Awesome
<div align="center"><a href="https://www.tensorflow.org">
<a href="https://github.com/EMalagoli92/GCViT-TensorFlow/blob/main/LICENSE">
<a href="https://www.python.org">
</a>
GCViT-TensorFlow
TensorFlow 2.X reimplementation of Global Context Vision Transformers Ali Hatamizadeh, Hongxu (Danny) Yin, Jan Kautz Pavlo Molchanov.
- Exact TensorFlow reimplementation of official PyTorch repo, including
timmmodules used by authors, preserving models and layers structure. - ImageNet pretrained weights ported from PyTorch official implementation.
Table of contents
<div id="abstract"/>Abstract
GC ViT achieves state-of-the-art results across image classification, object detection and semantic segmentation tasks. On ImageNet-1K dataset for classification, the tiny, small and base variants of GC ViT with 28M, 51M and 90M, surpass comparably-sized prior art such as CNN-based ConvNeXt and ViT-based Swin Transformer by a large margin. Pre-trained GC ViT backbones in downstream tasks of object detection, instance segmentation,
and semantic segmentation using MS COCO and ADE20K datasets outperform prior work consistently, sometimes by large margins.
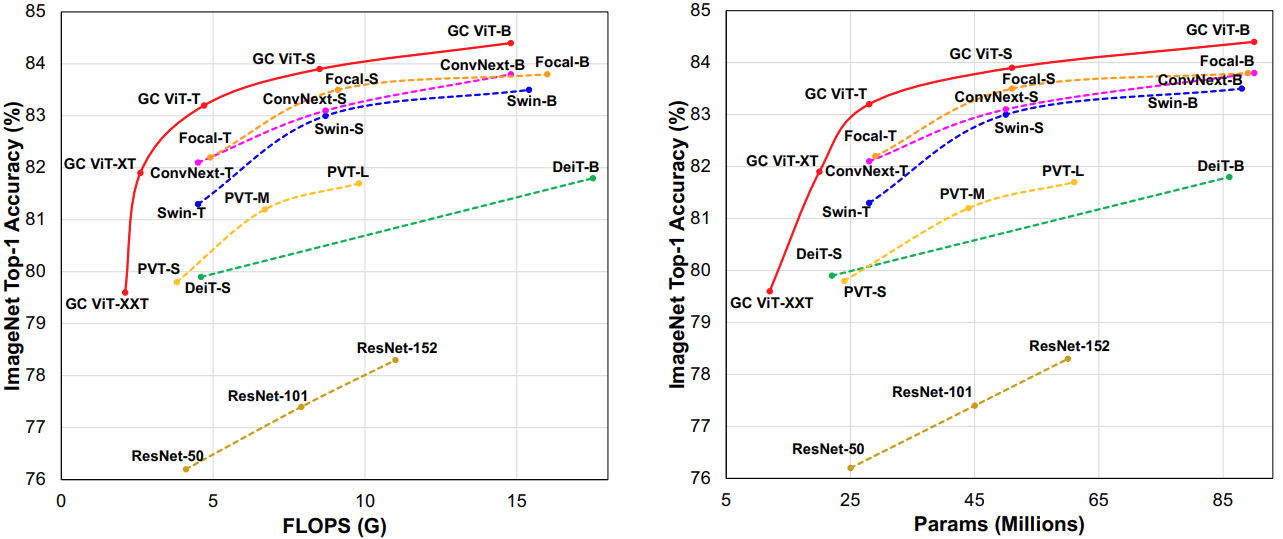

Results
TensorFlow implementation and ImageNet ported weights have been compared to the official PyTorch implementation on ImageNet-V2 test set.
| Configuration | Top-1 (Original) | Top-1 (Ported) | Top-5 (Original) | Top-5 (Ported) | #Params |
|---|---|---|---|---|---|
| GCViT-XXTiny | 68.79 | 68.73 | 88.52 | 88.47 | 12M |
| GCViT-XTiny | 70.97 | 71 | 89.8 | 89.79 | 20M |
| GCViT-Tiny | 72.93 | 72.9 | 90.7 | 90.7 | 28M |
| GCViT-Small | 73.46 | 73.5 | 91.14 | 91.08 | 51M |
| GCViT-Base | 74.13 | 74.16 | 91.66 | 91.69 | 90M |
Mean metrics difference: 3e-4.
Installation
- Install from PyPI
pip install gcvit-tensorflow
- Install from Github
pip install git+https://github.com/EMalagoli92/GCViT-TensorFlow
- Clone the repo and install necessary packages
git clone https://github.com/EMalagoli92/GCViT-TensorFlow.git
pip install -r requirements.txt
Tested on Ubuntu 20.04.4 LTS x86_64, python 3.9.7.
<div id="usage"/>Usage
- Define a custom GCViT configuration.
from gcvit_tensorflow import GCViT
# Define a custom GCViT configuration
model = GCViT(
depths=[2, 2, 6, 2],
num_heads=[2, 4, 8, 16],
window_size=[7, 7, 14, 7],
dim=64,
resolution=224,
in_chans=3,
mlp_ratio=3,
drop_path_rate=0.2,
data_format="channels_last",
num_classes=100,
classifier_activation="softmax",
)
- Use a predefined GCViT configuration.
from gcvit_tensorflow import GCViT
model = GCViT(configuration="xxtiny")
model.build((None, 224, 224, 3))
print(model.summary())
Model: "xxtiny"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
patch_embed (PatchEmbed) (None, 56, 56, 64) 45632
pos_drop (Dropout) (None, 56, 56, 64) 0
levels/0 (GCViTLayer) (None, 28, 28, 128) 185766
levels/1 (GCViTLayer) (None, 14, 14, 256) 693258
levels/2 (GCViTLayer) (None, 7, 7, 512) 5401104
levels/3 (GCViTLayer) (None, 7, 7, 512) 5400546
norm (LayerNorm_) (None, 7, 7, 512) 1024
avgpool (AdaptiveAveragePoo (None, 512, 1, 1) 0
ling2D)
head (Linear_) (None, 1000) 513000
=================================================================
Total params: 12,240,330
Trainable params: 11,995,428
Non-trainable params: 244,902
_________________________________________________________________
- Train from scratch the model.
# Example
model.compile(
optimizer="sgd",
loss="sparse_categorical_crossentropy",
metrics=["accuracy", "sparse_top_k_categorical_accuracy"],
)
model.fit(x, y)
- Use ported ImageNet pretrained weights
# Example
from gcvit_tensorflow import GCViT
model = GCViT(configuration="base", pretrained=True, classifier_activation="softmax")
y_pred = model(image)
Acknowledgement
<div id="citations"/>Citations
@article{hatamizadeh2022global,
title={Global Context Vision Transformers},
author={Hatamizadeh, Ali and Yin, Hongxu and Kautz, Jan and Molchanov, Pavlo},
journal={arXiv preprint arXiv:2206.09959},
year={2022}
}
License
This work is made available under the MIT License
The pre-trained weights are shared under CC-BY-NC-SA-4.0