Awesome
BiP: Advancing Model Pruning via Bi-level Optimization (NeurIPS 2022)
Repository with code to reproduce the results for compressed networks in our paper on the bi-level optimization-based pruning algorithm.
You can find the video of this paper here.
In this work, we pursue the algorithmic advancement of model pruning. Specifically, we formulate the pruning problem from a fresh and novel viewpoint, bi-level optimization (BLO). We show that the BLO interpretation provides a technically-grounded optimization base for an efficient implementation of the pruning-retraining learning paradigm used in IMP. We also show that the proposed bi-level optimization-oriented pruning method (termed BIP) is a special class of BLO problems with a bi-linear problem structure. By leveraging such bi-linearity, we theoretically show that BIP can be solved as easily as first-order optimization, thus inheriting the computation efficiency. The algorithm pipeline is shown in the figure below.

What is in this repository?
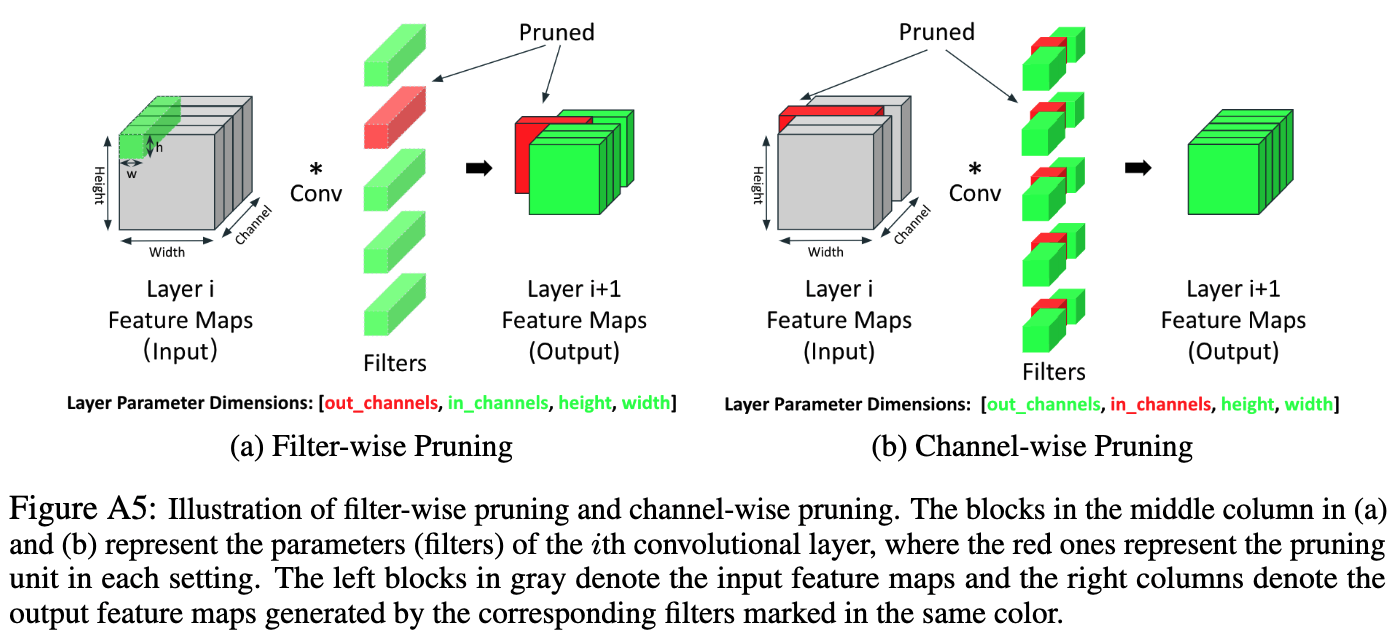
This repository supports three different pruning types: unstructured pruning, filter-wise pruning, and channel-wise pruning. The difference between filter-wise and channel-wise pruning is illustrated in the following figure.
Special credits to HYDRA
We give special credits to HYDRA (code and paper), which provides very good code structure for us to develop our BiP code. The training and evaluation pipeline codes are mostly borrowed from HYDRA, and we do not declare this twice in each file again.
Difference from HYDRA
We emphasize that HYDRA serves as an important baseline in this paper. However, for unstructured pruning, we extend the original HYDRA from layer-wise pruning to global pruning. More specifically, in the original hydra, the pruning ratio of each layer is pre-set and fixed. In our repo, the pruning ratio of each layer is flexible, while we only control the global pruning ratio. We find the flexibility to let the algorithm learn the ratio for each layer further improves the performance.
Getting started
Let's start by installing all the dependencies.
pip3 install -r requirement.txt
We will use train.py for all our experiments. The key arguments and their usage are listed below.
--configsThis argument specifies the configuration file you would like to use, which contains the argument settings that are shared across experiments and may save you time checking your command line. You can also create your own configuration file in the yaml format. We provide different configuration files in the folderconfigsfor different datasets and training modes.--exp-modepretrain | prune | finetuneThis argument specifies the training mode. You should follow the order pretrain-prune-finetune to process your model. Note, that for BiP, finetune is not necessary as we claimed in the paper. However, for extreme sparse case (e.g., remaining ratio < 1%), finetuning is still highly recommended.--trainerbase (HYDRA) | bilevel (BiP)--datasetCIFAR10 | CIFAR100 | TinyImageNet | ImageNetPlease see below for more detailed dataset preparation for TinyImageNet and ImageNet.--kThe fraction of the remaining ratio. For unstructured pruning, we refer to the ratio of the remaining weights over the total model weights. For structured pruning, we refer to the ratio of the remaining filters/channels in each layer and we keep the remaining ratio the same for different layers.--normalizeDo you want to use normalization for your data? Please use this argument throughout the experiments to enforce consistent.--scaled-score-initDo you want to initialize your score proportionate to the model weights? This argument is only valid in the pruning mode and please use this argument throughout experiments.--source-netThis argument specifies the path to your pretrained model (for pruning) or the pruned model (for finetuning). In the mode of "prune" or "finetune", please be sure to input this argument with the right path.--archThis argument specifies the model architecture you would like to use. We support VGG-series, ResNet-series, ResNets-series, and WideResNet-series. The input to this argument must be identical to the ones listed inmodels/__init__.py. Please note, the argumentresnet18andResNet18correspond to different model architectures, which are used for CIFAR-10/CIFAR-100 (low-resolution images) and TinyImageNet/ImageNet (high-resolution images) respectively. The key difference lies in the first convolutional layer. Please see the paper for more details.--resumeThe path to the last checkpoint you would like to resume your training. The checkpoint is saved in the folder./result_dir/exp_name/mode/train_id/checkpoint/checkpoint.pth.tar. If this parameter is specified, there is no need to specify--source-net.--layer-typedense | unstructured | filter | channelWe use this argument to specify the pruning mode. Technically, we modify the convolution layer to have an internal mask. In particular, we can use a masked convolution layer to replace the original convolutional layer in each model. The choice "dense" represents using the original dense structure. "unstructured" means you choose to perform unstructured pruning. "filter" and "channel" corresponds to the structured filter-wise and channel-wise pruning.
Pretraining
In pretraining, we train the networks with k=1 i.e, without pruning. Following examples show how to pretrain a ResNet-18 network on CIFAR-10, CIFAR-100, and TinyImageNet.
python3 train.py --k 1.0 --arch resnet18 --configs configs/CIFAR10/pretrain.yml --seed 1234 --exp-name CIFAR10_resnet18_Pretrain
python3 train.py --k 1.0 --arch resnet18 --configs configs/CIFAR100/pretrain.yml --seed 1234 --exp-name CIFAR100_resnet18_Pretrain
python3 train.py --k 1.0 --arch resnet18 --configs configs/TinyImageNet/pretrain.yml --seed 1234 --exp-name TinyImageNet_resnet18_Pretrain
Pruning
In pruning steps, we will essentially freeze the weights of the network and only update the importance scores.
Unstructured Pruning
The following command will perform unstructured pruning on the pretrained resnet18 network to 99% pruning ratio using BiP.
python3 train.py --arch resnet18 --exp-mode prune --configs configs/CIFAR100/bip.yml --k 0.01 --source-net pretrained_net_checkpoint_path --seed 1234 --exp-name CIFAR10_resnet18_Unstructured_BiP_K0.01
Similarly, we can use the following command to use hydra to prune the pretrained resnet18 network to 99% pruning ratio using BiP.
python3 train.py --arch resnet18 --exp-mode prune configs/CIFAR100/hydra.yml --k 0.01 --source-net pretrained_net_checkpoint_path --seed 1234 --exp-name CIFAR10_resnet18_Unstructured_Hydra_K0.01
Structured Channel-wise Pruning
We can conduct structured channel-wise pruning with the following links. For BiP:
python3 train.py --arch resnet18 --exp-mode prune --configs configs/CIFAR100/bip.yml --layer-type channel --k 0.01 --source-net pretrained_net_checkpoint_path --seed 1234 --exp-name CIFAR10_resnet18_Channel_BiP_K0.01
For Hydra:
python3 train.py --arch resnet18 --exp-mode prune --configs configs/CIFAR100/hydra.yml --layer-type channel --k 0.01 --source-net pretrained_net_checkpoint_path --seed 1234 --exp-name CIFAR10_resnet18_Channel_Hydra_K0.01
Structured Filter-wise Pruning
We can conduct structured Filter-wise pruning with the following links. For BiP:
python3 train.py --arch resnet18 --exp-mode prune --configs configs/CIFAR100/bip.yml --layer-type filter --k 0.01 --source-net pretrained_net_checkpoint_path --seed 1234 --exp-name CIFAR10_resnet18_Filter_BiP_K0.01
For Hydra:
python3 train.py --arch resnet18 --exp-mode prune --configs configs/CIFAR100/hydra.yml --layer-type filter --k 0.01 --source-net pretrained_net_checkpoint_path --seed 1234 --exp-name CIFAR10_resnet18_Filter_Hydra_K0.01
Finetune
In the fine-tuning step, we will update the non-pruned weights but freeze the importance scores. For correct results, we must select the same pruning ratio k and the same layer type as the pruning step.
python train.py --arch resnet18 --exp-mode finetune --configs configs/CIFAR10/finetune.yml --k 0.01 --source-net pruned_net_checkpoint_path --exp-name CIFAR10_resnet18_Unstructured_BiP_K0.01
Sparsity Ratio Series
For unstructured pruning, we strictly follow the ones adopted by the state of the art Lottery Ticket Hypothesis to enable fair comparison. More particular, each time the LTH prunes the 20% of the remaining ratio. Therefore, we set the parameter k to the following values (Figure 3):
k = 0.8000 0.6400 0.5120 0.4100 0.3280 0.2620 0.2097 0.1678 0.1342 0.1074 0.0859 0.0687 0.0550 0.0440 0.0350 0.0280 0.0225 0.0180 0.0144 0.0115 0.0092
Please do not be misled by this sparsity series. For each sparse ratio alone, the BiP prunes from dense model directly to the target sparsity ratio, rather than pruning based on the last checkpoint iteratively.
For structured pruning, we follow the linear sparsity ratio series (Figure 4, A6, and A7):
k = 0.9 0.8 0.7 0.6 0.5 0.4 0.3 0.2 0.1
Dataset Preparation
ImageNet
Option 1 (Preferred, No preparation needed)
Download from google drive:
Training set: https://drive.google.com/file/d/1MdtDpRxi_5T7lXT8IgBWd3f4A7iVMHoQ/view?usp=sharing
Test set: https://drive.google.com/file/d/1I0bd6uNuzmdtZwFR-bnjc0_CWvtZjCYf/view?usp=sharing
The above links lead to TWO separate .lmdb files, which you can download and put in a folder. This option does NOT need any preparation or pre-processing, so it is suggested.
Option 2 (Need Preparation)
The following Process includes downloading and pre-processing the ImageNet dataset from Kaggle. If you have already had your dataset downloaded, please directly go to step 9.
The official kaggle website for ImageNet dataset is here.
- Run
pip3 install kaggle - Register an account at kaggle.
- Agree the terms and conditions on the dataset page.
- Go to your account page (https://www.kaggle.com//account). Select 'Create API Token' and this will trigger the download of
kaggle.json, a file containing your API credentials. - Copy this file into your server at
~/.kaggle/kaggle.json. - Run command
chmod 600 ~/.kaggle/kaggle.jsonand make it visible only to yourself. - Run command
kaggle competitions download -c imagenet-object-localization-challenge
- Unzip the file
unzip -q imagenet-object-localization-challenge.zip
tar -xvf imagenet_object_localization_patched2019.tar.gz
- Enter the validation set folder
cd ILSVRC/Data/CLS-LOC/val - Run script sh/prepare_imagenet.sh provided by the PyTorch repository, to move the validation subset to the labeled subfolders.
TinyImageNet
To obtain the original TinyImageNet dataset, please run the following scripts:
wget http://cs231n.stanford.edu/tiny-imagenet-200.zip
unzip -qq 'tiny-imagenet-200.zip'
rm tiny-imagenet-200.zip
Contributors
Some of the code in this repository is based on the following amazing works.
Citation
If you find this work helpful, please consider citing our paper.
@inproceedings{zhang2022pruning,
title = {Advancing Model Pruning via Bi-level Optimization},
author = {Zhang, Yihua and Yao, Yuguang and Ram, Parikshit and Zhao, Pu and Chen, Tianlong and Hong, Mingyi and Wang, Yanzhi and Liu, Sijia},
booktitle = {Thirty-sixth Conference on Neural Information Processing Systems},
year = {2022}
}