Awesome
CLiMB: The Continual Learning in Multimodality Benchmark
CLiMB is a benchmark to study the challenge of learning multimodal tasks in a CL setting, and to systematically evaluate how upstream continual learning can rapidly generalize to new multimodal and unimodal tasks.
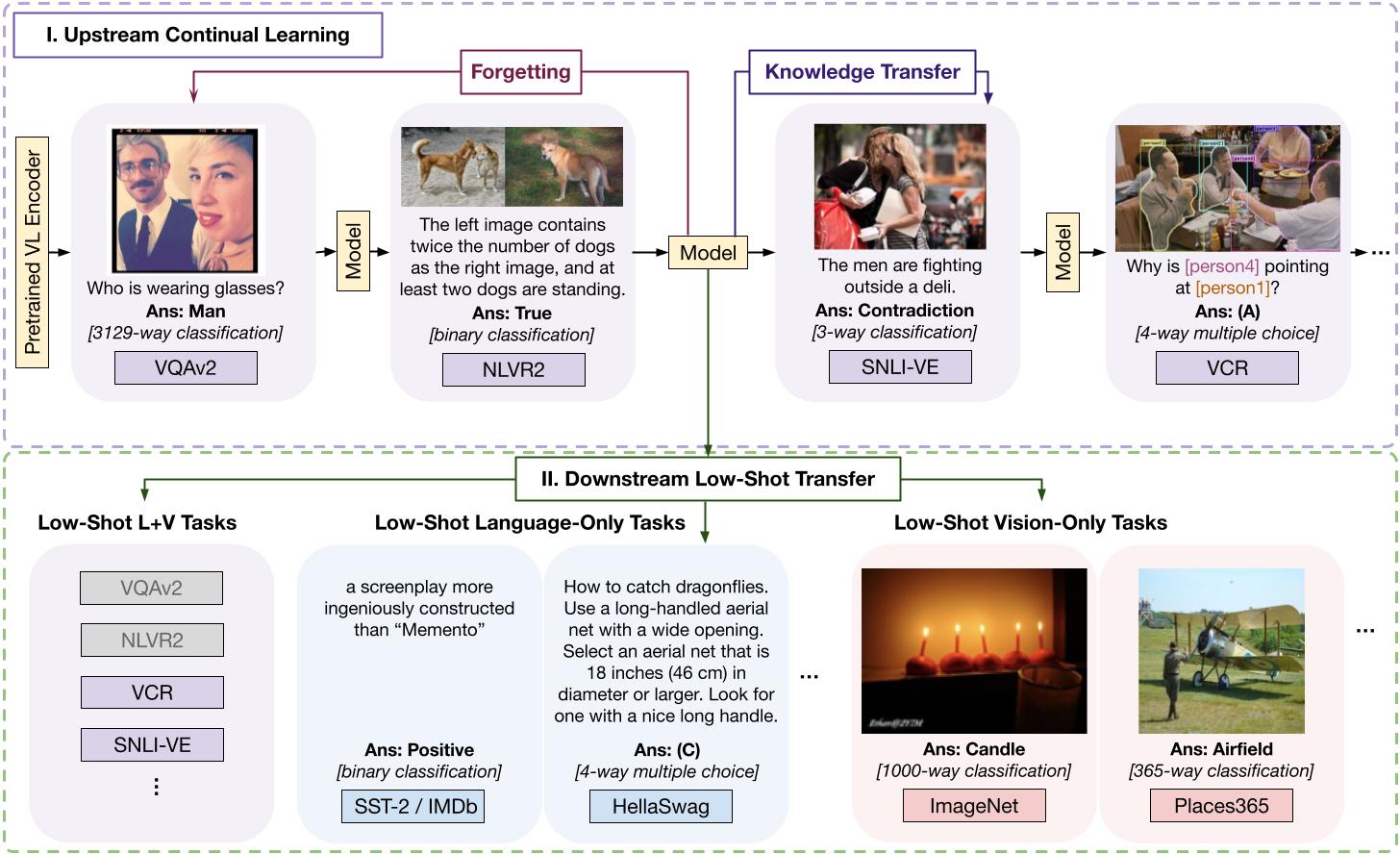
CLiMB evaluates candidate CL models and learning algorithms in two phases. For Phase I, Upstream Continual Learning, a pre-trained multimodal model is trained on a sequence of vision-and-language tasks, and evaluated after each task on its degree of Forgetting of past tasks and Knowledge Transfer to the next task. For Phase II, after each multimodal task the model is evaluated for its Downstream Low-Shot Transfer capability on both multimodal and unimodal tasks.
Setup
- Create Conda environment with Python 3.6
conda create -n climb python=3.6
conda activate climb
- Install requirements
git clone https://github.com/GLAMOR-USC/CLiMB.git --recurse-submodules
pip install -r requirements.txt -f https://download.pytorch.org/whl/torch_stable.html
cd src/adapter-transformers
pip install -e .
Data
Downloading and Organizing Existing Tasks
Adding New Tasks
Models
Existing Models
The initial implementation of CLiMB includes two Vision-Language encoders: ViLT and ViLT-BERT. ViLT is a Vision-Language Transformer that operates over lanugage inputs and image patches. ViLT-BERT is a modification of ViLT, where the Transformer's language input embeddings are replaced with language representations extracted from a pre-trained frozen BERT.
Adding New Models
Continual Learning Algorithms
Adding New CL Algorithms
Training in CLiMB
All experiment scripts are executed from within the src/ directory.
Upstream Continual Learning
Downstream Low-Shot Transfer
To run downstream tasks, you need to first run upstream tasks and save the checkpoints.
Low-Shot Multimodal Transfer
For low-shot multimodal transfer, the train/train_lowshot_multimodal.py script takes all the CL checkpoints from a single upstream CL experiment, and does low-shot transfer of each checkpoint to the unseen multimodal tasks (e.g. if the task order is VQAv2 -> NLVR2 -> SNLI-VE -> VCR, then the VQA checpoint is tuned on low-shot NLVR2, SNLI-VE, and VCR, whereas the NLVR2 checkpoint is transfered to low-shot SNLI-VE and VCR only. An example script can be seen [here](sh exp_scripts/lowshot_multimodal/vqa_nlvr_snlive_vcr/vilt-sequential_ft.sh).
For low-shot unimodal transfer, you need to specify a particular upstream CL checkpoint. You can then run downstream tasks with the following scripts:
Low-Shot Language-Only Tasks
SST-2, IMDb
For ViLT encoder,
bash exp_scripts/lang/vilt-seq.sh
For ViLT-BERT encoder,
bash exp_scripts/lang/viltbert-seq.sh
PIQA, HellaSwag, CommonsenseQA
For ViLT encoder,
bash exp_scripts/lang/vilt-mc.sh
For ViLT-BERT encoder,
bash exp_scripts/lang/viltbert-mc.sh
Low-Shot Vision-Only Tasks
ImageNet, iNaturalist2019, Places365
bash exp_scripts/vision/vilt-cls.sh
COCO-object
bash exp_scripts/vision/vilt-coco-obj.sh
Contributing to CLiMB
We are looking to keep CLiMB growing with new tasks and models and algorithms! If you want to add a new task/model/algorithm into the CLiMB benchmark for other researchers to play around with, just create a Pull Request from your fork of CLiMB and we will try to integrate it!
Contact
Questions or issues? Contact tejas.srinivasan@usc.edu