Awesome
fastPRNG
fastPRNG is a single header-only FAST 32/64 bit PRNG (pseudo-random generator), highly optimized to obtain faster code from compilers, it's based on xoshiro / xoroshiro (Blackman/Vigna), xorshift and other Marsaglia algorithms.
64bit algorithms
- Blackman/Vigna
- xoshiro256+ / xoshiro256++ / xoshiro256**
- xoroshiro128+ / xoroshiro128++ / xoroshiro128**
- Marsaglia
- xorshift
- znew / wnew / MWC / CNG / FIB / XSH / KISS
32bit algorithms
- Blackman/Vigna
- xoshiro128+ / xoshiro128++ / xoshiro128**
- xoroshiro64+ / xoroshiro64++
- Marsaglia
- xorshift
- znew / wnew / MWC / CNG / FIB / XSH / KISS
- LFIB4 / SWB
fastPRNG distribution tests - live WebGL
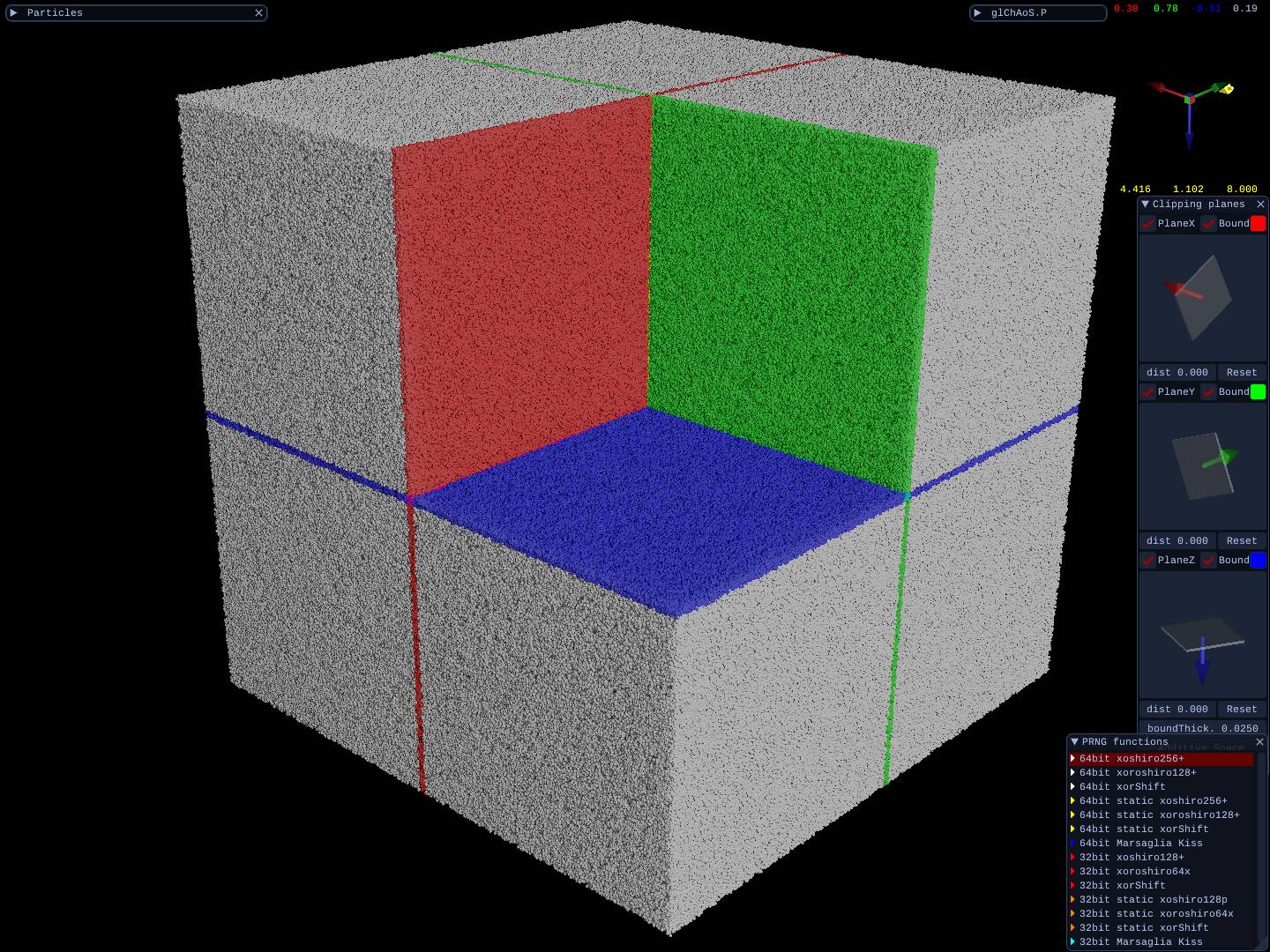
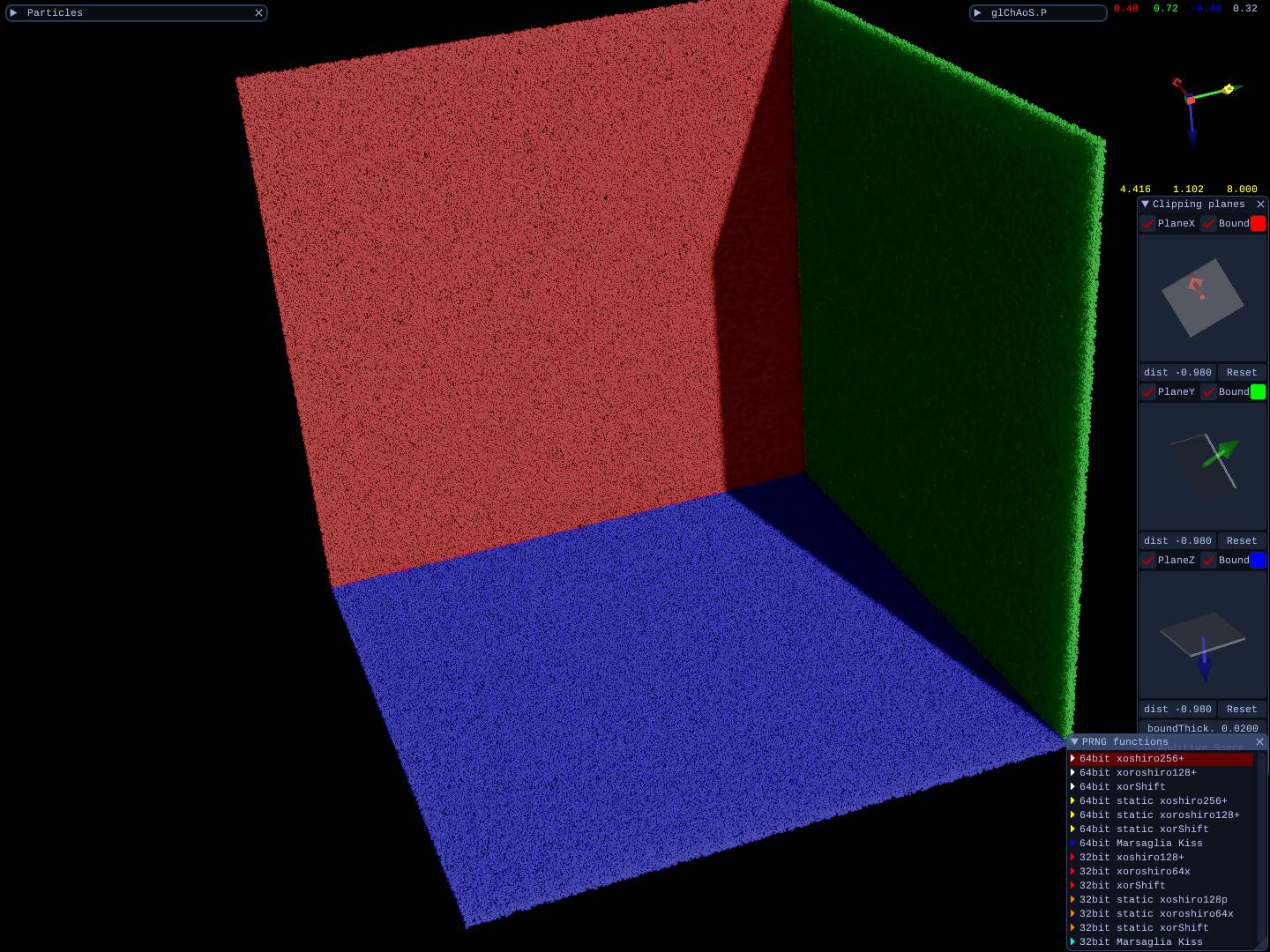
All functions are tested, below the distribution test screenshots in a cube with [-1.0, 1.0] side (OpenGL/WebGL)
| 30M dots/spheres<br> | 30M dots/spheres<br> clipping planes | 3 thin boards<br>from 30M cube dots/spheres |
|---|---|---|
 |  |  |
==> *view the Live WebGL distribution test section.
<p> <br></p>Return values and floating point
All base functions return integers:
- 32bit ==>
uint32_tin[0, UINT32_MAX]interval - 64bit ==>
uint64_tin[0, UINT64_MAX]interval.
*If you need (e.g.) values between [INT32_MIN, INT32_MAX], just cast result to int32_t, same for 64bit (cast to int64_t): look at the examples below
Floating point helpers
- There are a single/double precision floating point template functions, to generate fast numbers in:
(they have same base name, but with the following suffix)[-1.0, 1.0]interval ==> suffix _VNI<T> (Vector Normalized Interval)[ 0.0, 1.0]interval ==> suffix _UNI<T> (Unity Normalized Interval)[ min, max]interval ==> suffix _Range<T>(min, max)
*look at the examples below
<p> <br></p>How to use - Examples
To use it just include fastPRNG.h in your code:
#include "fastPRNG.h"
It contains following classes and member functions, inside the namespace fastPRNG:
64bit classes and members
- fastXS64 ==> contains xor-shift algorithms
- xoshiro256p / xoshiro256pp / xoshiro256xx
- xoroshiro128p / xoroshiro128pp / xoroshiro128xx
- xorShift
- fastXS64s ==> same as before, but class with static members, to use directly w/o declaration
- fastXS64s::xoshiro256p / fastXS64s::xoshiro256pp / fastXS64s::xoshiro256xx
- fastXS64s::xoroshiro128p / fastXS64s::xoroshiro128pp / fastXS64s::xoroshiro128xx
- fastXS64s::xorShift
- fastRand64 ==> other Marsaglia algorithms
- znew / wnew / MWC / CNG / FIB / XSH / KISS
32bit classes and members
- fastXS32 ==> contains xor-shift algorithms
- xoshiro128p / xoshiro128pp / xoshiro128xx
- xoroshiro64p / xoroshiro64pp
- xorShift
- fastXS32s ==> same as before, but class with static members, to use directly w/o declaration
- fastXS32s::xoshiro128p / fastXS32s::xoshiro128pp / fastXS32s::xoshiro128xx
- fastXS32s::xoroshiro64p / fastXS32s::xoroshiro64pp
- fastXS32s::xorShift
- fastRand32 ==> other Marsaglia algorithms
- znew / wnew / MWC / CNG / FIB / XSH / KISS
- LFIB4 / SWB
Examples
- Example: use xoshiro256+ 64bit algorithm:
using fastPRNG;
fastXS64 fastR; // default "chrono" seed
// fastXS64 fastR(0x123456789ABCDEF0); // personal seed also to (re)generate a specific random numbers sequence
for(int i=0; i<10000; i++) {
cout << fastR.xoshiro256p() << endl; // returns number in [0, UINT64_MAX] interval
cout << int64_t(fastR.xoshiro256p()) << endl; // returns number in [INT64_MIN, INT32_MAX] interval
cout << fastR.xoshiro256p_VNI<float>()) << endl; // returns number in [-1.0, 1.0] interval in single precision
cout << fastR.xoshiro256p_UNI<float>()) << endl; // returns number in [ 0.0, 1.0] interval in single precision
cout << fastR.xoshiro256p_Range<double>(-3.0, 7.0)) << endl; // returns number in [-3.0, 7.0] interval in double precision
}
// N.B. all members/functions share same seed and subsequent xor & shift operations on it.
// it is usually not a problem, but if need different seeds (or separate PRNG) have to declare
// more/different fastXS64 objects
// or you can also use static members from fastXS64s class w/o declaration: the seed is always "chrono"
for(int i=0; i<10000; i++) {
cout << fastXS64s::xoshiro256p() << endl; // returns number in [0, UINT64_MAX] interval
cout << int64_t(fastXS64s::xoshiro256p()) << endl; // returns number in [INT64_MIN, INT32_MAX] interval
cout << fastXS64s::xoshiro256p_VNI<float>()) << endl;// returns number in [-1.0, 1.0] interval in single precision from 64bit PRNG
cout << fastXS64s::xoshiro256p_UNI<float>()) << endl;// returns number in [ 0.0, 1.0] interval in single precision from 64bit PRNG
cout << fastXS64s::xoshiro256p_Range<double>(-5.0, 5.0)) << endl; // returns number in [-5.0, 5.0] interval in double precision from 64bit PRNG
}
// N.B. all members/functions share same seed, and subsequent xor & shift operations on it.
// it is usually not a problem, but if need different seeds (or separate PRNG) have to use
// fastXS64 (non static) class, and have to declare different fastXS64 objects.
// static declaration of a non static class (e.g. if you need to initialize it to specific seed)
for(int i=0; i<10000; i++) {
static fastXS64 fastR(0x123456789ABCDEF0); // personal seed also to (re)generate a specific random numbers sequence
cout << fastR.xoshiro256p() << endl; // returns number in [0, UINT64_MAX] interval
cout << int64_t(fastR.xoshiro256p()) << endl; // returns number in [INT64_MIN, INT32_MAX] interval
cout << fastR.xoshiro256p_VNI<float>()) << endl; // returns number in [-1.0, 1.0] interval in single precision
cout << fastR.xoshiro256p_UNI<float>()) << endl; // returns number in [ 0.0, 1.0] interval in single precision
cout << fastR.xoshiro256p_Range<double>(-3.0, 7.0)) << endl; // returns number in [-3.0, 7.0] interval in double precision
}
- Example: use KISS 32bit algorithm:
fastPRNG::fastRand32 fastRandom; // for 32bit
// fstRnd::fastRand32 fastRandom(0x12345678); or with seed initialization: to (re)generate a specific random numbers sequence
for(int i=0; i<10000; i++) {
cout << fastRandom.KISS() << endl; // returns number in [0, UINT32_MAX] interval
cout << int32_t(fastRandom.KISS()) << endl; // returns number in [INT32_MIN, INT32_MAX] interval
cout << fastRandom.KISS_VNI<float>()) << endl;// returns number in [-1.0, 1.0] interval in single precision from 32bit PRNG
cout << fastRandom.KISS_UNI<float>()) << endl;// returns number in [ 0.0, 1.0] interval in single precision from 32bit PRNG
cout << fastRandom.KISS_Range<double>(-3.0, 7.0)) << endl; // returns number in [-3.0, 7.0] interval in from 32bit PRNG
}
- Any class object can to re-initialized with a new seed calling
seed()
fastPRNG::fastXS32 fastR(0x12345678); // seed to specific value
for(int i=0; i<10000; i++)
cout << fastR.xoshiro256p() << endl; // returns number in [0, UINT64_MAX] interval
fastR.seed(0x12345678); // same seed to obtain same sequence
for(int i=0; i<10000; i++)
cout << fastR.xoshiro256p() << endl; // returns same number sequence in [0, UINT64_MAX] interval
fastR.seed(); // new seed to 'chrono" to obtain different sequence
for(int i=0; i<10000; i++)
cout << fastR.xoshiro256p() << endl; // returns number in [0, UINT64_MAX] interval
*classes fastXS32s and fastXS64s don't have seed() function: they have/are only static members.
For more details look at the source file: it's well documented.
<p> <br></p>Where it is used
Classes and functions are currently used
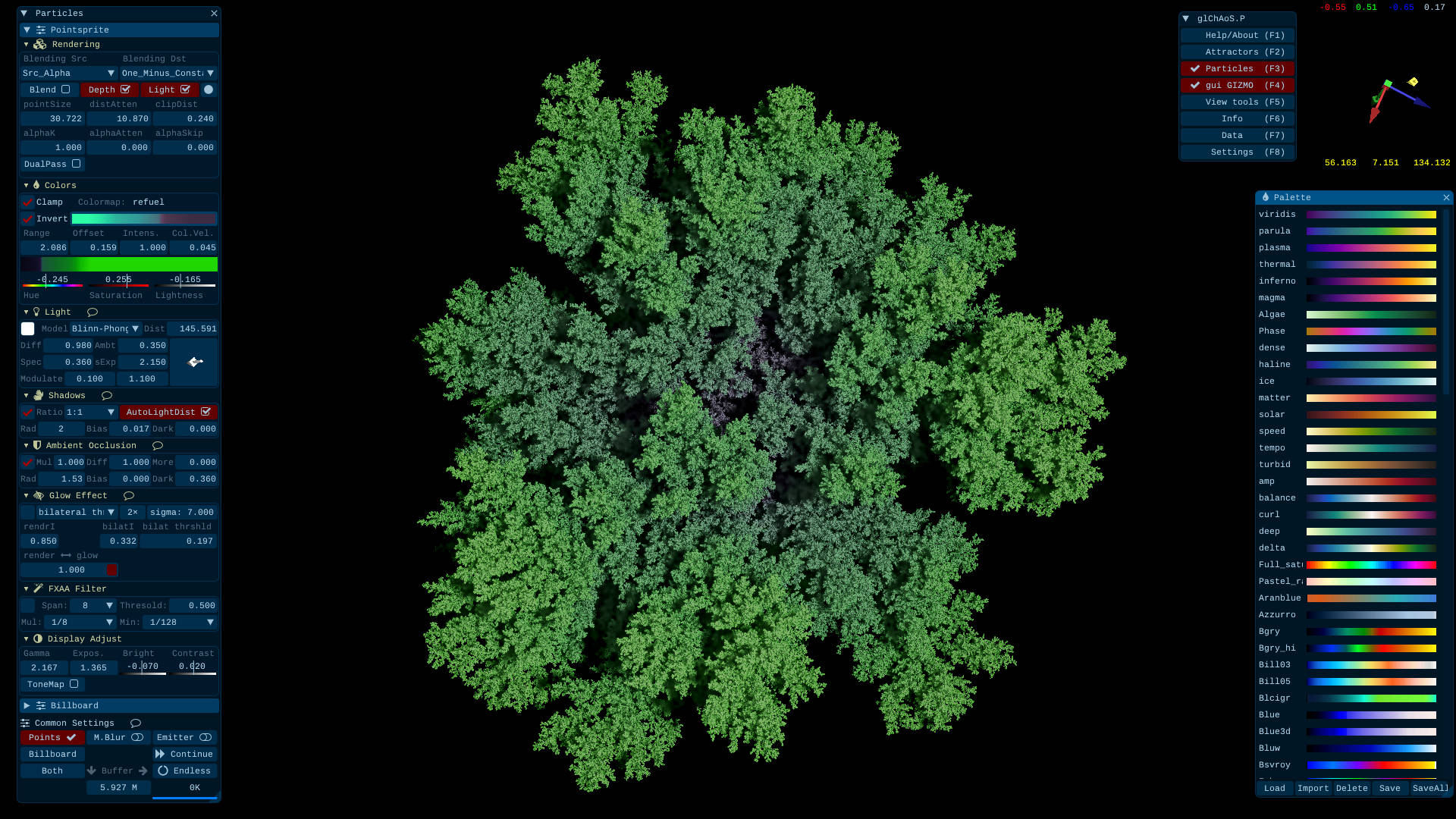
- glChAoS.P / wglChAoS.P Realtime 3D GPUs Strange Attractors and Hypercomplex Fractals scout
| Hypercomplex fractals with stochastic IIM <br>(Inverse Iteration Method) algorithm | DLA 3D (Diffusion Limited Aggregation) algorithm |
|---|---|
 |  |
- DLAf-optimized fast DLA (Diffusion Limited Aggregation) 2D/3D
Distribution Test
All functions are tested, below the distribution test in a cube with [-1.0, 1.0] side.
Live WebGL 2 / WebAssemly ==> fastPRNG distribution test
*Only FireFox and Chromium based web-browsers (Chrome / Opera / new Edge / etc.) are supported
| 30M dots/spheres cube | 30M dots/spheres cube <br> with clipping planes | 3 thin boards<br>from 30M dots cube |
|---|---|---|
| | |
| thin board<br>from a 10M dots cube | 2.5M dots/spheres<br> with clipping planes | 3 thin boards<br>from 5M dots cube |
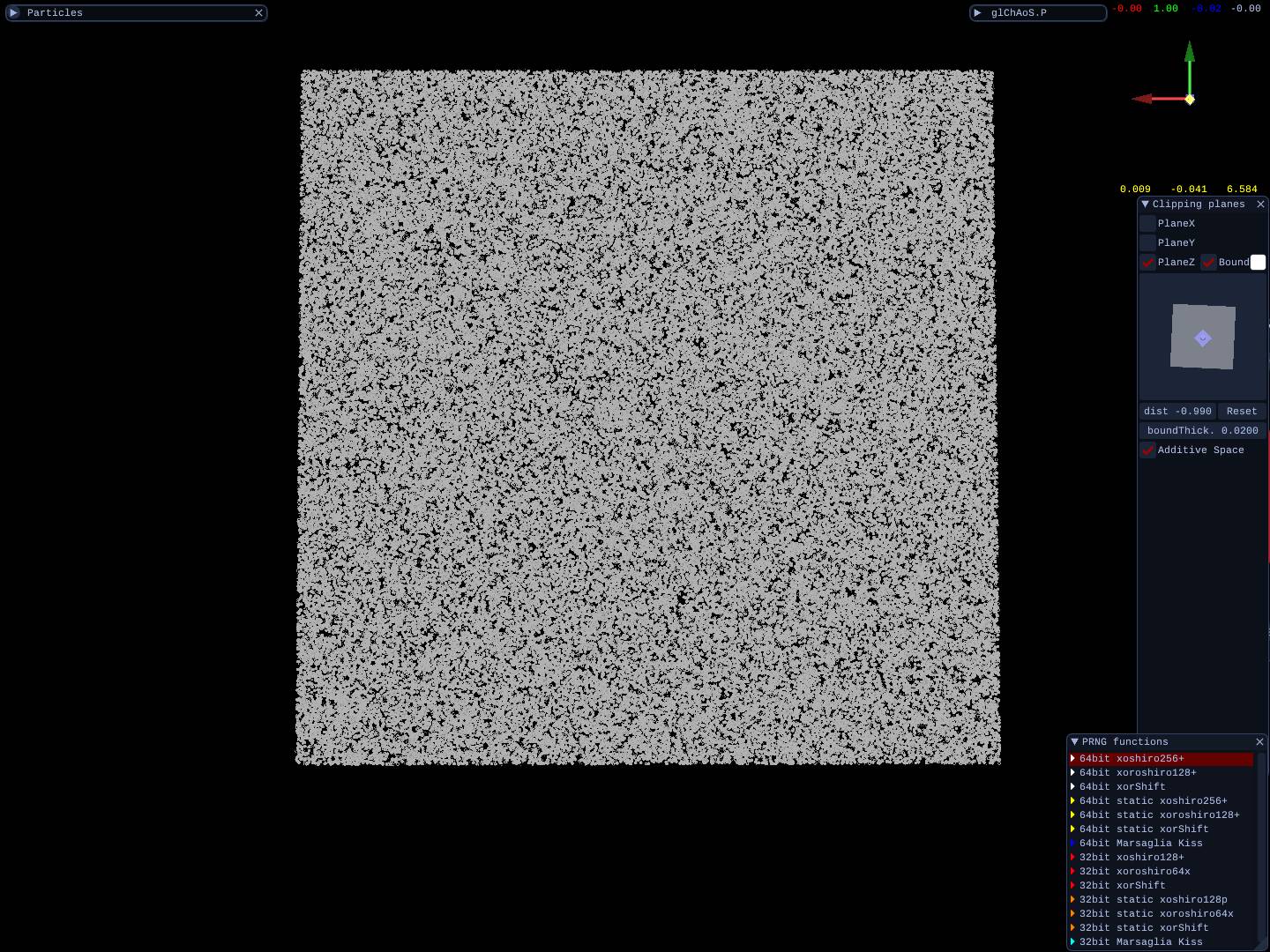 |  | 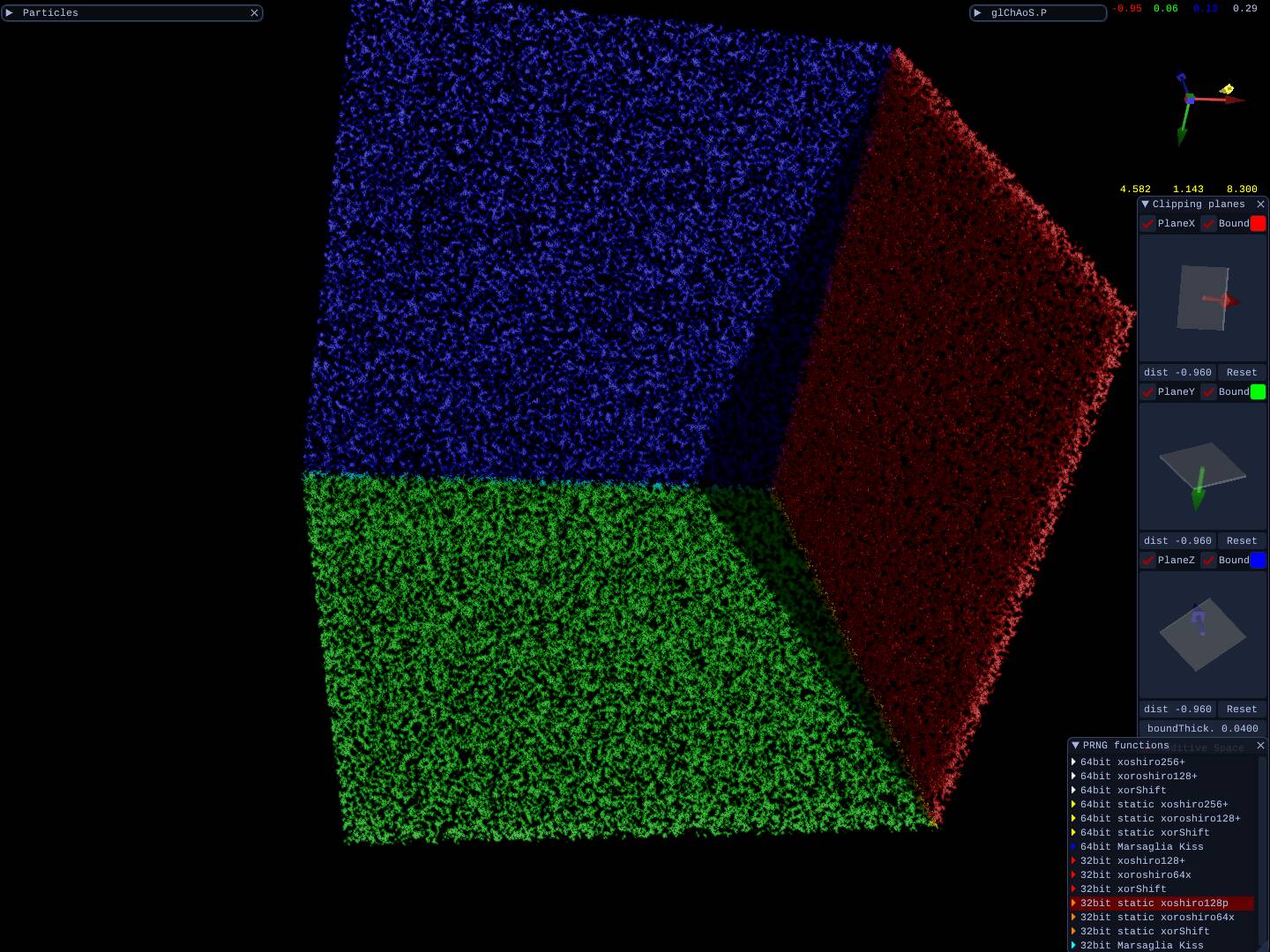 |
*It's builded on the rendering particles engine of glChAoS.P / wglChAoS.P
*N.B. it's a distribution test, NOT a speed/benchmark test, since the rendering time/calculus is preeminent
Using distribution live WebGL test
The JavaScript / WebGL version is slower of Desktop one, so the test starts with 2.5M of particles, and a pre-allocated maxbuffer of 15M (for slow / low memory GPUs)
Particles panel
A) Start / Stop particles emitter
B) Continue / FullStop: continue endless (circular buffer) / stop when buffer is full
C) Endless / Restart: rewrite circular buffer / restart deleting all circular buffer
D) Set circular buffer size (drag with mouse)
from .01M (10'000) to maxbuffer (default 15M pre-allocated) particles
*You can resize pre-allocated buffer changing the URL value of maxbuffer (in your browser address box)
(e.g. maxbuffer=30 pre allocate a 30M particles memory buffer)
Desktop
If you want use the desktop version (available for Windows / Linux / MacOS), please download glChAoS.P / wglChAoS.P and build it with -DGLCHAOSP_TEST_RANDOM_DISTRIBUTION or enable the #define GLCHAOSP_TEST_RANDOM_DISTRIBUTION in attractorsBase.h file