Awesome
InternLM
InternLM is a multilingual large language model jointly developed by Shanghai AI Lab and SenseTime (with equal contribution), in collaboration with the Chinese University of Hong Kong, Fudan University, and Shanghai Jiaotong University.
Technical report: [PDF]
Note: Please right click the link above to directly download the PDF file.
Abstract
We present InternLM, a multilingual foundational language model with 104B parameters. InternLM is pre-trained on a large corpora with 1.6T tokens with a multi-phase progressive process, and then fine-tuned to align with human preferences. We also developed a training system called Uniscale-LLM for efficient large language model training. The evaluation on a number of benchmarks shows that InternLM achieves state-of-the-art performance in multiple aspects, including knowledge understanding, reading comprehension, mathematics, and coding. With such well-rounded capabilities, InternLM achieves outstanding performances on comprehensive exams, including MMLU, AGIEval, C-Eval and GAOKAO-Bench, without resorting to external tools. On these benchmarks, InternLM not only significantly outperforms open-source models, but also obtains superior performance compared to ChatGPT. Also, InternLM demonstrates excellent capability of understanding Chinese language and Chinese culture, which makes it a suitable foundation model to support Chinese-oriented language applications. This manuscript gives a detailed study of our results, with benchmarks and examples across a diverse set of knowledge domains and tasks.
Main Results
As latest large language models begin to exhibit human-level intelligence, exams designed for humans, such as China's college entrance examination and US SAT and GRE, are considered as important means to evaluate language models. Note that in its technical report on GPT-4, OpenAI tested GPT-4 through exams across multiple areas and used the exam scores as the key results.
We tested InternLM in comparison with others on four comprehensive exam benchmarks, as below:
-
MMLU: A multi-task benchmark constructed based on various US exams, which covers elementary mathematics, physics, chemistry, computer science, American history, law, economics, diplomacy, etc.
-
AGIEval: A benchmark developed by Microsoft Research to evaluate the ability of language models through human-oriented exams, which comprises 19 task sets derived from various exams in China and the United States, e.g., the college entrance exams and lawyer qualification exams in China, and SAT, LSAT, GRE and GMAT in the United States. Among the 19 task sets, 9 sets are based on the Chinese college entrance exam (Gaokao), which we single out as an important collection named AGIEval (GK).
-
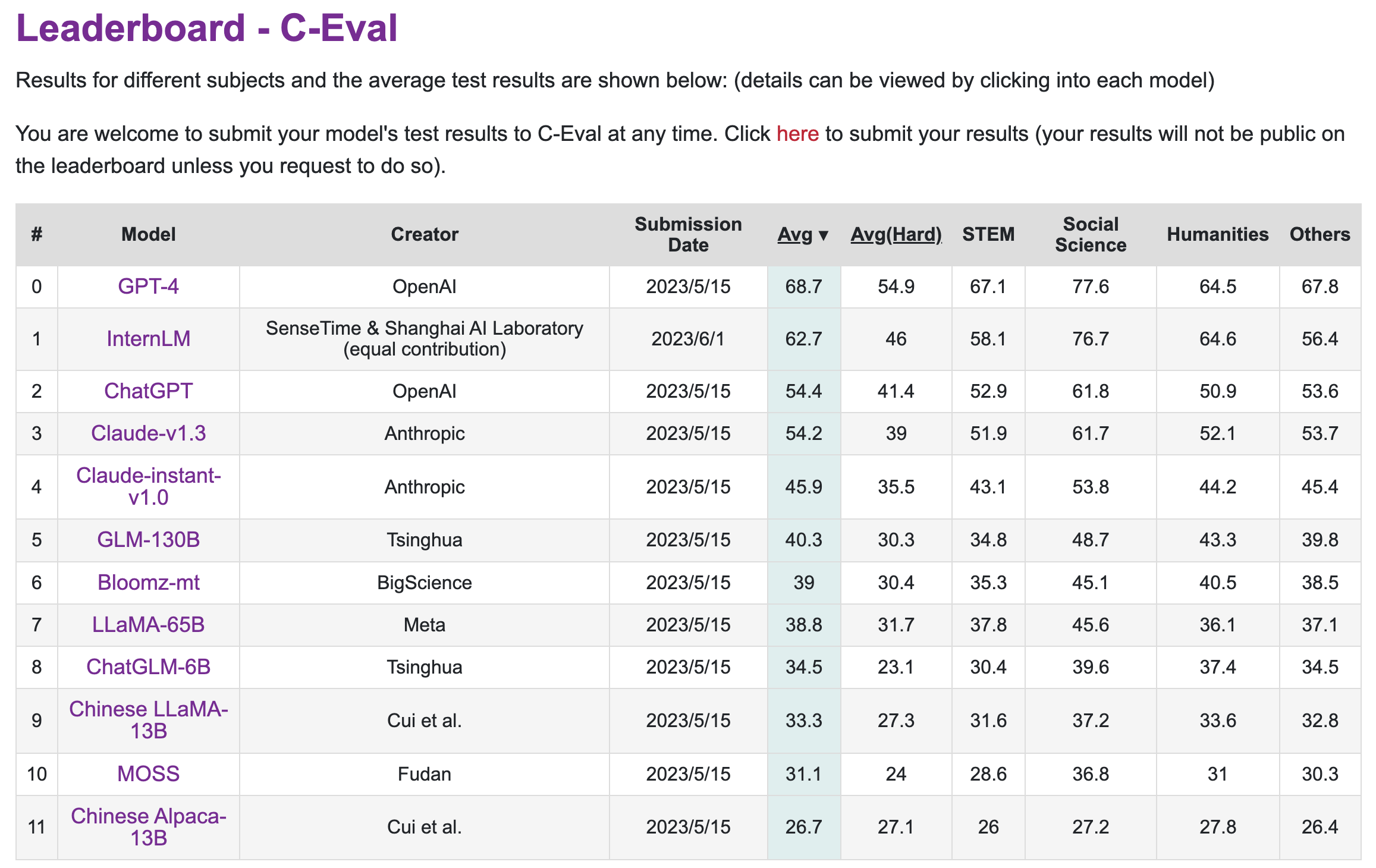
C-Eval: A comprehensive benchmark devised to evaluate Chinese language models, which contains nearly 14,000 questions in 52 subjects, covering mathematics, physics, chemistry, biology, history, politics, computer and other disciplines, as well as professional exams for civil servants, certified accountants, lawyers, and doctors.
-
GAOKAO-Bench: A comprehensice benchmark based on the Chinese college entrance exams, which include all subjects of the college entrance exam. It provide different types of questions, including multiple-choices, blank filling, and QA. For conciseness, we call this benchmark simply as Gaokao.
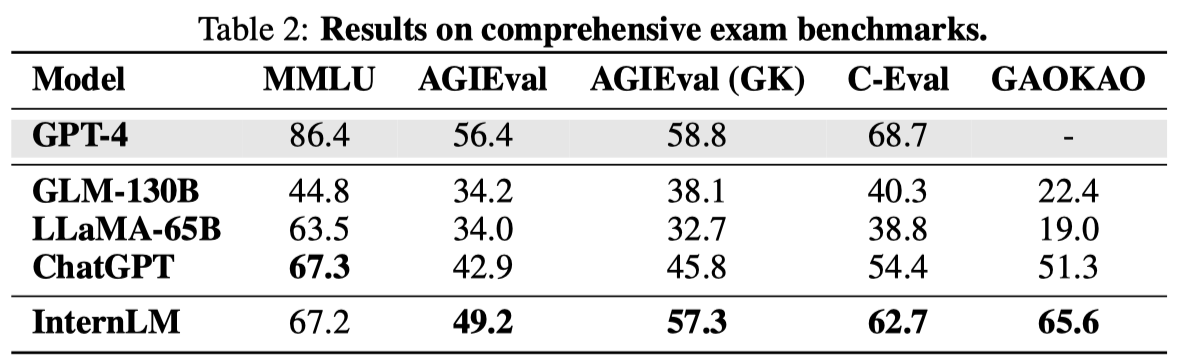
Results on MMLU
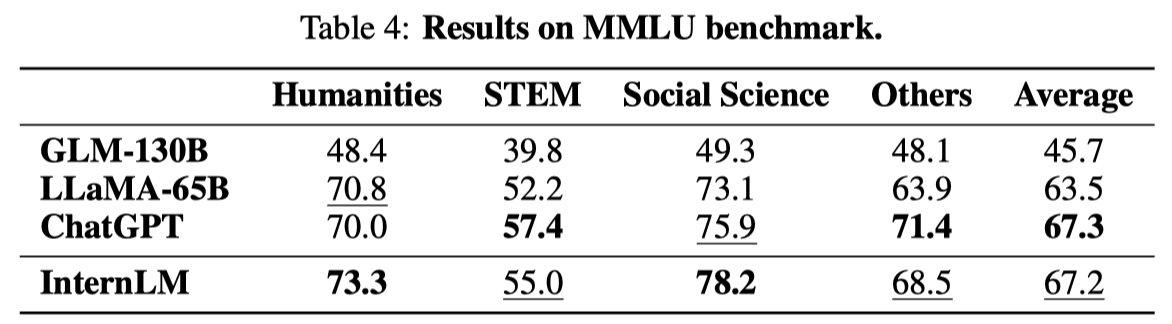
Results on AGIEval
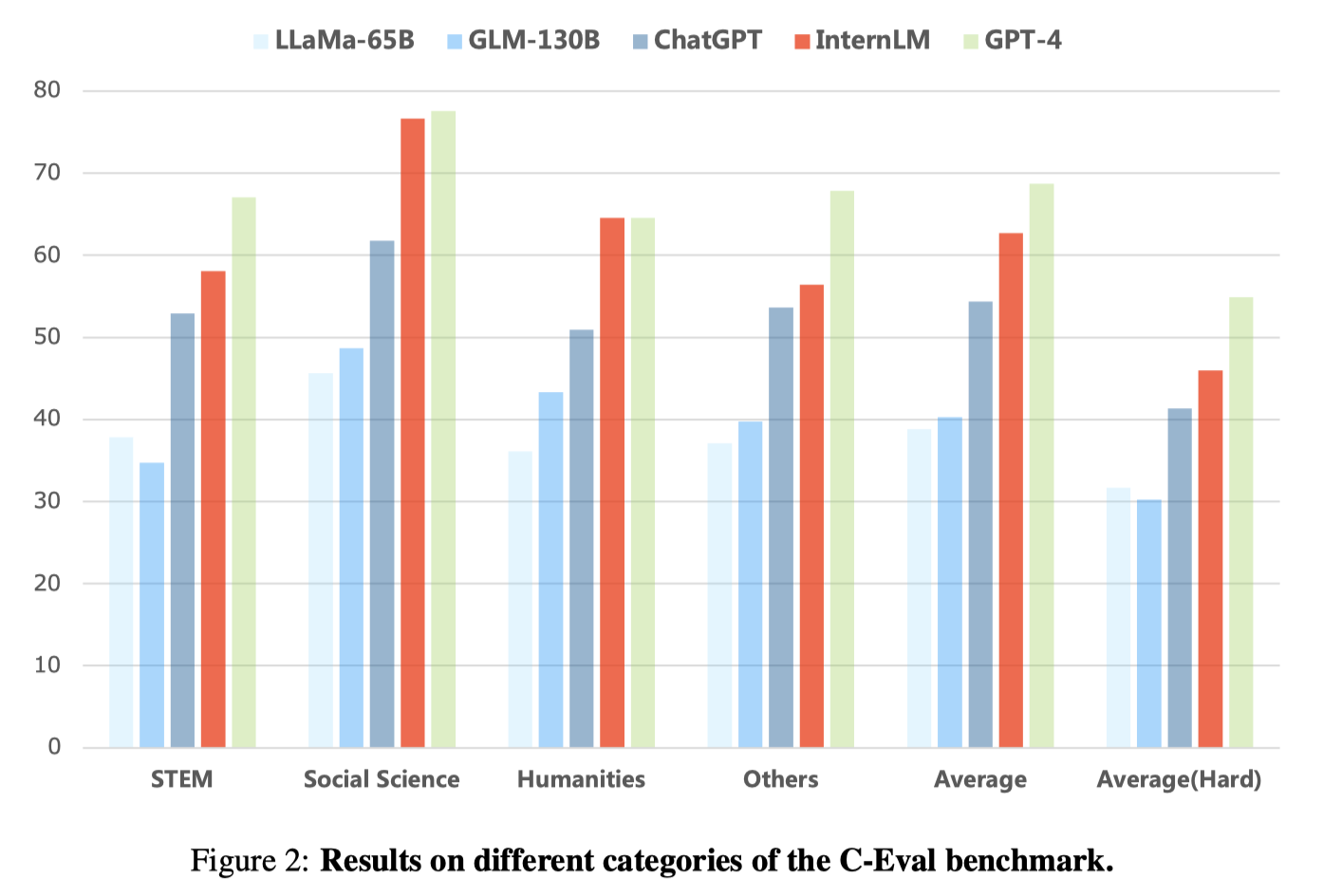
Results on C-Eval
C-Eval has a live leaderboard. Below is a screenshot that shows all the results (as of 2023-06-01).
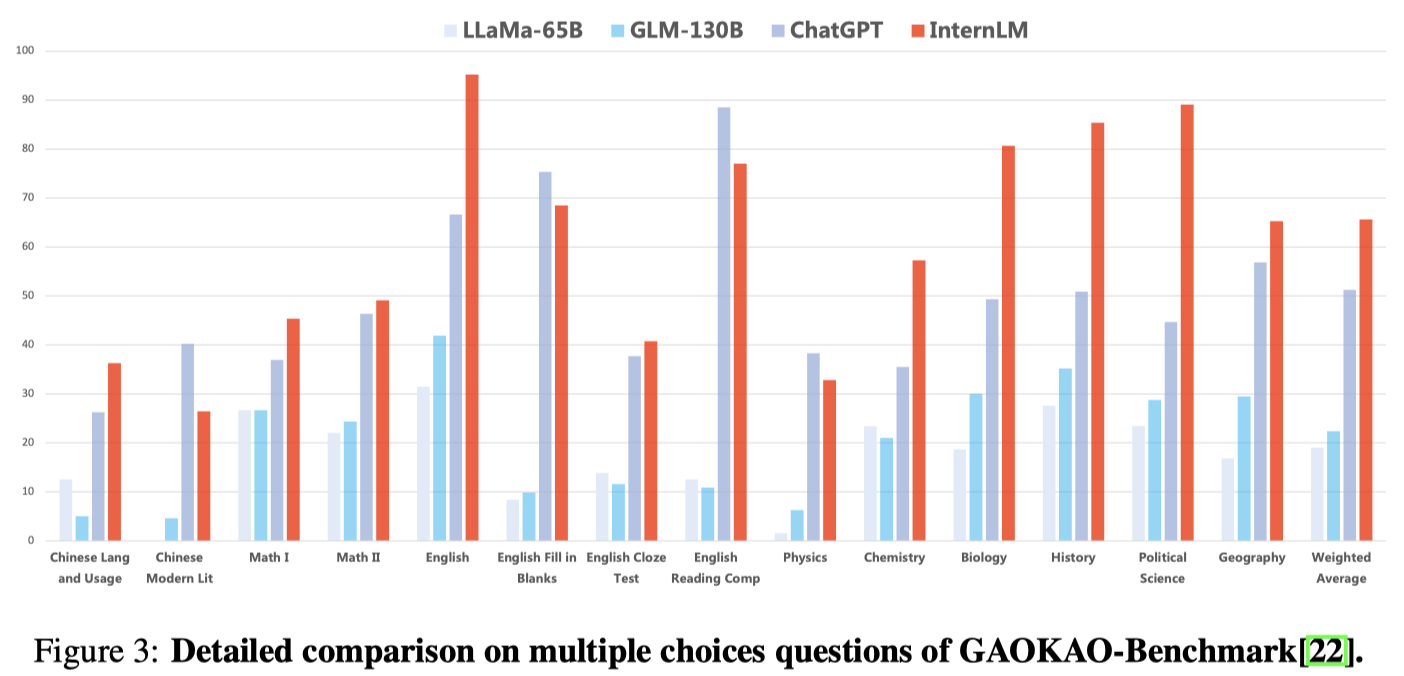
Results on GAOKAO-Benchmark
Benchmarks in Specific Aspects
We also tested InternLM in comparison with others in multiple aspects:
- Knowledge QA: TriviaQA and NaturalQuestions.
- Reading Comprehension: RACE
- Chinese Understanding: CLUE and FewCLUE
- Mathematics: GSM8k and MATH
- Coding: HumanEval and MBP
Please refer to our technical report for detailed results.
We are working on more tests, and will share new results as our work proceeds.
Citation
You can cite this technical report like this:
@misc{2023internlm,
title={InternLM: A Multilingual Language Model with Progressively Enhanced Capabilities},
author={InternLM Team},
howpublished = {\url{https://github.com/InternLM/InternLM-techreport}},
year={2023}
}