Awesome
OpenOmni Framework
Multimodal Open Source Framework for Conversational Agents Research and Development.
![]()
![]()
News
- 2024-11-15: OpenOmni Framework has been awarded the Best Demo Paper Award at EMNLP 2024. Award
- 2024-10-06: OpenOmni Framework is accepted by EMNLP 2024 Demo Track. Paper
- Motivation
- Video Demonstration
- Approaches
- Our System Design
- Benchmark Examples
- Deployment Options
- Tutorial
Motivation
The development of Multimodal Large Language Models (LLMs) is opening new frontiers in conversational agent research and applications. Multimodal end-to-end conversational agents represents a significant advancement in our pursuit of general AI. This progress, however, is not without its challenges. Balancing cost, accuracy, and latency remains a difficult task.
<div style="text-align: center;"> <img src="./docs/images/Triangle.jpg" alt="OpenOmni" width="300"/> </div>GPT-4 has demonstrated the capability of a fully end-to-end multimodal model to handle complex multimodal inputs, including audio and images, and generate coherent and contextually appropriate responses in a timely manner. Compared to traditional approaches such as speech-to-text, text generation, and text-to-speech, which suffer from latency issues that hinder their real-world applicability, GPT-4 has shown the potential to overcome these challenges. This showcases the potential of advanced AI models to navigate the rough path towards a bright future in conversational agents.
Despite these advancements, achieving the right balance between cost, accuracy, and latency is a significant hurdle. This difficulty is the motivation behind our project. We aim to establish an open-source framework that allows researchers to easily test their contributions and collaborate effectively. By doing so, we hope to facilitate the research and development process, accelerating the journey towards more efficient and capable multimodal conversational Agent systems.
Video Demonstration
Approaches
- Traditional approach is to Divide and Conquer, however it suffers from the latency issue
- GPT-4o is End-to-End model, which is different from the traditional approach, and overcome the latency issue. However, it is hard to implement for wider community.
- Other approaches is Hybrid Approach, an end to end voice model, which take audio and texts as input, and generate audio as output. Video modality input can be converted to text, and then feed into the model.
Traditional conversational AI

The whole pipeline divided into several components, mainly including:
- Speech2Text
- Information Retrieval (Text based or Video based)
- Text Generation
- Text2Speech
Before the era of LLM, Speech2Text and Text2Speech tasks are the most successful ones, delivering quite a few successful products. However, generate in-context response is a challenging task, which is a bottleneck for the whole pipeline, which is the Accuracy issue. Development of LLMs solves this problem directly.
However, it is still one more problem, which is the Latency issue, before it can really impact the real world seriously.
OpenAI GPT-4o

Demonstration from OpenAI indicates that they have achieved acceptable Latency performance, which is around 250ms. At the same time, the Accuracy is also impressive, according to their released benchmark: GPT-4o Benchmark.
However, we noticed that there is a cable connected to the iPhone when they are doing the demonstration, and it is described to maintain stable and high speed internet connection. Which means, reasonable latency is achievable, however, not yet scalable to the real world. The delay of public release of GPT-4o with audio and video ability proves this point to some extent. Our testing with current GPT-4o endpoints indicates even the fastest pipeline combination with OpenAI API ( Whisper,GPT-3.5,OpenAI TTS) still have 5-8 seconds latency.
Hybrid Approach

Unlike GPT-4o, with audio, video, or/and text as input, which is challenging to implement, some researchers are exploring a hybrid approach, which is to take audio and/or text as input, and generate audio and/or text as output.
Moshi is one of the examples. Images and Videos normally are very large, and require a lot of computation power to process, this approaches can overcome this issue. Another advantage of this is that without take the video as input, it avoids the privacy issue, act not like a "Big Brother is Watch you", potentially is more acceptable by the public.
Summary
The research focus for multimodal conversational agents is shifting towards end-to-end models, however, it is a **money ** game. To achieve that, you will need intelligent people (which we have in research community), data, and money. Data and money is not evenly distributed within the research community, which makes the wider research community hard to catch up with the cutting edge research.
Sadly to say that, but reality is the rest research community without enough data and money can work towards the direction: adopt and applying conversational agents the into the real world, and make it more accessible to the public. Contributing to the bigger picture as a small piece of the puzzle.
This leads to the development and goal of OpenOmni Framework Project.
- Collaborative Efforts: Crowd efforts where everyone focuses on advancing their own part without reinventing the wheel.
- High Agility: A process that allows people to easily test their models, understand real application issues, and improve them.
- Gathering Data: More data to advance system development, especially for complex conversational scenarios. This includes understanding who is talking, the context, and the emotion, which is lacking in current datasets.
We want to:
- Allows people to easily test their models, whether end-to-end or single components within the pipeline.
- Can be easily deployed, enabling researchers to collect the data they need with minimal effort for adaptation.
Our ultimate goal is to:
- Develop an open-source, end-to-end conversational agents robot that match the capabilities of OpenAI's GPT-4o.
- Enable easy data collection for advancing the development of end-to-end conversational agents.
- Inspire and foster the development of innovative conversational agent applications and products.
System Design
Requirements
What the functions we need from the system perspective:
- Data Collection: Video and audio inputs are collected from hardware devices.
- Data Transfer: Data is sent to the API for downstream processing.
- Data Processing: The API uses Agents and ML models to process the data, generate responses.
- Reaction: The client side is notified to play the speech.
There are two key metrics we are focusing on:
- Model Latency: The time it takes for the model to generate a response.
- Model Accuracy: Whether the model generates the in-context response or accurate response.
Which will allow to react to user's query in a timely manner, and provide the most in-context response.
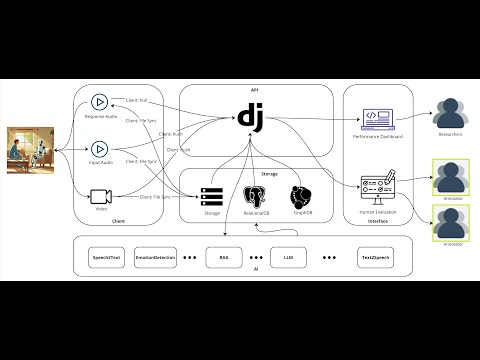
System Architecture

Main Components
So as you can see from the system architecture, we have three main components: Client, API, and AI.
Client will be in charge of data acquisition, and data presentation. Which means the video and audio data will be collected from the client side, and the speech generated by the Agent will be played by the client side.
API will be the orchestrator, which will manage the models, and provide the API interface for the Client/Agent module to access. It also provides the access and CURD to the data sources (Neo4j, PostgreSQL and Hard Disk). It also includes an interface for end users (Researchers and Annotators) to interact with the system.
Agent module is seperated to make sure it can be scaled to use different computation resources, and easily to integrate new work in.
All modules are written in Python.
- Client side, Listener and Responder are two separate python package, which will allow the separate deployment of data acquisition and playing audio speech.
- API end is built with Django, and have a customised admin interface, which will allow the management of the data sources, and the models.
- Data side, we have Neo4j, PostgreSQL, and Hard Disk, which will allow the data to be stored in different places.
- Agent module is also a Python package.
Client
Detailed information can be found in Client.
The client side will mainly in charge of
- Data Acquisition
- Audio
- Video
- Data Transfer
- Transfer the data to storage places
- Data Presentation
- Play the speech
API
Detailed information can be found in API.
This is the Brain of the system, which will be in charge of:
- Knowledge Base
- Relational Database
- Graph Database
- Hard Disk
- Models Orchestration
- LLM
- GPT-4 API
- Self-developed models
- API Interface
- RESTful API
- Data Management with an Admin interface
- Annotation Interface for the annotators
- Benchmark report for the researchers
Agent
Detailed information can be found in Agent.
- Running the ML or Agent models
- Running the models which require intensive computation
- LLM models
- Text2Speech models
- Emotion Recognition models
- etc.
Benchmark Examples
We provided benchmarks for both latency and accuracy.
Latency
When we log the time within the pipeline, we will log both timestamp information for critical time points, and the time duration it takes to finish a specific task. In this way, we can generate a latency report for each component within the pipeline, and also operate whether the latency is caused by the data transfer or the model inference process, so that we can further optimize the system. With the timestamp information of the time point, we can easily retrieve the timeline of the process, with good observability, it will allow us to debug easily, or notice the potential issues.
We provide two report interface for the latency:
- Summary Report: Which will provide the average latency for each component within the pipeline (in seconds).

- Detail Report: Which will provide the detailed information round of conversation, timeline and overall latency (
in seconds).

You can configure the system to run the same datasets through different pipelines, and in the end evaluate the performance, do the comparison.
Accuracy
Accuracy probably is not the most correct name for it, as for the text generation task, you will want to see whether it is in-context, for text2speech task, you will want to check the emotion is proper or not. However, if we just use the general word to "Performance" to refer this, it will normally cause the confusion between the developers and researchers. So we stick to use this to refer to the model performance.
However, for most of the accuracy performance, it does not like the latency, the measurement is diverse for a task and between different tasks. For example, you will want to evaluate whether the generated text is in-context from the knowledge, reasoning, tone perspective. So we need more freedom here. And automatically to evaluate the tasks from these different perspectives is also a challenging and underexplored area.
So we decide to provide a customisable interface which will allow annotators to annotate the accuracy performance for the model under different measurement metrics. It can be evaluated by multiple annotators, and then the system will provide a summary report for the performance. You can also evaluate the overall performance for several rounds of conversation, and then generate a report for that.
We will show how to do this evaluation annotation in tutorial section.
You can track the evaluation process via our accuracy detail page, and then get a summary report after the evaluation annotation is done.
-
Summary Report: Which will provide the average accuracy for each component under each measurement metrics within the pipeline.




-
Detail Report: Which will provide the detailed information and progress for each round of conversation annotation


-
Multi-Turn Conversation: You can group several conversation into a muti-turn conversation, and then annotate the overall performance for that.

Deployment Options
Because the whole design is modular and decoupled, so you can use our system in several ways:
- Trial on Cloud: We deploy the API end on https://openomni.ai4wa.com
- You can use this as the API end
- Deploy the client side on your local machine to collect audio and video, and play the audio
- Deploy the Agent module on your local machine or anywhere with good computation power, can be a cloud server, HPC center, etc
- All in One Local Machine: You can deploy the whole system on your PC or laptop
- You can use the camera, microphone, and speaker on your laptop
- You can use the local storage to store the data, and get the data transfer process to be "None"
- You can use the computation power on your laptop to run the Agent models (Which sometimes not that good)
- Private Offline Network: You can deploy the whole system on a private network, different machines
- Camera, Microphone, and Speaker can be one different machine within the same network
- API will be running on another machine, which in charge of manage the whole system
- Agent module can be running on a high speciation machine, which in charge of running the Agent models, or a local high performance GPU cluster
- Your Cloud: This is similar to the Trial on Cloud, only difference is that you deploy the API end on your own cloud server, and you can have more control over the system.
Client side can be deployed to very cheap devices like Raspberry Pi with camera, microphone and speaker, like show in

We have detailed instruction about how to deploy the system in different ways in Deployment.
Citation
If you find this package useful, please consider citing our work:
@inproceedings{sun-etal-2024-openomni,
title = "{O}pen{O}mni: A Collaborative Open Source Tool for Building Future-Ready Multimodal Conversational Agents",
author = "Sun, Qiang and
Luo, Yuanyi and
Li, Sirui and
Zhang, Wenxiao and
Liu, Wei",
editor = "Hernandez Farias, Delia Irazu and
Hope, Tom and
Li, Manling",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.emnlp-demo.5",
pages = "46--52",
abstract = "Multimodal conversational agents are highly desirable because they offer natural and human-like interaction.However, there is a lack of comprehensive end-to-end solutions to support collaborative development and benchmarking.While proprietary systems like GPT-4o and Gemini demonstrating impressive integration of audio, video, and text with response times of 200-250ms, challenges remain in balancing latency, accuracy, cost, and data privacy.To better understand and quantify these issues, we developed \textbf{OpenOmni}, an open-source, end-to-end pipeline benchmarking tool that integrates advanced technologies such as Speech-to-Text, Emotion Detection, Retrieval Augmented Generation, Large Language Models, along with the ability to integrate customized models.OpenOmni supports local and cloud deployment, ensuring data privacy and supporting latency and accuracy benchmarking. This flexible framework allows researchers to customize the pipeline, focusing on real bottlenecks and facilitating rapid proof-of-concept development. OpenOmni can significantly enhance applications like indoor assistance for visually impaired individuals, advancing human-computer interaction.Our demonstration video is available https://www.youtube.com/watch?v=zaSiT3clWqY, demo is available via https://openomni.ai4wa.com, code is available via https://github.com/AI4WA/OpenOmniFramework.",
}