Awesome
AgeFromName 0.0.8
A tool for predicting someone's age, gender, or generation given their name and assigned sex at birth, assuming they were born in the US.
Feel free to use the Gitter community gitter.im/agefromname for help or to discuss the project.
Installation
$ pip install agefromname
Overview
This more or less apes the approach of FiveThirtyEight's "How to Tell if Someone's Age When All you Know Is Her Name" article.
It includes data collected scraped from the Social Security
Administration's Life Tables for the United States Social Security Area 1900-2100
and their baby names data. Code is included
to re-scrape and refresh this data in regenerate_data.py. It includes data as far back as
1981.
To use, first initialize the finder
>>> from agefromname import AgeFromName
>>> age_from_name = AgeFromName()
You find the probability of someone's gender based on their first name and optionally, the current year, their minimum age, and/or their maximum age.
>>> age_from_name.prob_male('taylor')
0.24956599946849847
>>> age_from_name.prob_female('taylor')
0.7504340005315016
>>> age_from_name.prob_male('taylor', minimum_age=50)
0.9572157723373936
>>> age_from_name.prob_male('taylor', current_year=1930)
1.0
>>> age_from_name.prob_male('taylor', current_year=2010, minimum_age=30)
0.8497712563439375
>>> age_from_name.prob_male('taylor', current_year=2010, minimum_age=30, maximum_age=40)
0.7645011554551521
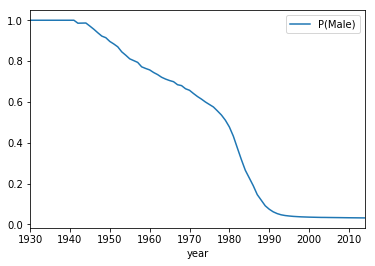
You can even plot the plot, given a current year, the probability someone named Kelsey would be female:
>>> (pd.DataFrame([{'year': year,
'P(Male)': age_from_name.prob_male('kelsey', current_year=year)}
for year in range(1930, 2015)])
.set_index('year')
.plot())
One can perform this computation in bulk for all names. Here, we can see a 95% confidence intervals of how likely people over 18 in 1993 were females given their names:
>>> age_from_name.get_all_name_female_prob(current_year=1993, minimum_age=18).iloc[:3]
hi lo prob
first_name
aage 0.648197 0.000000 0.0
aagot 1.000000 0.380786 1.0
aamir 0.398189 0.000000 0.0
Now you can use this to get the mode of someone's age, give their first name and gender. Note that their gender should be a single letter, 'm' or 'f' (case-insensitive), and that the first name is case-insensitive as well.
>>> age_from_name.argmax('jAsOn', 'm')
1977
>>> age_from_name.argmax('Jason', 'M')
1977
You can also include an "as-of" year. For example, in 1980, the argmax year for "John" was 1947, while in 2000 it was 1964. Note that if omitted, the current year is used.
>>> age_from_name.argmax('john', 'm', 2000)
1964
>>> age_from_name.argmax('john', 'm', 1980)
1947
Furthermore, you can exclude people who are younger than a particular age.
>>> age_from_name.argmax('bill', 'm', 1980, minimum_age=40)
1934
>>> age_from_name.argmax('bill', 'm', minimum_age=40)
1959
Getting estimated counts of living people with a giving name and gender at a particular date is easy, and given in a Pandas Series.
>>> age_from_name.get_estimated_counts('john', 'm', 1960)
year_of_birth
1881 4613.792420
1882 5028.397099
1883 4679.560929
...
We can see corresponding probability distribution using
>>> age_from_name.get_estimated_distribution('mary', 'f', 1910)
year_of_birth
1881 0.016531
1882 0.019468
1883 0.019143
...
Finally, we can see similar information for generations, as well, using the GenerationFromName class.
>>> from agefromname import GenerationFromName
>>> generation_from_name = GenerationFromName()
>>> generation_from_name.argmax('barack', 'm')
'Generation Z'
>>> generation_from_name.argmax('ashley', 'f')
'Millenials'
>>> generation_from_name.argmax('monica', 'f')
'Generation X'
>>> generation_from_name.argmax('bill', 'm')
'Baby Boomers
>>> generation_from_name.argmax('wilma', 'f')
'Silent'
>>> generation_from_name.get_estimated_distribution('jaden', 'm')
Baby Boomers 0.000000
Generation X 0.001044
Generation Z 0.897662
Greatest Generation 0.000000
Millenials 0.101294
_other 0.000000
Name: estimate_percentage, dtype: float64
>>> generation_from_name.get_estimated_distribution('gertrude', 'f')
Baby Boomers 0.259619
Generation X 0.031956
Generation Z 0.009742
Greatest Generation 0.425293
Millenials 0.011412
_other 0.261979
>>> generation_from_name.get_estimated_counts('ashley', 'f')
Baby Boomers 702.481287
Generation X 29274.206090
Generation Z 141195.016621
Greatest Generation 34.998913
Millenials 652914.233604
_other 0.102625
Name: estimated_count, dtype: float64
Caveat Usor
The Social Security Administration records the 1,000 most common male and female baby names + birth counts each year. These may not be fully representative of the entire population, and may not work as well for people whose names aren't historically common among those born in the US or other groups.
Be aware that there are people who have near-dogmatic objections to this sort of analysis, especially using a first name to impute a gender.