argument.
M_IF_NARGS_EQ1(argslist)(action_if_one_arg, action_otherwise)
Return the pre-processing token action_if_one_arg if argslist has only one argument, action_otherwise otherwise
(meaning it is evaluated at macro processing stage, not at compiler stage).
M_IF_NARGS_EQ2(argslist)(action_if_two_arg, action_otherwise)
Return the pre-processing token action_if_two_arg if argslist has two arguments, action_otherwise otherwise
(meaning it is evaluated at macro processing stage, not at compiler stage).
M_IF_DEBUG(action)
Return the pre-processing token action if the build is compiled in debug mode
(i.e. NDEBUG is undefined).
M_DEFAULT_ARGS(nbExpectedArg, (defaultArgumentlist), argumentList )
Helper macro to redefine a function with one or more default values.
defaultArgumentlist is a list of the default value to complete the
list argumentList to reach the number nbExpectedArg arguments.
Example:
int f(int a, int b, long p, void *q);
#define f(...) f(M_DEFAULT_ARGS(4, (0, 1, NULL), __VA_ARGS__))
The last 3 arguments have their default value as 0 (for b),
1 (for p) and NULL (for q).
Experimental macro. It may disappear or change in a broken way.
M_DEFERRED_COMMA
Return a comma , at a later phase of the macro processing steps
(delay evaluation).
M_AS_STR(expression)
Return the string representation of the evaluated expression.
C11 Macro
These macros are only valid if the program is built in C11 mode:
M_PRINTF_FORMAT(x)
Return the printf format associated to the type of x.
x shall be a basic C variable, printable with printf.
M_FPRINT_ARG(file, x)
Print into a file file using fprintf the variable x.
The format of x is deduced provided that it is a standard numerical C type.
If m-string.h is included, it supports also the type string_t natively.
If the argument is extended (i.e. in the format (var, optype) with optype being either an oplist or a type
with a globally registered oplist), then it will call the OUT_STR method of the oplist on the variable var.
M_GET_STRING_ARG(string,x,append)
Print into the string_t string the variable x.
The format of x is deduced provided that it is a standard numerical C type.
It needs the header m-string.h for working (this macro is only a
wrapper around it).
It supports also the type string_t.
M_PRINT(args...)
Print using printf all the variable in args.
See M_PRINT_ARG for details on the supported variable.
M_FPRINT(file, args...)
Print into a file file using fprintf all the variables in args.
See M_PRINT_ARG for details on the supported variable.
M_AS_TYPE(type, x)
Within a C11 _Generic statement, all expressions must be valid C
expression even if the case is always false, and is not executed.
This can seriously limit the _Generic statement.
This macro overcomes this limitation by returning:
- either the input
xif it is of typetype - or the value
0view as a typetype
So the returned value is always of type type and is safe in a _Generic statement.
C Macro
These macros expand their code at compilation level:
M_MIN(x, y)
Return the minimum of x and y. x and y shall not have any side effect.
M_MAX(x, y)
Return the maximum of x and y. x and y shall not have any side effect.
M_POWEROF2_P(n)
Return true if n is a power of 2. n shall not have any side effect.
M_SWAP(type, a, b)
Swap the values of a and b. a and b are of type type. a and b shall not have any side effect.
M_ASSIGN_CAST(type, a)
Check if a can be assigned to a temporary of type type and returns this temporary.
If it cannot, the compilation failed.
M_CONST_CAST(type, a)
Check if a can be properly casted to (const type*) and returns this casted pointer if possible.
If it cannot, the compilation failed.
M_TYPE_FROM_FIELD(type, ptr, fieldType, field)
Assuming ptr is a pointer to a fieldType object that is stored within a structure of type type
at the position field, it returns a pointer to the structure.
[!NOTE] It is equivalent to the
container_ofmacro of the Linux kernel.
M_CSTR(format, ...)
Return a constant string constructed based on the printf-liked formatted string
and its arguments.
The string is constructed at run time and uses a temporary space on the stack.
If the constructed string is longer than M_USE_CSTR_ALLOC-1,
the string is truncated. Example:
strcmp( M_CSTR("Len=%d", 17) , "Len=17" ) == 0
HASH Functions
M_USE_HASH_SEED
A User modifiable macro defining the initial random seed (of type size_t).
It shall be defined before including any header of M*LIB,
so that hash functions use this variable
as their initial seed for their hash computation of an object.
It can be used to generate less predictable hash values at run-time,
which may protect against
DoS dictionary attacks.
It shall be unique for a running instance of M*LIB.
Note that using a random seed is not enough to protect efficiently against such attacks. A cryptography secure hash may be also needed. If it is not defined, the default is to use the value 0, making all hash computations predictable.
M_HASH_DECL(hash)
Declare and initialize a new hash computation, named hash that
is an integer.
M_HASH_UP(hash, value)
Update the hash variable with the given value
by incorporating the value within the hash.
value can be up to a size_t variable.
uint32_t m_core_rotl32a (uint32_t x, uint32_t n)
uint64_t m_core_rotl64a (uint64_t x, uint32_t n)
Perform a rotation of n bits of the input x.
n shall be within 1 and the number of bits of the type minus 1.
uint64_t m_core_roundpow2(uint64_t v)
Round to the next highest power of 2.
unsigned int m_core_clz32(uint32_t limb)
unsigned int m_core_clz64(uint64_t limb)
Count the number of leading zero and return it.
limb can be 0.
size_t m_core_hash (const void *str, size_t length)
Compute the hash of the binary representation of the data pointer by str
of length length. str shall have the maximum alignment restriction
of all types that size is less or equal than length.
OPERATORS Functions
M_GET_INIT oplist
M_GET_INIT_SET oplist
M_GET_INIT_MOVE oplist
M_GET_SET oplist
M_GET_MOVE oplist
M_GET_SWAP oplist
M_GET_CLEAR oplist
M_GET_NEW oplist
M_GET_DEL oplist
M_GET_REALLOC oplist
M_GET_FREE oplist
M_GET_MEMPOOL oplist
M_GET_MEMPOOL_LINKAGE oplist
M_GET_HASH oplist
M_GET_EQUAL oplist
M_GET_CMP oplist
M_GET_TYPE oplist
M_GET_SUBTYPE oplist
M_GET_OPLIST oplist
M_GET_SORT oplist
M_GET_IT_TYPE oplist
M_GET_IT_FIRST oplist
M_GET_IT_LAST oplist
M_GET_IT_END oplist
M_GET_IT_SET oplist
M_GET_IT_END_P oplist
M_GET_IT_LAST_P oplist
M_GET_IT_EQUAL_P oplist
M_GET_IT_NEXT oplist
M_GET_IT_PREVIOUS oplist
M_GET_IT_REF oplist
M_GET_IT_CREF oplist
M_GET_IT_REMOVE oplist
M_GET_IT_INSERT oplist
M_GET_ADD oplist
M_GET_SUB oplist
M_GET_MUL oplist
M_GET_DIV oplist
M_GET_RESET oplist
M_GET_PUSH oplist
M_GET_POP oplist
M_GET_REVERSE oplist
M_GET_GET_STR oplist
M_GET_OUT_STR oplist
M_GET_IN_STR oplist
M_GET_SEPARATOR oplist
M_GET_EXT_ALGO oplist
M_GET_INC_ALLOC oplist
M_GET_OOR_SET oplist
M_GET_OOR_EQUAL oplist
Return the associated method to the given operator within the given oplist.
M_BOOL_OPLIST
Oplist for C Boolean (_Bool / bool)
M_BASIC_OPLIST
Oplist for C basic types (int / float)
M_ENUM_OPLIST(type, init_value)
Oplist for a C standard enumerate of type type,
of initial value init_value.
M_CSTR_OPLIST
Oplist for the C type const char*, seen as a constant string.
(The string of characters is not copied).
M_POD_OPLIST
Oplist for a structure C type without any init and clear methods prerequisites (plain old data).
M_A1_OPLIST
Oplist for an array of size 1 of a structure C type without any init and clear
methods prerequisites.
M_EMPTY_OPLIST
Oplist for a type that shall not be instantiated. Each method does nothing.
M_CLASSIC_OPLIST(name)
Create the oplist with the operators using the pattern name, i.e.
name##_init, name##_init_set, name##_set, name##_clear, name_t
M_OPFLAT oplist
Remove the parenthesis around an oplist.
M_OPCAT(oplist1,oplist2)
Concat two oplists in one. oplist1's operators will have higher priority to oplist2
M_OPEXTEND(oplist, ...)
Extend an oplist with the given list of operators.
Theses new operators will have higher priority than the ones
in the given oplist.
##### M_TEST_METHOD_P(method, oplist)
##### M_TEST_METHOD_ALTER_P(method, oplist)
Test if a method is present in an oplist. Return 0 or 1.
M_TEST_METHOD_P does not work if the returned method is something within parenthesis (like OPLIST*)
If this case is possible, you shall use the M_TEST_METHOD_ALTER_P macro (safer but slower).
M_IF_METHOD(method, oplist)
Perform a preprocessing M_IF, if the method is present in the oplist.
Example:
M_IF_METHOD(HASH, oplist)(/*define function that uses HASH method*/, )
M_IF_METHOD_BOTH(method, oplist1, oplist2)
Perform a preprocessing M_IF if the method exists in both oplist.
Example:
M_IF_METHOD_BOTH(HASH, oplist1, oplist2) (/*define function*/, )
M_IF_METHOD_ALL(method, ...)
Perform a preprocessing M_IF if the method exists for all oplist. Example:
M_IF_METHOD_ALL(HASH, oplist1, oplist2, oplist3) (/*define function*/, )
M_GET_PROPERTY(oplist, propname)
Return the content of the property named propname as defined in the PROPERTIES field of the oplist,
or 0 if it is not defined.
M_DO_INIT_MOVE(oplist, dest, src)
M_DO_MOVE(oplist, dest, src)
Perform an INIT_MOVE/MOVE if present, or emulate it otherwise (Internal macros).
[!NOTE] Default methods for
INIT_MOVE/MOVEare not robust enough yet.
M_INIT_WITH_THROUGH_EMPLACE_TYPE(oplist, dest, src)
Use the provided EMPLACE_TYPE of the oplist to emulate an INIT_WITH operator.
It transforms the different emplace types by a C11 _Generic switch in order to call the
right initialization function in function of the type of argument.
The EMPLACE_TYPE shall use a LIST based format for listing the different emplace types.
This method is compatible with C11 or above.
This method shall be used with API_1 adapter.
M_SET_THROUGH_INIT_SET(oplist, dest, src)
Emulate the SET semantics using a combination of CLEAR and INIT_SET of the given oplist.
This method shall be used with API_1 adapter.
M_GLOBAL_OPLIST(a)
If a is a type that has registered a global oplist, it returns the registered oplist.
Otherwise, it return a. a shall be a type or an oplist.
[!NOTE] It tests the existence of the symbol
M_OPL_##a(). SeeM_OPL_to register an oplist to a type. Global registered oplists are limited totypedeftypes.
M_GLOBAL_OPLIST_OR_DEF(a)
If a is a type that has registered a global oplist, it returns the registered oplist,
otherwise it return the oplist M_BASIC_OPLIST.
The return value shall be evaluated once again to get the oplist (this is needed due to technical reasons) like this:
M_GLOBAL_OPLIST_OR_DEF(mpz_t)()
a shall be a type or an oplist.
[!NOTE] It tests the existence of the symbol
M_OPL_##a(). SeeM_OPL_ to register an oplist to a type. Global registered oplists are limited to typedef types.
Syntax enhancing
These macros are quite useful to lighten the C style and make full use of the library.
M_EACH(item, container, oplist|type)
This macro iterates over the given container of oplist oplist
(or of type type with a globally registered oplist) and sets item
to reference one different element of the container for each iteration of
the loop.
item is a created pointer variable to the contained type
of the container, only available within the for loop.
There can only have one M_EACH per line.
It shall be used after the for C keyword to perform a loop over the container.
The order of the iteration depends on the given container.
Example:
for M_EACH(item, list, LIST_OPLIST) { action; }
M_LET(var1[,var2[,...]], oplist|type)
This macro defines the variable var1(resp. var2, ...) with the oplist oplist for the next block of code.
A type can be used instead of an oplist, in which case the macro uses the oplist globally associated to this type.
Then the oplist is used to get the constructor methods and destructor method of the type.
It initializes var1 (resp. var2, ...) by calling the right initialization method
in function of the given context
and clears var1 (resp. var2, ...) by calling the clear method
when the bracket associated to the M_LET go out of scope.
If the exception model is activated, the clear method is also called if an exception is thrown in the next block of code.
The M_LET macro enables support of RAII
Its formulation is based on the expression let var1 as type in
Several forms are supported for the context of the initialization method:
- If
var1(resp.var2,...) has the form (v1,arguments...), then the variablev1will be initialized with the contains of the initializing listarguments.... - If
arguments...is a single argument within parenthesis or if there is more one argument or if the propertyLET_AS_INIT_WITHof the oplist is defined, then it uses the operatorINIT_WITH(if it exists) to emplace the variable with the given arguments (The arguments are therefore expected to be compatible with theINIT_WITHoperator). - Otherwise, it will use the operator
INIT_SET(argument is expected to be the same type as the initialized type in such case) if there is a single argument. - Otherwise, it will use the empty initializer
INIToperator.
[!IMPORTANT] An argument shall not contain any comma or it shall be put between parenthesis. In particular, if the argument is a compound literal the full compound literal shall be put between parenthesis and casted to the right type outside the parenthesis (due to the conflict with the
INIT_WITHdetection it is needed to put something outside the parenthesis like a cast).
An argument shall not have any post effect when it is evaluated as the macro may evaulate it multiple times.
There shall be at most one M_LET macro per line of source code.
You shall not call the destructor operator with the next block of code.
Examples:
M_LET(a, STRING_OPLIST) { string_set_str(a, "Hello world"); string_fputs(stdout, a); }
// a no longer exists
M_LET(a, b, c, string_t) { do something with a, b & c }
// a, b, c no longer exists
M_LET( (a, ("Hello")), string_t) { string_fputs(stdout, a); }
M_LET( (a, ("Hello")), string_t)
M_LET( (b, a), string_t){ string_fputs(stdout, b); }
[!NOTE] The user code shall not perform a return or a goto (or
longjmp) within the next block with a target outside this block. Otherwise the clear code of the object isn't called. However, you can use the break instruction to quit the block (the clear function will be executed) or throw an exception.
If a call to an exit function in the next block is performed, the clear code of the object isn't called.
You can chain the M_LET macro to create several different variables.
M_LET_IF(init_code, test_code, clear_code [, else_code] )
This macro defines the variable(s) in init_code,
executes the next block of instructions where the variable(s) is(are) used
if the initialization succeeds by testing test_code,
then it executes the clear_code.
test_code shall return a boolean indicating if the initialization
succeeds (true) or not.
If the initialization fails, it won't call the clear_code, but the else_code if it is present.
The syntax of init_code is the same as a one of a for loop.
There shall be at most one M_LET_IF macro per line of source code.
Example:
M_LET_IF(int *p = malloc(100), p!=0, free(p)) {
M_LET_IF( /* nothing */ , mtx_lock(&mut)!=thrd_error, mtx_unlock(&mut)) {
printf ("OK! Let's use p in a mutex section\n");
}
}
[!NOTE] The user code shall not perform a return or a goto (or
longjmp) outside the{}or a call to an exit function otherwise the clear_code won't be called. You can use the break instruction to quit the block (the clear_code will be executed) or you can use exception. You can chain theM_LET_IFmacro to create several different variables.
M_DEFER(clear_code[, ...])
This macro registers the execution of clear_code when reaching
the further closing brace of the next block of instruction.
clear_code shall be a valid expression.
There shall be at most one M_DEFER macro per line of source code.
Example:
m_mutex_lock(mut);
M_DEFER(m_mutex_unlock(mut)) {
// Use of the critical section.
} // Now m_mutex_unlock is called
[!NOTE] The user code shall not perform a return or a goto (or
longjmp) outside the{}or a call to an exit function otherwise the clear_code won't be called. You can use the break instruction to quit the block (the clear_code will be executed) or you can use exception.
M_CHAIN_INIT(name, init_code, clear_code)
This macro executes init_code then
registers the execution of clear_code if an exception is triggered
until the further closing brace of the next block of instruction.
init_code and clear_code shall be a valid expression.
If exception are not enabled, it simply executes init_code.
name shall a unique identifier in the current block.
It can be chained multiple times to register multiple registrations.
Therefore, it enables support for chaining initialization at the beginning of a constructor for the fields of the constructed object so that even if the constructor failed and throw an exception, the fields of the constructed object are properly cleared.
This is equivalent to C++ construct:
void type() : field1(), field2() { rest of constructor }
M_CHAIN_INIT / M_CHAIN_OBJ shall be the first instructions of the constructor function.
Example:
void struct_init_set(struct_t d, struct_t s)
{
M_CHAIN_INIT(s1, string_init_set(d->s1, s->s1), string_clear(d->s1) )
M_CHAIN_INIT(s2, string_init_set(d->s2, s->s2), string_clear(d->s2) ) {
d->num = s->num;
}
}
M_CHAIN_OBJ(name, oplist, var [, value])
This macro executes the initialization method if var to initialize it then
registers the execution of its CLEAR method if an exception is triggered
(and if the property NOCLEAR of the oplist is not defined)
until the further closing brace of the next block of instruction.
If exception are not enabled, it simply executes the initialization method.
The initialization method being used is:
INITmethod if there is no valueINIT_SETmethod if there is a value which is not between parenthesisINIT_WITHmethod if there is a value which is between parenthesis.
name shall a unique identifier in the current block.
It can be chained multiple times to register multiple registrations.
Therefore, it enables support for chaining initialization at the beginning of a constructor for the fields of the constructed object so that even if the constructor failed and throw an exception, the fields of the constructed object are properly cleared.
This is equivalent to C++ construct:
void type() : field1(), field2() { rest of constructor }
M_CHAIN_INIT / M_CHAIN_OBJ shall be the first instructions of the constructor function.
Example:
void struct_init_set(struct_t d, struct_t s)
{
M_CHAIN_OBJ(s1, STRING_OPLIST, d->s1, s->s1)
M_CHAIN_OBJ(s2, STRING_OPLIST, d->s2, s->s2)
M_CHAIN_OBJ(nu, M_BASIC_OPLIST, d->num, s->num) { }
}
Memory / Error macros
All these macro can be overridden before including the header m-core.h so that they can be adapted to a particular memory pool.
type *M_MEMORY_ALLOC (type)
Return a pointer to a new allocated non-initialized object of type type.
In case of allocation error, it returns NULL.
The default used function is the malloc function of the LIBC.
void M_MEMORY_DEL (type *ptr)
Delete the cleared object pointed by the pointer ptr
that was previously allocated by the macro M_MEMORY_ALLOC.
ptr can not be NULL.
The default used function is the free function of the LIBC.
type *M_MEMORY_REALLOC (type, ptr, number)
Return a pointer to an array of number objects of type type
ptr is either NULL (in which the array is allocated),
or a pointer returned from a previous call of M_MEMORY_REALLOC
(in which case the array is reallocated).
The objects are not initialized, nor the state of previous objects changed
(in case of reallocation).
The address of the previous objects may have moved and the MOVE operator
is not used in this case.
In case of allocation error, it returns NULL.
The default used function is the realloc function of the LIBC.
void M_MEMORY_FREE (type *ptr)
Delete the cleared object pointed by the pointer ptr.
The pointer was previously allocated by the macro M_MEMORY_REALLOC.
ptr can not be NULL.
The default used function is the free function of the LIBC.
void M_MEMORY_FULL (size_t size)
This macro is called by M*LIB when a memory error has been detected.
The parameter size is what was tried to be allocated (as a hint).
The macro can:
- Abort the execution
- Throw an exception. In this case, the state of the object is unchanged
- Set a global error variable and return
[!NOTE] The last case is not properly fully supported yet.
The default is to raise a fatal error.
void M_ASSERT_INIT(expression, object_name)
This macro is called when an assertion used in an initialization context
is called to check the good creation of an object (like a thread, a mutex)
that string name is object_name.
If the given expression is false, the execution shall be aborted.
The assertion is kept in programs built in release mode.
The default is to raise a fatal error.
M_RAISE_FATAL(message...)
This macro is called by the user code to raise a fatal error and terminate the program execution. This macro shall not return.
By default, it prints the error message on stderr and calls abort to terminate
program execution.
M_ASSERT(expression)
This macro defines the generic assert macro used by M*LIB. See the assert C macro for details.
The default is the assert macro.
M_ASSERT_SLOW(expression)
This macro defines the specialized assert macro used by M*LIB which is used on slow assertion properties (that have a significant impact on program time). See the assert C macro for details.
The default is the assert macro if M*LIB test suite, nothing otherwise.
M_ASSERT_INIT(expression)
This macro defines the specialized assert macro used by M*LIB which shall be kept on release program. See the assert C macro for details.
The default is to raise a fatal error if the expression is false.
M_ASSERT_INDEX(index, maximum)
This macro defines the specialized assert macro used by M*LIB
which is used for buffer overflow checking:
it checks if index is in the range 0 to maximum - 1.
The default is to call M_ASSERT with this property.
Generic Serialization objects
A serialization is the process of translating data structures into a format that can be stored or transmitted. When the resulting format is reread and translated, it creates a semantically identical clone of the original object.
A generic serialization object is an object that takes a C object (Boolean, integer, float, structure, union, pointer, array, list, hash-map, ...) and outputs it into a serialization way through the following defined interface that defined the format of the serialization and where it is physically output.
The M*LIB containers define the methods _out_serial and _in_serial
if the underlying types define these methods over the operators OUT_SERIAL and IN_SERIAL.
The methods for the basic C types (int, float, ...) are also defined (but only
in C11 due to technical limitation).
The methods _out_serial and _in_serial will request the generic serialization object
to serialize their current object:
- calling the interface of the generic serialization object if needed,
- performing recursive call to serialize the contained-objects.
The final output of this serialization can be a FILE* or a string.
Two kinds of serialization objects exist: one for input and one
for output. The serialization is fully recursive and can be seen as a collection of token.
The only constraint is that what is output by the output serialization object
shall be able to be parsed by the input serialization object.
The serialization input object is named as m_serial_read_t, defined in m-core.h as a structure
(of array of size 1) with the following fields:
| Field | Description |
|---|---|
m_interface | a pointer to the constant m_serial_read_interface_s structure that defines all methods that operate on this object to parse it. The instance has to be customized for the needs of the wanted serialization. |
data | a table of M_SERIAL_MAX_DATA_SIZE of C types (Boolean, integer, size or pointer). This data is used to store the needed data for the methods. |
This data is used to store the needed data for the methods.
This is pretty much like a pure virtual interface object in C++. The interface has to define the following fields with the following definition:
| Method | Description |
|---|---|
read_boolean | Read from the stream serial a boolean. Set *b with the boolean value if it succeeds. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
read_integer | Read from the stream serial an integer that can be represented with size_of_type bytes. Set *i with the integer value if it succeeds. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
read_float | Read from the stream serial a float that can be represented with size_of_type bytes. Set *r with the float value if it succeeds. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
read_string | Read from the stream serial a string. <br/>Set s with the string if it succeeds. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
read_array_start | Start reading from the stream serial an array (which is defined as a sequential collection of object). <br/>Set *num with the number of elements, or (size_t) - 1 if it is not known. Initialize the object local so that it can be used by the serialization object to serialize the array. (local is an unique local serialization object of the array). <br/>Return M_SERIAL_OK_CONTINUE if it succeeds and the parsing of the array can continue (the array is not empty), M_SERIAL_OK_DONE if it succeeds and the array ends (the array is empty), M_SERIAL_FAIL_RETRY if it doesn't support unknown number of elements, M_SERIAL_FAIL otherwise |
read_array_next | Continue reading from the stream serial an array using local to load / save data if needed. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds and the array can continue (the array end is still not reached), M_SERIAL_OK_DONE if it succeeds and the array ends, M_SERIAL_FAIL otherwise |
read_map_start | Start reading from the stream serial a map (an associative array). <br/>Set *num with the number of elements, or 0 if it is not known. Initialize local so that it can be used to serialize the map. (local is an unique serialization object of the map). <br/>Return M_SERIAL_OK_CONTINUE if it succeeds and the map continue, M_SERIAL_OK_DONE if it succeeds and the map ends (the map is empty), M_SERIAL_FAIL otherwise |
read_map_value | Continue reading from the stream serial the value separator token (if needed) using local to load / save data if needed. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds and the map continue, M_SERIAL_FAIL otherwise |
read_map_next | Continue reading from the stream serial a map. <br/>using local to load / save data if needed. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds and the map continue, M_SERIAL_OK_DONE if it succeeds and the map ends, M_SERIAL_FAIL otherwise |
read_tuple_start | Start reading a tuple from the stream serial. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds and the tuple continues, M_SERIAL_FAIL otherwise |
read_tuple_id | Continue reading a tuple (a structure) from the stream serial. <br/>using local to load / save data if needed. Set *id with the corresponding index of the table field_name[max] associated to the parsed field in the stream. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds and the tuple continues, Return M_SERIAL_OK_DONE if it succeeds and the tuple ends, M_SERIAL_FAIL otherwise |
read_variant_start | Start reading a variant (an union) from the stream serial. Set *id with the corresponding index of the table field_name[max] associated to the parsed field in the stream. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds and the variant continues, Return M_SERIAL_OK_DONE if it succeeds and the variant ends (variant is empty), M_SERIAL_FAIL otherwise |
read_variant_end | End reading a variant from the stream serial. <br/>Return M_SERIAL_OK_DONE if it succeeds and the variant ends, M_SERIAL_FAIL otherwise |
The serialization output object is named as m_serial_write_t, defined in m-core.h as a structure
(of array of size 1) with the following fields:
| Field | Description |
|---|---|
m_interface | A pointer to the constant m_serial_write_interface_s structure that defines all methods that operate on this object to output it. The instance has to be customized for the needs of the wanted serialization. |
data | A table of M_SERIAL_MAX_DATA_SIZE of C types (Boolean, integer, size or pointer). This data is used to store the needed data for the methods. |
This data is used to store the needed data for the methods.
This is pretty much like a pure virtual interface object in C++. The interface has to defines the following fields with the following definition:
| Method | Description |
|---|---|
write_boolean | Write the boolean b into the serial stream serial. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
write_integer | Write the integer data of size_of_type bytes into the serial stream serial. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
write_float | Write the float data of size_of_type bytes into the serial stream serial. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
write_string | Write the null-terminated string data of length characters into the serial stream serial. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
write_array_start | Start writing an array of number_of_elements objects into the serial stream serial. <br/>If number_of_elements is 0, then either the array has no data, or the number_of_elements of the array is unknown. <br/>Initialize local so that it can be used to serialize the array (local is an unique serialization object of the array). <br/>Return M_SERIAL_OK_CONTINUE if it succeeds, M_SERIAL_FAIL otherwise |
write_array_next | Write an array separator between elements of an array into the serial stream serial if needed. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds, M_SERIAL_FAIL otherwise |
write_array_end | End the writing of an array into the serial stream serial. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
write_map_start | Start writing a map of number_of_elements pairs of objects into the serial stream serial. <br/>If number_of_elements is 0, then either the map has no data, or the number of elements is unknown. <br/>Initialize local so that it can be used to serialize the map (local is an unique serialization object of the map). <br/>Return M_SERIAL_OK_CONTINUE if it succeeds, M_SERIAL_FAIL otherwise |
write_map_value | Write a value separator between element of the same pair of a map into the serial stream serial if needed. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds, M_SERIAL_FAIL otherwise |
write_map_next | Write a map separator between elements of a map into the serial stream serial if needed. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds, M_SERIAL_FAIL otherwise |
write_map_end | End the writing of a map into the serial stream serial. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
write_tuple_start | Start writing a tuple into the serial stream serial. <br/>Initialize local so that it can serial the tuple (local is an unique serialization object of the tuple). <br/>Return M_SERIAL_OK_CONTINUE if it succeeds, M_SERIAL_FAIL otherwise |
write_tuple_id | Start writing the field named field_name[index] of a tuple into the serial stream serial. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds, M_SERIAL_FAIL otherwise |
write_tuple_end | End the write of a tuple into the serial stream serial. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
write_variant_start | Start writing a variant into the serial stream serial. <br/>If index <= 0, the variant is empty. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise <br/>Otherwise, the field field_name[index] will be filled. <br/>Return M_SERIAL_OK_CONTINUE if it succeeds, M_SERIAL_FAIL otherwise |
write_variant_end | End Writing a variant into the serial stream serial. <br/>Return M_SERIAL_OK_DONE if it succeeds, M_SERIAL_FAIL otherwise |
M_SERIAL_MAX_DATA_SIZE can be overloaded before including any M*LIB header
to increase the size of the generic object. The maximum default size is 4 fields.
The full C definition are:
// Serial return code
typedef enum m_serial_return_code_e {
M_SERIAL_OK_DONE = 0, M_SERIAL_OK_CONTINUE = 1, M_SERIAL_FAIL = 2
} m_serial_return_code_t;
// Different types of types that can be stored in a serial object to represent it.
typedef union m_serial_ll_u {
bool b;
int i;
size_t s;
void *p;
} m_serial_ll_t;
/* Object to handle the construction of a serial write/read of an object
that needs multiple calls (array, map, ...)
It is common to all calls to the same object */
typedef struct m_serial_local_s {
m_serial_ll_t data[M_USE_SERIAL_MAX_DATA_SIZE];
} m_serial_local_t[1];
// Object to handle the generic serial read of an object.
typedef struct m_serial_read_s {
const struct m_serial_read_interface_s *m_interface;
m_serial_ll_t data[M_USE_SERIAL_MAX_DATA_SIZE];
} m_serial_read_t[1];
// Interface exported by the serial read object.
typedef struct m_serial_read_interface_s {
m_serial_return_code_t (*read_boolean)(m_serial_read_t serial,bool *b);
m_serial_return_code_t (*read_integer)(m_serial_read_t serial, long long *i, const size_t size_of_type);
m_serial_return_code_t (*read_float)(m_serial_read_t serial, long double *f, const size_t size_of_type);
m_serial_return_code_t (*read_string)(m_serial_read_t serial, struct string_s *s);
m_serial_return_code_t (*read_array_start)(m_serial_local_t local, m_serial_read_t serial, size_t *s);
m_serial_return_code_t (*read_array_next)(m_serial_local_t local, m_serial_read_t serial);
m_serial_return_code_t (*read_map_start)(m_serial_local_t local, m_serial_read_t serial, size_t *);
m_serial_return_code_t (*read_map_value)(m_serial_local_t local, m_serial_read_t serial);
m_serial_return_code_t (*read_map_next)(m_serial_local_t local, m_serial_read_t serial);
m_serial_return_code_t (*read_tuple_start)(m_serial_local_t local, m_serial_read_t serial);
m_serial_return_code_t (*read_tuple_id)(m_serial_local_t local, m_serial_read_t serial, const char *const field_name [], const int max, int *id);
m_serial_return_code_t (*read_variant_start)(m_serial_local_t local, m_serial_read_t serial, const char *const field_name[], const int max, int*id);
m_serial_return_code_t (*read_variant_end)(m_serial_local_t local, m_serial_read_t serial);
} m_serial_read_interface_t;
// Object to handle the generic serial write of an object.
typedef struct m_serial_write_s {
const struct m_serial_write_interface_s *m_interface;
m_serial_ll_t data[M_USE_SERIAL_MAX_DATA_SIZE];
} m_serial_write_t[1];
// Interface exported by the serial write object.
typedef struct m_serial_write_interface_s {
m_serial_return_code_t (*write_boolean)(m_serial_write_t serial, const bool b);
m_serial_return_code_t (*write_integer)(m_serial_write_t serial, const long long i, const size_t size_of_type);
m_serial_return_code_t (*write_float)(m_serial_write_t serial, const long double f, const size_t size_of_type);
m_serial_return_code_t (*write_string)(m_serial_write_t serial, const char s[], size_t length);
m_serial_return_code_t (*write_array_start)(m_serial_local_t local, m_serial_write_t serial, const size_t number_of_elements);
m_serial_return_code_t (*write_array_next)(m_serial_local_t local, m_serial_write_t serial);
m_serial_return_code_t (*write_array_end)(m_serial_local_t local, m_serial_write_t serial);
m_serial_return_code_t (*write_map_start)(m_serial_local_t local, m_serial_write_t serial, const size_t number_of_elements);
m_serial_return_code_t (*write_map_value)(m_serial_local_t local, m_serial_write_t serial);
m_serial_return_code_t (*write_map_next)(m_serial_local_t local, m_serial_write_t serial);
m_serial_return_code_t (*write_map_end)(m_serial_local_t local, m_serial_write_t serial);
m_serial_return_code_t (*write_tuple_start)(m_serial_local_t local, m_serial_write_t serial);
m_serial_return_code_t (*write_tuple_id)(m_serial_local_t local, m_serial_write_t serial, const char * const field_name[], const int max, const int index);
m_serial_return_code_t (*write_tuple_end)(m_serial_local_t local, m_serial_write_t serial);
m_serial_return_code_t (*write_variant_start)(m_serial_local_t local, m_serial_write_t serial, const char * const field_name[], const int max, const int index);
m_serial_return_code_t (*write_variant_end)(m_serial_local_t local, m_serial_write_t serial);
} m_serial_write_interface_t;
See m-serial-json.h for example of use.
M-THREAD
This header is for providing very thin layer around OS implementation of threads, conditional variables and mutex. It has back-ends for WIN32, POSIX thread, FreeRTOS tasks or C11 thread.
It was needed due to the low adoption rate of the C11 equivalent layer.
It uses the FreeRTOS tasks is it detects FreeRTOS.
Otherwise, it uses the C11 threads.h if possible.
If the C11 implementation does not respect the C standard
(i.e. the compiler targets C11 mode,
the __STDC_NO_THREADS__ macro is not defined
but the header threads.h is not available or not working),
then the user shall define manually the M_USE_THREAD_BACKEND
macro to select the back end to use:
- For C11
- For WINDOWS
- For PTHREAD
- For FreeRTOS
The FreeRTOS backend uses two additional global configuration constants:
M_USE_TASK_STACK_SIZEto define the stack size of a thread (default is the minimal)M_USE_TASK_PRIORITYto define the priority of a thread (default is lowest).
Example:
m_thread_t idx_p;
m_thread_t idx_c;
m_thread_create (idx_p, conso_function, NULL);
m_thread_create (idx_c, prod_function, NULL);
m_thread_join (idx_p;
m_thread_join (idx_c);
Attributes
The following attributes are available:
M_THREAD_ATTR
An attribute used for qualifying a variable to be thread specific.
It is an alias for __thread, _Thread_local or __declspec( thread )
depending on the used backend.
Methods
The following methods are available:
m_mutex_t
A type representing a mutex.
void m_mutex_init(m_mutex_t mutex)
Initialize the variable mutex and sets it to the unlocked position. If the initialization fails, the program aborts. Only one thread shall initialize the mutex.
void m_mutex_clear(m_mutex_t mutex)
Clear the variable mutex. Only one thread shall clear the mutex.
void m_mutex_lock(m_mutex_t mutex)
Lock the variable mutex for exclusive use. If the mutex is not unlocked, it will wait indefinitely until it is.
bool m_mutex_trylock(m_mutex_t mutex)
Try to lock the variable mutex for exclusive use. If the mutex is not unlocked, it will return immediately. Return true in case of success (mutex locked), false otherwise (mutex unlocked).
void m_mutex_unlock(m_mutex_t mutex)
Unlock the variable mutex for exclusive use. The mutex shall be locked.
m_cond_t
A type representing a conditional variable, which shall be used within a mutex section.
void m_cond_init(m_cond_t cond)
Initialize the conditional variable cond. If the initialization failed, the program aborts. Only one thread shall init the conditional variable.
void m_cond_clear(m_cond_t cond)
Clear the variable cond. If the variable is not initialized, the behavior is undefined. Only one thread shall clear the conditional variable.
void m_cond_signal(m_cond_t cond)
Signal that the event associated to the variable cond has occurred to at least a single thread. All usage of this conditional variable shall be done within the same mutex exclusive section.
void m_cond_broadcast(m_cond_t cond)
Signal that the event associated to the variable cond has occurred to all waiting threads. All usage of this conditional variable shall be done within the same mutex exclusive section.
void m_cond_wait(m_cond_t cond, m_mutex_t mutex)
Wait indefinitely for the event associated to the variable cond to occur. IF multiple threads wait for the same event, which thread to awoken is not specified. All usage of this conditional variable shall be done within the mutex exclusive section.
m_thread_t
A type representing an id of a thread.
void m_thread_create(m_thread_t thread, void (*function)(void*), void *argument)
Create a new thread and set the it of the thread to thread.
The new thread run the code function(argument) with
argument a void* and function taking a void* and returning
nothing.
If the initialization fails, the program aborts.
void m_thread_join(m_thread_t thread)
Wait indefinitely for the thread thread to exit.
m_once_t
A type representing a helper structure for m_once_call.
An object of type m_once_t shall be initialized at declaration level with M_ONCE_INIT_VALUE
M_ONCE_INIT_VALUE
Initial value to set an object of type m_once_t when declaring it.
void m_once_call(m_once_t obj, void (*func)(void))
Executes the function pointer func exactly once, even if called concurrently, from several threads, provided that they share the same object obj.
M-WORKER
This header is for providing a pool of workers. Each worker run in a separate thread and can handle work orders sent by the main threads. A work order is a computation task. Work orders are organized around synchronization points. Workers can be disabled globally to ease debugging.
This implements parallelism just like OpenMP or CILK++.
Example:
worker_t worker;
worker_init(worker, 0, 0, NULL);
worker_sync_t sync;
worker_start(sync, worker);
void *data = ...;
worker_spawn (sync, taskFunc, data);
taskFunc(otherData);
worker_sync(sync);
Currently, there is no support for:
- Throw exceptions by the worker tasks,
- Unbalanced design: the worker tasks shall not lock a mutex without closing it (same for other synchronization structures).
Thread Local Storage variables have to be reinitialized properly with the reset function. This may result in subtle difference between the serial code and the parallel code.
Methods
The following methods are available:
worker_t
A pool of worker.
The type is incompatible between C++, C/CLANG and C (all others) due to technical constraints, so a variable of such a type shall always be accessed by the same compiler.
worker_sync_t
A synchronization point between workers.
void worker_init(worker_t worker[, unsigned int numWorker, unsigned int extraQueue, void (*resetFunc)(void), void (*clearFunc)(void) ])
Initialize the pool of workers worker with numWorker workers.
if numWorker is 0, then it will detect how many core is available on the
system and creates as much workers as there are cores.
Before starting any work, the function resetFunc
is called by the worker to reset its state (or call nothing if the function
pointer is NULL).
extraQueue is the number of tasks that can be accepted by the work order
queue in case if there is no worker available.
Before terminating, each worker will call clearFunc if the function is not NULL.
Default values are respectively 0 and NULL.
void worker_clear(worker_t worker)
Request termination to the pool of workers, and wait for them to terminate. It is undefined if there is any work order in progress.
void worker_start(worker_block_t syncBlock, worker_t worker)
Start a new synchronization block for a pool of work orders
linked to the pool of worker worker.
void worker_spawn(worker_block_t syncBlock, void (*func)(void *data), void *data)
Register the work order func(data) to the synchronization point syncBlock.
If no worker is available (and no extraQueue), the work order func(data) will be handled
by the caller. Otherwise, the work order func(data) will be handled
by an asynchronous worker and the function immediately returns.
The object(s) referenced by data shall remain available (not destructed) until the
control flow reaches the next synchronization point (worker_sync),
as these object(s) may be delayed read by other threads until this point.
bool worker_sync_p(worker_block_t syncBlock)
Test if all work orders registered to this synchronization point are terminated (true) or not (false).
void worker_sync(worker_block_t syncBlock)
Wait for all work orders registered to this synchronization point syncBlock
to be terminated.
size_t worker_count(worker_t worker)
Return the number of workers of the pool.
void worker_flush(worker_t worker)
Flush any work order in the queue by the current thread until none remains.
WORKER_SPAWN(syncBlock, input, core, output)
Request the work order core to the synchronization point syncBlock.
If no worker is available (and no extra queue), the work order core will be handled
by the caller. Otherwise, the work order core will be handled
by an asynchronous worker.
core is any C code that doesn't break the control flow (you
cannot use return / goto / break to go outside the flow).
input is the list of local input variables of the core block within ( ).
output is the list of local output variables of the core block within ( ).
These lists shall be exhaustive to capture all needed variables.
This macro needs either GCC (for nested function) or CLANG (for blocks) or a C++11 compiler (for lambda and functional) to work.
The next synchronization point (worker_sync) shall be present in the control flow of the current C block.
[!NOTE] Even if nested functions are used for GCC, it doesn't generate a trampoline and the stack doesn't need to be executable as all variables are captured by the library.
[!TIP] For CLANG, you need to add
-fblockstoCFLAGSand-lBlocksRuntimeto LIB (See CLANG manual).
[!NOTE] It will generate warnings about shadowed variables. There is no way to avoid this.
[!IMPORTANT] arrays and not trivially movable object are not supported as input / output variables due to current technical limitations.
M_WORKER_SPAWN_DEF2(name, (name1, type1, oplist1), ...)
Define a specialization of worker_spawn, called m_worker_spawn ## name,
that takes as input a function with the given name and arguments,
avoiding casting the data to void*.
The specialized method shall have the following prototype:
void function(type1 name1, type2 name2, ...);
m_worker_spawn ## name has the following prototypes.
void m_worker_spawn ## name(m_worker_sync_t block,
void (*callback)(type1 name1, type2 name2, ...), type1 name1, type2 name2, ...);
The arguments are properly copied and cleared using their oplists if the work-order is enqueued for a worker.
M-ATOMIC
This header goal is to provide the C header stdatomic.h
to any C compiler (C11 or C99 compliant) or C++ compiler.
If available, it uses the C11 header stdatomic.h,
otherwise if the compiler is a C++ compiler,
it uses the header atomic.h and imports all definition
into the global name space (this is needed because the
C++ standard doesn't support officially the stdatomic.h header,
resulting in broken compilation when building C code with
a C++ compiler).
Otherwise, it provides a non-thin emulation of atomic using mutex. This emulation has a known theoretical limitation: the mutex are never cleared. There is nothing to do to fix this. In practice, it is not a problem.
M-ALGO
This header is for generating generic algorithm to containers.
ALGO_DEF(name, container_oplist)
Define the available algorithms for the container which oplist is container_oplist.
The defined algorithms depend on the availability of the methods of the containers
(For example, if there is no CMP operator, there is no MIN method defined).
Example:
ARRAY_DEF(array_int, int)
ALGO_DEF(array_int, ARRAY_OPLIST(array_int))
void f(void) {
array_int_t l;
array_int_init(l);
for(int i = 0; i < 100; i++)
array_int_push_back (l, i);
array_int_push_back (l, 17);
assert( array_int_contains(l, 62) == true);
assert( array_int_contains(l, -1) == false);
assert( array_int_count(l, 17) == 2);
array_int_clear(l);
}
Created methods
The following methods are automatically and properly created by the previous macros. In the following methods, name stands for the name given to the macro that is used to identify the type.
In the following descriptions, it_t is an iterator of the container
container_t is the type of the container and type_t is the type
of object contained in the container.
void name_find(it_t it, const container_t c, const type_t data)
Search for the first occurrence of data within the container.
Update the iterator with the found position or return the end iterator.
The search is linear.
void name_find_again(it_t it, const type_t data)
Search from the position it for the next occurrence of data within the container.
Update the iterator with the found position or return end iterator.
The search is linear.
void name_find_if(it_t it, const container_t c, bool (*pred)(type_t const))
Search for the first occurrence within the container than matches
the predicate pred
Update the iterator with the found position or return end iterator.
The search is linear.
void name_find_again_if(it_t it, bool (*pred)(type_t const))
Search from the position it for the next occurrence matching the predicate
pred within the container.
Update the iterator with the found position or return end iterator.
The search is linear.
void name_find_last(it_t it, const container_t c, const type_t data)
Search for the last occurrence of data within the container.
Update the iterator with the found position or return end iterator.
The search is linear and can be backward or forwards depending
on the possibility of the container.
bool name_contains(const container_t c, const type_t data)
Return true if data is within the container, false otherwise.
The search is linear.
size_t name_count(const container_t c, const type_t data)
Return the number of occurrence of data within the container.
The search is linear.
size_t name_count_if(const container_t c, bool (*pred)(type_t const data))
Return the number of occurrence matching the predicate pred within the container.
The search is linear.
void name_mismatch(it_t it1, it_t it2, const container_t c1, const container_t c2)
Returns the first mismatching pair of elements of the two containers c1 and c2.
void name_mismatch_again(it_t it1, it_t it2)
Returns the next mismatching pair of elements of the two containers
from the position it1 of container c1 and
from the position it2 of container c2.
void name_mismatch_if(it_t it1, it_t it2, const container_t c1, const container_t c2, bool (*cmp)(type_t const, type_t const))
Returns the first mismatching pair of elements of the two containers using
the provided comparison cmp.
void name_mismatch_again_if(it_t it1, it_t it2, bool (*cmp)(type_t const, type_t const))
Returns the next mismatching pair of elements of the two containers using
the provided comparison cmp
from the position it1 and
from the position it2.
void name_fill(container_t c, type_t value)
Set all elements of the container c to value.
void name_fill_n(container_t c, size_t n, type_t value)
Set the container to n elements equal to value.
This method is defined only if the container exports a PUSH method.
void name_fill_a(container_t c, type_t value, type_t inc)
Set all elements of the container c to value + i * inc
with i = 0.. size(c)
This method is defined only if the base type exports an ADD method.
This method is defined only if the container exports a PUSH method.
void name_fill_an(container_t c, size_t n, type_t value)
Set the container to n elements to value + i * inc
with i = 0..n
This method is defined only if the base type exports an ADD method.
This method is defined only if the container exports a PUSH method.
void name_for_each(container_t c, void (*func)(type_t))
Apply the function func to each element of the container c.
The function may transform the element provided it doesn't reallocate the
object and if the container supports iterating over modifiable elements.
void name_transform(container_t d, container_t c, void (*func)(type_t *out, const type_t in))
Apply the function func to each element of the container c
and push the result into the container d so that d = func(c)
func shall output in the initialized object out
the transformed value of the constant object in.
Afterwards out is pushed moved into d.
This method is defined only if the base type exports an INIT method.
This method is defined only if the container exports a PUSH_MOVE method.
c and d cannot be the same containers.
void name_reduce(type_t *dest, const container_t c, void (*func)(type_t *, type_t const))
Perform a reduction using the function func to the elements of the container c.
The final result is stored in *dest.
If there is no element, *dest is let unmodified.
void name_map_reduce(type_t *dest, const container_t c, void (*redFunc)(type_t *, type_t const), void *(mapFunc)(type_t *, type_t const))
Perform a reduction using the function redFunc
to the transformed elements of the container c using mapFunc.
The final result is stored in *dest.
If there is no element, *dest is let unmodified.
bool name_any_of_p(const container_t c, void *(func)(const type_t))
Test if any element of the container c matches the predicate func.
bool name_all_of_p(const container_t c, void *(func)(const type_t))
Test if all elements of the container c match the predicate func.
bool name_none_of_p(const container_t c, void *(func)(const type_t))
Test if no element of the container c match the predicate func.
type_t *name_min(const container_t c)
Return a reference to the minimum element of the container c.
Return NULL if there is no element.
This method is available if the CMP operator has been defined.
type_t *name_max(const container_t c)
Return a reference to the maximum element of the container c.
Return NULL if there is no element.
This method is available if the CMP operator has been defined.
void name_minmax(type_t **min, type_t **max, const container_t c)
Stores in *min a reference to the minimum element of the container c.
Stores in *max a reference to the minimum element of the container c.
Stores NULL if there is no element.
This method is available if the CMP operator has been defined.
void name_uniq(container_t c)
Assuming the container c has been sorted,
remove any duplicate elements of the container.
This method is available if the CMP and IT_REMOVE operators have been defined.
void name_remove_val(container_t c, type_t val)
Remove all elements equal to val of the container.
This method is available if the CMP and IT_REMOVE operators have been defined.
void name_remove_if(container_t c, bool (*func)(type_t) )
Remove all elements matching the given condition (function func() returns true) of the container.
This method is available if the CMP and IT_REMOVE operators have been defined.
void name_add(container_t dest, const container_t value)
For each element of the container dest,
add the corresponding element of the container dest
up to the minimum size of the containers.
This method is available if the ADD operator has been defined.
void name_sub(container_t dest, const container_t value)
For each element of the container dest,
sub the corresponding element of the container dest
up to the minimum size of the containers.
This method is available if the SUB operator has been defined.
void name_mul(container_t dest, const container_t value)
For each element of the container dest,
mul the corresponding element of the container dest
up to the minimum size of the containers.
This method is available if the MUL operator has been defined.
void name_div(container_t dest, const container_t value)
For each element of the container dest,
div the corresponding element of the container dest
up to the minimum size of the containers.
This method is available if the DIV operator has been defined.
bool void name_sort_p(const container_t c)
Test if the container c is sorted (true) or not (false).
This method is available if the CMP operator has been defined.
bool name_sort_dsc_p(const container_t c)
Test if the container c is reverse sorted (=true) or not (=false)
This method is available if the CMP operator has been defined.
void void name_sort(container_t c)
Sort the container c.
This method is available if the CMP operator has been defined.
The used algorithm depends on the available operators:
if a specialized SORT operator is defined for the container, it is used.
if SPLICE_BACK and SPLICE_AT operates are defined, a merge sort is defined,
if IT_PREVIOUS is defined, an insertion sort is used,
otherwise a selection sort is used.
bool name_sort_dsc(const container_t c)
Reverse sort the container c.
This method is available if the CMP operator has been defined.
The used algorithm depends on the available operators:
if a specialized SORT operator is defined, it is used.
if SPLICE_BACK and SPLICE_AT operates are defined, a merge sort is defined,
if IT_PREVIOUS is defined, an insertion sort is used,
otherwise a selection sort is used.
void name_sort_union(container_t c1, const container_t c2)
Assuming both containers c1 and c2 are sorted,
perform an union of the containers in c1.
This method is available if the IT_INSERT operator is defined.
void name_sort_dsc_union(container_t c1, const container_t c2)
Assuming both containers c1 and c2 are reverse sorted,
perform an union of the containers in c2.
This method is available if the IT_INSERT operator is defined.
void name_sort_intersect(container_t c1, const container_t c2)
Assuming both containers c1 and c2 are sorted,
perform an intersection of the containers in c1.
This method is available if the IT_REMOVE operator is defined.
void name_sort_dsc_intersect(container_t c, const container_t c)
Assuming both containers c1 and c2 are reverse sorted,
perform an intersection of the containers in c1.
This method is available if the IT_REMOVE operator is defined.
void name_split(container_t c, const string_t str, const char sp)
Split the string str around the character separator sp
into a set of string in the container c.
This method is defined if the base type of the container is a string_t type,
void name_join(string_t dst, container_t c, const string_t str)
Join the string str and all the strings of the container c into dst.
This method is defined if the base type of the container is a string_t type,
ALGO_FOR_EACH(container, oplist, func[, arguments..])
Apply the function func to each element of the container container of oplist oplist:
for each item in container do
func([arguments,] item)
The function func is a method that takes as argument an object of the
container and returns nothing. It may update the object provided it
doesn't reallocate it.
ALGO_TRANSFORM(contDst, contDstOplist, contSrc, contSrcOplist, func[, arguments..])
Apply the function func to each element of the container contSrc of oplist contSrcOplist
and store its output in the container contDst of oplist contDstOplist
so that contDst = func(contSrc). Exact algorithm is:
clean(contDst)
for each item in do
init(tmp)
func(tmp, item, [, arguments])
push_move(contDst, tmp)
The function func is a method that takes as first argument the object to put in the new container, and as second argument the object in the source container.
ALGO_EXTRACT(containerDest, oplistDest, containerSrc, oplistSrc[, func[, arguments..]])
Extract the items of the container containerSrc of oplist oplistSrc
into the containerDest of oplist oplistDest:
RESET (containerDest)
for each item in containerSrc do
[ if func([arguments,] item) ]
Push item in containerDest
The optional function func is a predicate that takes as argument an object of the
container and returns a boolean that is true if the object has to be added
to the other container.
Both containers shall either provide PUSH method, or SET_KEY method.
ALGO_REDUCE(dest, container, oplist, reduceFunc[, mapFunc[, arguments..])
Reduce the items of the container container of oplist oplist
into a single element by applying the reduce function:
dest = reduceFunc(mapFunc(item[0]),
reduceFunc(..., reduceFunc(mapFunc(item[N-2]),
mapFunc(item[N-1]))))
mapFunc is a method which prototype is:
void mapFunc(dest, item)
with both dest & item that are of the same type as the one of
the container. It transforms the item into another form that is suitable
for the reduceFunc.
If mapFunc is not specified, identity will be used instead.
reduceFunc is a method which prototype is:
void reduceFunc(dest, item)
It integrates the new item into the partial sum and dest.
The reduce function can be the special keywords add, sum, and, or
product, mul in which case the special function performing a sum / sum / and / or / mul operation will be used.
dest can be either the variable (in which case dest is assumed to be of type equivalent to the elements of the container) or a tuple (var, oplist) with var being the variable name and oplist its oplist (with TYPE, INIT, SET methods). The tuple may be needed if the map function transform a type into another.
ALGO_INSERT_AT(containerDst, containerDstOPLIST, position, containerSrc, containerSrcOPLIST)
Insert into the container contDst at position position all the values
of container contSrc.
M-FUNCOBJ
This header is for generating Function Object. A function object is a construct an object to be invoked or called as if it were an ordinary function, usually with the same syntax (a function parameter that can also be a function) but with additional "within" parameters.
Example:
// Define generic interface of a function int --> int
FUNC_OBJ_ITF_DEF(interface, int, int)
// Define one instance of such interface
FUNC_OBJ_INS_DEF(sumint, interface, x, {
return self->sum + x;
}, (sum, int) )
int f(interface_t i)
{
return interface_call(i, 4);
}
int h(void)
{
sumint_t s;
sumint_init_with(s, 16);
interface_t interface = sumint_as_interface(s);
int n = f(interface);
printf("sum=%d\n", n);
sumint_clear(s);
}
FUNC_OBJ_ITF_DEF(name, retcode_type[, type_of_param1, type_of_param 2, ...])
FUNC_OBJ_ITF_DEF_AS(name, name_t, retcode_type[, type_of_param1, type_of_param 2, ...])
Define a function object interface of name name
emulating a function pointer returning retcode_type (which can be void),
and with as inputs the list of types of paramN, thus generating a function
prototype like this:
retcode_type function(type_of_param1, type_of_param 2, ...)
An interface cannot be used without an instance (see below) that implements this interface. In particular, there is no init nor clear function for an interface (only an instance provides such initialization).
FUNC_OBJ_ITF_DEF_AS is the same as FUNC_OBJ_ITF_DEF except the name of the type name_t is provided.
It will define the following type and functions:
name_t
Type representing an interface to such function object. There is only one method for such type (see below). It is a pointer to an hidden structure and can be assigned.
retcode_type name_call(name_t interface, type_of_param1, type_of_param 2, ...)
The call function of the interface object. It will call the particular implemented callback of the instance of this interface. It shall only be used by an interface object derived from an instance.
FUNC_OBJ_INS_DEF(name, interface_name, (param_name_1, ...), { callback_core }, (self_member1, self_type1[, self_oplist1]), ...)
FUNC_OBJ_INS_DEF_AS(name, name_t, interface_name, (param_name_1, ...), { callback_core }, (self_member1, self_type1[, self_oplist1]), ...)
Define a function object instance of name name
implementing the interface interface_name (it is the same as
used as name in FUNC_OBJ_ITF_DEF).
The function instance is defined as per:
- the function prototype of the inherited interface,
- the parameters of the function are named as per the list
param_name_list, - the core of the function shall be defined in the brackets
within the callback_core. The members of the function object can be
accessed through the pointer named
selfto access the member attributes of the object (without any cast), and the parameter names of the function shall be accessed as per their names in theparam_name_list. - optional member attributes of the function object can be defined
after the core (just like for tuple and variant):
Each parameter is defined as a triplet: (
name,type[, oplist])
It generates a function that looks like:
interface_name_retcode_type function(interface_name_t *self, interface_name_type_of_param1 param_name_1, interface_name_type_of_param 2 param_name_2, ...) {
callback_core
}
FUNC_OBJ_INS_DEF_AS is the same as FUNC_OBJ_INS_DEF except the name of the type name_t is provided.
name_t
Name of a particular instance to the interface of the Function Object interface_name.
void name_init(name_t self)
Initialize the instance of the function with default value.
This method is defined only if all member attributes export an INIT method.
If there is no member, the method is defined.
void name_init_with(name_t self, self_type1 a1, self_type2 a2, ...)
Initialize the instance of the function with the given values of the member attributes.
void name_clear(name_t self)
Clear the instance of the function.
interface_name_t name_as_interface(name_t self)
Return the interface object derived from this instance. This object can then be transmitted to any function that accept the generic interface (mainly _call).
M-TRY
This header is for exception handling.
It provides basic functionality for throwing exception and catching then.
The setjmp and longjmp standard library functions (or some variants) are used to implement the try / catch / throw macro keywords.
It doesn't support the finally keyword.
When building with a C++ compiler, theses macro keywords simply use the original C++ keyword in a way to match the specification below.
The whole program shall be compiled with the same exact compiler and the same target architecture.
Only one type of data is supported as exception. This is done to simplify the design and to avoid using exception as a general purpose error mechanism. It should only be used for rare case of errors which cannot be dealt locally in the program being executed (so called abnormal error).
In order to support Resource Acquisition Is Initialization
technique which frees resources using destructor,
M*LIB ensures that the destructors of all variables created using the keyword M_LET are properly called on throwing exception.
For this, different mechanisms are used to mark the objects and the CLEAR operator to be called on abnormal exceptions.
This is done by injecting different information in the stack to be able to handle then.
Therefore, contrary to C++, using exceptions in C will add a penalty performance to the program being executed in its nominal behavior.
The exact cost depends on the mechanism used for RAII support.
For GCC, it will use nested functions. For CLANG, it will use blocks (if compiled in blocks mode).
Otherwise, it uses a standard compliant way, which is the slowest.
The variable which are not initialized through the macro M_LET don't have their CLEAR method called on exceptions.
A typical program will look like:
M_TRY(exception) {
M_LET(x, string_t) {
// ... do operation on x
// Throw a memory error of 1024 bytes.
M_THROW(M_ERROR_MEMORY, 1024);
}
} M_CATCH(exception, M_ERROR_MEMORY) {
printf("There is no enough memory to allocate %zu bytes.\n", (size_t) exception->data[0]);
}
In this example, the destructor of x will be called before catching the exception and resuming the program execution in the M_CATCH block.
You shall include this header before any other headers of M*LIB, so that
it can configure the memory management of M*LIB to throw exception on memory errors.
It does it by redefining the default macro M_MEMORY_FULL accordingly.
When using CLANG, you should add the following options to your compiler flags, otherwise it will compile in degraded mode:
-fblocks -lBlocksRuntime
When writing your own constructor, you should consider M_CHAIN_INIT
to support partially constructed object if there are more than two source of throwing in your object (any memory allocation is a source of throwing).
struct m_exception_s
This is the exception type. It is composed of the following fields:
error_code— The error code. It is used to identify the error that are raised the exception.line— The line number where the error was detected.filename— The filename (CSTR) where the error was detected.num— Number of entries incontexttablecontext— an array ofM_USE_MAX_CONTEXTelements.
You can access the fields of the type directly.
M_TRY(name)
Create a try block which name is name that will catch thrown exception (if any)
and forward then to the associated catch block of the same name.
The try block will start just after the keyword, with a brace character.
If no catch block matches the error code raised, it will forward the error to the upper level try block.
Until there is no longer any try block. In which case, it will terminate the program.
M_CATCH(name, error_code)
Create a catch block associated to the try block named name.
The catch block will start just after the keyword, with a brace character.
This catch block will be executed on throwing an exception with an error code matching error_code.
If error_code is 0, it will catch all exceptions.
Within the catch block, a pointer to the exception object of type m_exception_s is available through the name variable.
M_THROW(error_code[, ...])
Throw the exception associated to the error_code.
error_code shall be a positive integer constant.
Additional arguments are used to fill in the error field of m_exception_s
that is used to identify the cause of the exception.
The line and filename fields of the exception are filled automatically by the macro.
M-MEMPOOL
This header is for generating specialized and optimized memory pools:
it will generate specialized functions to allocate and free only one kind of an object.
The mempool functions are not specially thread safe for a given mempool,
but the mempool variable can have the attribute M_THREAD_ATTR
so that each thread has its own instance of the mempool.
The memory pool has to be initialized and cleared like any other variable. Clearing the memory pool will free all the memory that has been allocated within this memory pool.
MEMPOOL_DEF(name, type)
Generate specialized functions & types prefixed by name to alloc and free an object of type type.
Example:
MEMPOOL_DEF(mempool_uint, unsigned int)
mempool_uint_t m;
void f(void) {
mempool_uint_init(m);
unsigned int *p = mempool_uint_alloc(m);
*p = 17;
mempool_uint_free(m, p);
mempool_uint_clear(m);
}
Created methods
The following methods are automatically and properly created by the previous macros. In the following methods, name stands for the name given to the macro that is used to identify the type.
name_t
The type of a mempool.
void name_init(name_t m)
Initialize the mempool m.
void name_clear(name_t m)
Clear the mempool m.
All allocated objects associated to the this mempool that weren't explicitly freed will be deleted too (without calling their clear method).
type *name_alloc(name_t m)
Create a new object of type type and return a new pointer to the uninitialized object.
void name_free(name_t m, type *p)
Free the object p created by the call to name_alloc.
The clear method of the type is not called.
M-SERIAL-JSON
This header is for defining an instance of the serial interface
supporting import (and export) of a container
from (to) to a file in JSON format.
It uses the generic serialization ability of M*LIB for this purpose,
providing a specialization of the serialization for JSON over FILE*.
Another way of seeing it is that you define your data structure using M*LIB containers (building it using basic types, strings, tuples, variants, array, dictionaries, ...) and then you can import / export your data structure for free in JSON format.
If the JSON file cannot be translated into the data structure, a failure
error is reported (M_SERIAL_FAIL). For example, if some new fields are present
in the JSON file but not in the data structure.
On contrary, if some fields are missing (or in a different order) in the JSON
file, the parsing will still succeed (object fields are unmodified
except for new sub-objects, for which default value are used).
It is fully working with C11 compilers only.
The current locale of the program shall be compatible with the JSON format,
specially the fraction separator character shall be . in the current
locale to respect the JSON format.
C functions on FILE
m_serial_json_write_t
A synonym of m_serial_write_t with a global oplist registered
for use with JSON over FILE*.
void m_serial_json_write_init(m_serial_write_t serial, FILE *f)
Initialize the serial object to be able to output in JSON format to the file f.
The file f shall remain open in wt mode while the serial is not cleared.
void m_serial_json_write_clear(m_serial_write_t serial)
Clear the serialization object serial.
m_serial_json_read_t
A synonym of m_serial_read_t with a global oplist registered
for use with JSON over FILE*.
void m_serial_json_read_init(m_serial_read_t serial, FILE *f)
Initialize the serial object to be able to parse in JSON format from the file f.
The file f shall remain open in rt mode while the serial is not cleared.
void m_serial_json_read_clear(m_serial_read_t serial)
Clear the serialization object serial.
C functions on string
m_serial_str_json_write_t
A synonym of m_serial_write_t with a global oplist registered
for use with JSON over string_t.
void m_serial_str_json_write_init(m_serial_write_t serial, string_t str)
Initialize the serial object to be able to output in JSON format to the string_t str.
The string str shall remain initialized while the serial object is not cleared.
void m_serial_str_json_write_clear(m_serial_write_t serial)
Clear the serialization object serial.
m_serial_str_json_read_t
A synonym of m_serial_read_t with a global oplist registered
for use with JSON over const string (const char*).
void m_serial_str_json_read_init(m_serial_read_t serial, const char str[])
Initialize the serial object to be able to parse in JSON format from the const string str.
The const string str shall remain initialized while the serial object is not cleared.
const char * m_serial_str_json_read_clear(m_serial_read_t serial)
Clear the serialization object serial and return a pointer to the first
unparsed character in the const string.
Example:
// Define a structure of two fields.
TUPLE_DEF2(my,
(value, int),
(name, string_t)
)
#define M_OPL_my_t() TUPLE_OPLIST(my, M_BASIC_OPLIST, STRING_OPLIST)
// Output in JSON file the structure my_t
void output(my_t el1)
{
m_serial_write_t out;
m_serial_return_code_t ret;
FILE *f = fopen ("data.json", "wt");
if (!f) abort();
m_serial_json_write_init(out, f);
ret = my2_out_serial(out, el1);
assert (ret == M_SERIAL_OK_DONE);
m_serial_json_write_clear(out);
fclose(f);
}
// Get from JSON file the structure my_t
void input(my_t el1)
{
m_serial_read_t in;
m_serial_return_code_t ret;
f = fopen ("data.json", "rt");
if (!f) abort();
m_serial_json_read_init(in, f);
ret = my2_in_serial(el2, in);
assert (ret == M_SERIAL_OK_DONE);
m_serial_json_read_clear(in);
fclose(f);
}
M-SERIAL-BIN
This header is for defining an instance of the serial interface supporting import (and export) of a container from (to) to a file in an ad-hoc binary format. This format only supports the current system and cannot be used to communicate across multiple systems (endianness, size of types are typically not abstracted by this format).
It uses the generic serialization ability of M*LIB for this purpose,
providing a specialization of the serialization for JSON over FILE*.
It is fully working with C11 compilers only.
C functions
void m_serial_bin_write_init(m_serial_write_t serial, FILE *f)
Initialize the serial object to be able to output in BIN format to the file f.
The file f has to remained open in 'wb' mode while the serial is not cleared
otherwise the behavior of the object is undefined.
void m_serial_bin_write_clear(m_serial_write_t serial)
Clear the serialization object serial.
void m_serial_bin_read_init(m_serial_read_t serial, FILE *f)
Initialize the serial object to be able to parse in BIN format from the file f.
The file f has to remained open in rb mode while the serial is not cleared
otherwise the behavior of the object is undefined.
void m_serial_bin_read_clear(m_serial_read_t serial)
Clear the serialization object serial.
M-GENERIC
This header is for registering and using a generic interface, regardless of the real type.
More precisely it provides way of registering the oplist of a type. Then a variable of this type can be used in macro-like functions (init, clear, push, ...) and the associated method of this oplist will be used to handle the variable.
If no type is associated to this variable, an error is reported by the compiler.
This header needs a C23 compliant compiler or a C11 compiler providing the typeof extension (like GCC, CLANG, MSVC).
[!NOTE] TCC is not supported yet due to some bugs in the compiler.
This provides the same level of flexibility of the C++. However, there is some drawbacks of using this generic interface:
- Error messages can be more complex,
- Compilation time increase a lot (on pair with C++)
This header is still a WIP and is currently more a demo (Not ready for production).
Example
A concrete example of the generic header is the following. It reuses the basic example of the introduction of the library.
#include "m-list.h"
#include "m-generic.h"
LIST_DEF(list_uint, unsigned int)
// Register oplist for M_LET & M_EACH :
#define M_OPL_list_uint_t() LIST_OPLIST(list_uint, M_BASIC_OPLIST)
// Register for Generic (Organization, Component & Oplist)
#define M_GENERIC_ORG_1() (USER)
#define M_GENERIC_ORG_USER_COMP_1() (CORE)
#define M_GENERIC_ORG_USER_COMP_CORE_OPLIST_1() M_OPL_list_uint_t()
int main(void)
{
M_LET(list, list_uint_t) {
push(list, 42);
push(list, 17);
for each(item, list) {
M_PRINT("ITEM=", *item, "\n");
}
M_PRINT("List = ", list, "\n");
}
}
Registration
To register an oplist you need to register three things:
- the integration user (user responsible for the integration of the whole program) registers all the organizations by mapping an integer from 1 to 50 to the short name of the organization.
- the organization user (user responsible for the integration produced by an organization, typically a library or the program without its libraries) chooses the short name of the organization and registers all the components of this organization by mapping an integer from 1 to 50 to the short name of the component.
- the component user (user responsible for a component of a library or a program) registers all the oplists of this component by mapping an integer from 1 to 50 to the oplist.
This 3 levels registration is used to enable support for complex integration in real project. So, it maps the basic structure of a program so that each independent layer can register its own oplists independently of the others, and only the final integrator maps everything together.
To register an organization the integration user shall define a macro like this for all organizations:
#define M_GENERIC_ORG_<A_NUM>() (<ORGA_NAME>)
with
<A_NUM>replaced by a unique integer in the range 1 to 50<ORGA_NAME>replaced by the short name of the organization.
To register a component the organization user shall define a macro like this for all components:
#define M_GENERIC_ORG_<ORGA_NAME>_COMP_<A_NUM>() (<COMP_NAME>)
with
<A_NUM>replaced by a unique integer in the range 1 to 50<ORGA_NAME>replaced by the short name of the organization.<COMP_NAME>replaced by the short name of the component.
To register an oplist the component user shall define a macro like this for all oplists:
#define M_GENERIC_ORG_<ORGA_NAME>_COMP_<COMP_NAME>_OPLIST_<A_NUM>() \
<OP_LIST>
with
<A_NUM>replaced by a unique integer in the range 1 to 50<ORGA_NAME>replaced by the short name of the organization.<COMP_NAME>replaced by the short name of the component.<OP_LIST>replaced by the oplist (no need for extra parenthesis).
These macros should be defined in the header associated to their responsibility. To register something, you don't need to include the m-register header file.
Usage
The following macro functions are defined. They have the same behavior as their corresponding OPERATOR of the oplists:
init(x);
init_set(x, y);
init_move(x, y);
move(x, y);
set(x, y);
clear(x);
swap(x, y);
hash(x);
equal(x, y);
cmp(x, y);
sort(x);
splice_back(d, s, i);
splice_at(d, id, s, is);
it_first(x, y);
it_last(x, y);
it_end(x, y);
it_set(d, s);
it_end_p(i);
it_last_p(i);
it_next(i);
it_previous(i);
it_ref(i);
it_cref(i);
it_equal(x, y);
it_insert(c, i, o);
it_remove(c, i);
empty_p(x);
add(x, y);
sub(x, y);
mul(x, y);
div(x, y);
reset(x);
get(x, y);
set_at(x, y, z);
safe_get(x, y);
erase(x, y);
get_size(x);
push(x, y);
pop(x, y);
push_move(x, y);
pop_move(x, y);
reverse(x);
get_str(s, c, b);
parse_str(c, s, e);
out_str(x, y);
in_str(x, y);
out_serial(x, y);
in_serial(x, y);
The following macro are defined and represents a type associated to the variable. They have the same behavior as their corresponding OPERATOR of the oplists and use the typeof keyword:
it_type(x);
sub_type(x);
key_type(x);
value_type(x);
The following macro is defined and enabled to iterate over a container (See example):
each(item, container)
[!Note] Only short names are defined in this header which may be incompatible with your own namespace (This header is still a WIP)
Global User Customization
The behavior of M*LIB can be customized globally by defining the following macros before including any headers of M*LIB. If a macro is not defined before including any M*LIB header, the default value will be used.
These macros shall not be defined after including any M*LIB header.
M_USE_UNDEF_ATOMIC
Undefine the macro _Atomic in m-atomic.h if stdatomic.h is included.
It is needed on MSYS2 due to a bug in their headers which is not fixed yet.
Default value: 1 (undef) on MSYS2, 0 otherwise.
M_USE_STDIO
This macro indicates if the system header stdio.h shall be included
and the FILE functions be defined (1) or not (0).
If it is not included, the macro M_RAISE_FATAL shall be defined by the user.
Default value: 1
M_USE_STDARG
This macro indicates if the system header stdarg.h shall be included
and the va_args functions be defined (1) or not (0).
Default value: 1 (true)
M_USE_SMALL_NAME
This macro indicates if the small names (without the m_ prefix)
have to be defined or not. Historically, only the small name API
existed, so in order to keep API compatibility, the default is true.
Default value: 1
M_USE_CSTR_ALLOC
Define the allocation size of the temporary strings created by M_CSTR
(including the final \0 char).
Default value: 256
M_USE_IDENTIFIER_ALLOC
Define the allocation size of a C identifier in the source code
(excluding the final \0 char).
It is used to represent a C identifier by a C string.
Default value: 128
M_USE_THREAD_BACKEND
Define the thread backend to use by m-thread.h:
- For C11 header
threads.h - For WINDOWS header
windows.h - For POSIX THREAD header
pthread.h - For FreeRTOS
Default value: auto-detect in function of the running system.
M_USE_WORKER
This macro indicates if the multi-thread code of m-worker.h shall be used (1) or not (0)
[!IMPORTANT] In this case, a single-thread code is used
Default value: 1
M_USE_WORKER_CLANG_BLOCK
This macro indicates if the workers shall use the CLANG block extension (1) or not (0).
Default value: 1 (on clang), 0 (otherwise)
M_USE_WORKER_CPP_FUNCTION
This macro indicates if the workers shall use the C++ lambda function (1) or not (0).
Default value: 1 (compiled in C++), 0 (otherwise)
M_USE_BACKOFF_MAX_COUNT
Define the maximum iteration of the BACKOFF exponential scheme
for the synchronization waiting loop of multi-threading code.
Default value: 6
M_USE_SERIAL_MAX_DATA_SIZE
Define the size of the private data (reserved to the serial implementation) in a serial object (as a number of pointers or equivalent objects).
Default value: 4
M_USE_MEMPOOL_MAX_PER_SEGMENT(type)
Define the number of elements to allocate in a segment per object of type type.
Default value: number of elements that fits in a 16KB page.
M_USE_DEQUE_DEFAULT_SIZE
Define the default size of a segment for a deque structure.
Default value: 8 elements.
M_USE_HASH_SEED
Define the seed to inject to the hash computation of an object.
Default value: 0 (predictable hash)
M_USE_FAST_STRING_CONV
Use fast integer conversion algorithms instead of using the LIBC.
Default value: 1 (because it also generates smaller code).
M_USE_DECL
If M_USE_FINE_GRAINED_LINKAGE is not defined,
it will request M*LIB to change the linkage of its symbols globally:
instead of inlining the functions, it will emit weak symbols
for the functions that are not inlined.
And in exactly one translation unit, the macro M_USE_DEF
should also be defined so that it emits the normal definition
of the functions. In which case, it should contain all symbols
used by all other translation units.
You should compile your program with:
-ffunction-sections -fdata-sections
and link with
-Wl,--gc-sections
in order to remove unused code and to merge identical code otherwise it is likely to generate even bigger code than using the inlining linkage.
This works for GCC / CLANG in C mode.
M_USE_FINE_GRAINED_LINKAGE
It will request M*LIB to change the linkage of its symbols dynamically at compile time:
in which case
M_USE_DECL / M_USE_DEF can be defined / undefined several times in a translation unit
and M*LIB will emit the change the linkage of the symbols being declared accordingly:
- definition like if
M_USE_DECLandM_USE_DEFare defined - declaration like if
M_USE_DECLis defined inlinelike otherwise
This enables to inline some functions and not others.
M_USE_DECL / M_USE_DEF shall be defined without effective value.
See M_USE_DECL for more details.
M_USE_PRINT_OPLIST
If defined, it displays the oplist associated to the static assert.
M_MEMORY_ALLOC
See m-core.h
M_MEMORY_REALLOC
See m-core.h
M_MEMORY_FULL
See m-core.h
M_RAISE_FATAL
See m-core.h
M_ASSERT
See m-core.h
M_ASSERT_SLOW
See m-core.h
M_ASSERT_INIT
See m-core.h
M_ASSERT_INDEX
See m-core.h
License
All files of M*LIB are distributed under the following license.
Copyright (c) 2017-2024, Patrick Pelissier All rights reserved.
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
- Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
- Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS AND CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.