Awesome
CO-MOT: Bridging the Gap Between End-to-end and Non-End-to-end Multi-Object Tracking
<!-- [](https://paperswithcode.com/sota/multi-object-tracking-on-dancetrack?p=motrv2-bootstrapping-end-to-end-multi-object) [](https://paperswithcode.com/sota/multiple-object-tracking-on-bdd100k?p=motrv2-bootstrapping-end-to-end-multi-object) -->This repository is an official implementation of CO-MOT.
TO DO
- add DINO backbone
Introduction
Bridging the Gap Between End-to-end and Non-End-to-end Multi-Object Tracking.
<!-- 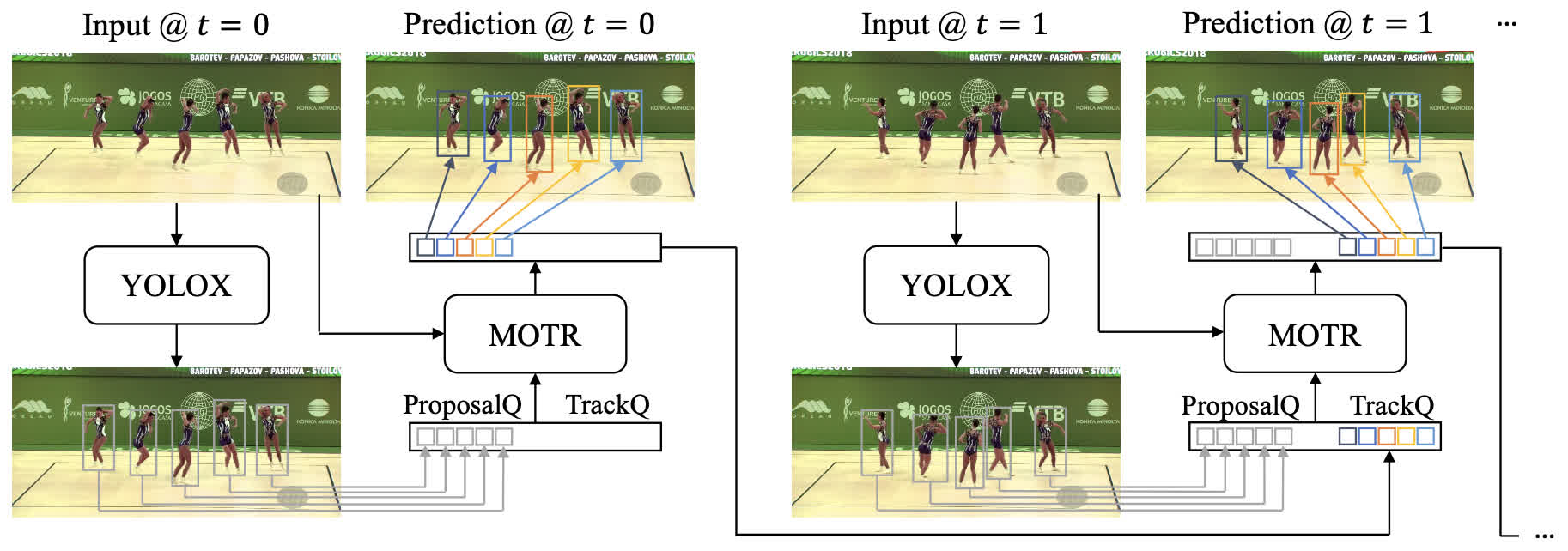 -->Abstract. Existing end-to-end Multi-Object Tracking (e2e-MOT) methods have not surpassed non-end-to-end tracking-by-detection methods. One potential reason is its label assignment strategy during training that consistently binds the tracked objects with tracking queries and then assigns the few newborns to detection queries. With one-to-one bipartite matching, such an assignment will yield unbalanced training, i.e., scarce positive samples for detection queries, especially for an enclosed scene, as the majority of the newborns come on stage at the beginning of videos. Thus, e2e-MOT will be easier to yield a tracking terminal without renewal or re-initialization, compared to other tracking-by-detection methods. To alleviate this problem, we present Co-MOT, a simple and effective method to facilitate e2e-MOT by a novel coopetition label assignment with a shadow concept. Specifically, we add tracked objects to the matching targets for detection queries when performing the label assignment for training the intermediate decoders. For query initialization, we expand each query by a set of shadow counterparts with limited disturbance to itself. With extensive ablations, Co-MOT achieves superior performance without extra costs, e.g., 69.4% HOTA on DanceTrack and 52.8% TETA on BDD100K. Impressively, Co-MOT only requires 38% FLOPs of MOTRv2 to attain a similar performance, resulting in the 1.4× faster inference speed.
News
- 2023.7.25 Release weight of BDD100K, MOT17
- 2023.6.28 Using our method, we achieved \bref{second} place in CVSports during CVPR2023, HOTA(69.54) SoccerNet.
- 2023.5.31 our code is merge into detrex.
- 2023.5.24 We release a our code and paper
Main Results
DanceTrack
| HOTA | DetA | AssA | MOTA | IDF1 | URL |
|---|---|---|---|---|---|
| 69.9 | 82.1 | 58.9 | 91.2 | 71.9 | model |
BDD100K
| TETA | LocA | AssocA | ClsA | URL |
|---|---|---|---|---|
| 52.8 | 38.7 | 56.2 | 63.6 | model |
MOT17
| HOTA | DetA | AssA | MOTA | IDF1 | URL |
|---|---|---|---|---|---|
| 60.1 | 59.5 | 60.6 | 72.6 | 72.7 | model |
Installation
The codebase is built on top of Deformable DETR and MOTR.
Requirements
-
Install pytorch using conda (optional)
conda create -n comot python=3.7 conda activate comot conda install pytorch=1.8.1 torchvision=0.9.1 cudatoolkit=10.2 -c pytorch -
Other requirements
pip install -r requirements.txt -
Build MultiScaleDeformableAttention
cd ./models/ops sh ./make.sh
Usage
Dataset preparation
- Please download DanceTrack and CrowdHuman and unzip them as follows:
/data/Dataset/mot
├── crowdhuman
│ ├── annotation_train.odgt
│ ├── annotation_trainval.odgt
│ ├── annotation_val.odgt
│ └── Images
├── DanceTrack
│ ├── test
│ ├── train
│ └── val
You may use the following command for generating crowdhuman trainval annotation:
cat annotation_train.odgt annotation_val.odgt > annotation_trainval.odgt
Training
You may download the coco pretrained weight from Deformable DETR (+ iterative bounding box refinement), and modify the --pretrained argument to the path of the weight. Then training MOTR on 8 GPUs as following:
./tools/train.sh configs/motrv2ch_uni5cost3ggoon.args
Inference on DanceTrack Test Set
# run a simple inference on our pretrained weights
./tools/simple_inference.sh configs/motrv2ch_uni5cost3ggoon.args ./motrv2_dancetrack.pth
# Or evaluate an experiment run
# ./tools/eval.sh exps/motrv2/run1
# then zip the results
zip motrv2.zip tracker/ -r